1 SegFormer SegFormer两个特点: 和其他基于transformer的分割模型不一样,Segformer是一种分层结构,能够输出多尺度的特征,并且不需要位置编码。 SegFormer不需要复杂的编码器,直接使用MLP来聚合多尺度的特征。 架构图: SegFormer会把图像分割成4×4的patch,用比较小的patch会对密集型预…
1 数据合成-Selective Tampering Synthesis 共包含copy-move、generation、erase三种篡改方式 提取bounding box内的text mask: 将box扩大到原本的1.5倍,确保box能完全框死整个字符(后续需要进行形态学操作和根据轮廓填充mask,如果不能完全框死,会导致效果不好) 对box…
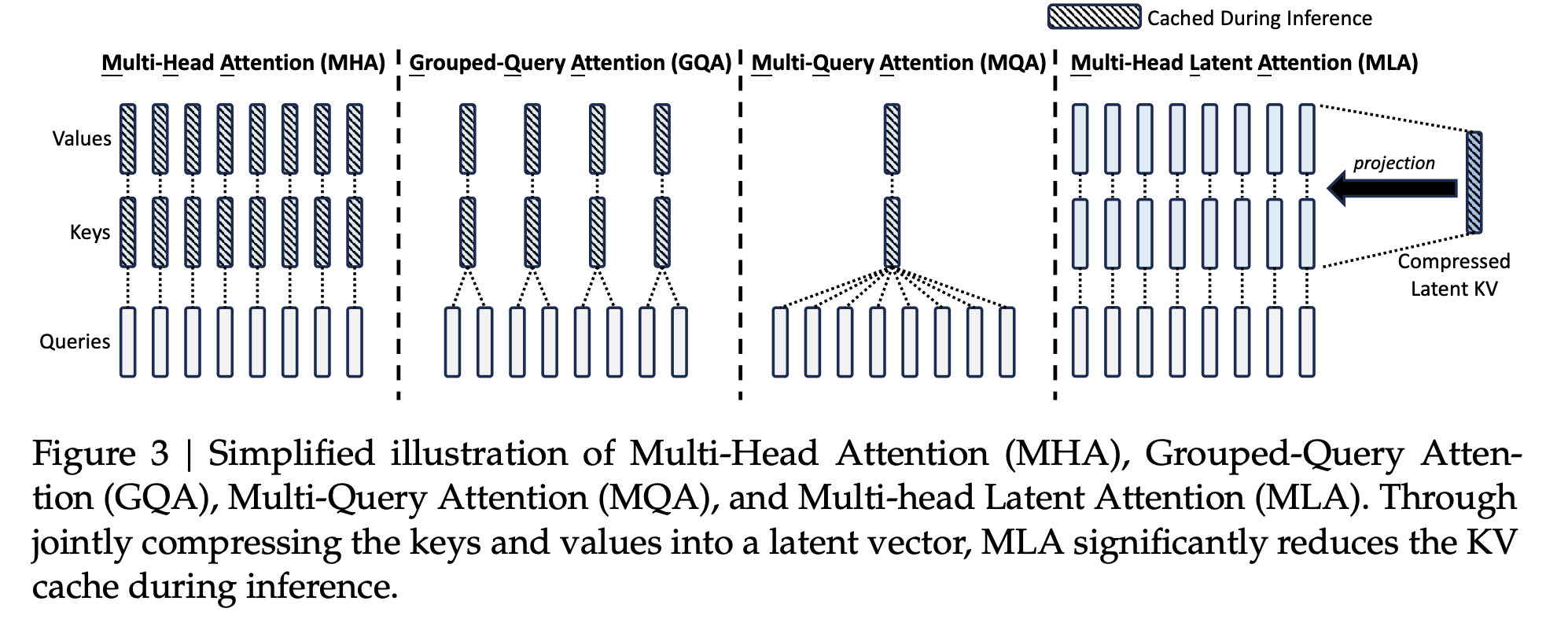
这一篇,我会按照KV Cache的原理、LLM推理阶段KV Cache显存占用分析以及如何优化推理阶段KV Cache的显存占用的顺序去讲解。 参考: deepseek技术解读(1)-彻底理解MLA(Multi-Head Latent Attention) LLM 推理优化之 KV Cache 1 KV Cache 1.1 不使用KV Cache …
1 贝叶斯定理和全概率公式 1.1 全概率公式 假设\(A_1,A_2,\ldots,A_n\)是一个互斥且完备的划分(也就是样本空间被这些事件完全划分,没有重叠),那么有: \[P(B)=\sum_{i=1}^nP(B|A_i)\cdot P(A_i)\] 也就是把“B 发生”的所有路径(通过不同的\(A_i\)发生)都考虑进去,再加权求和。 1…
1 动机&基本实现方法 大多数伪装目标检测的方法,大多都致力于提高前景像素的置信度,然而,从另一个角度看,通过抑制背景像素,来让伪装目标浮现出来可能会是一个更有效的方法,并且,背景像素相较于前景像素更容易发现。 因此从背景抑制出发,设计了DSM,将特征分成了高频流和低频流分别处理,使用ORI,对低频进行抑制,对高频进行增强。处理完的特征通过…
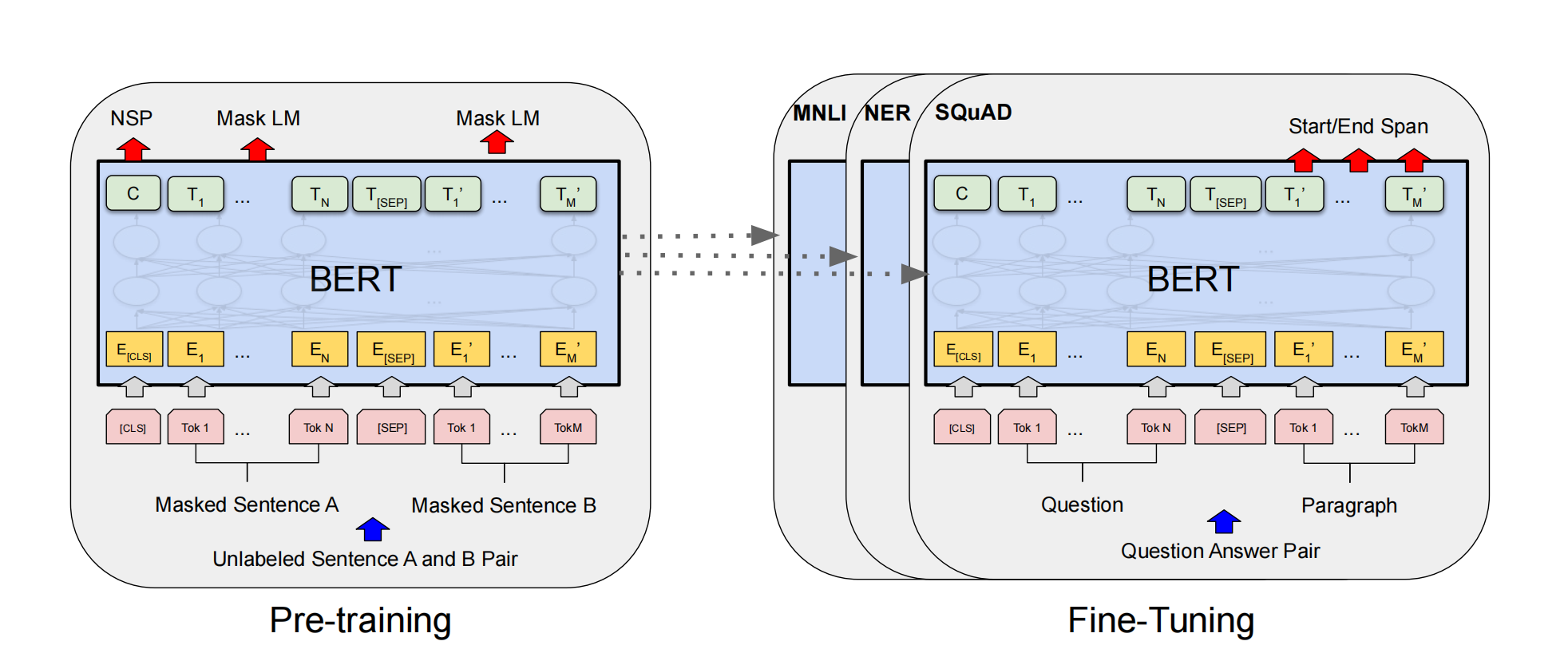
1 Introduction&Contribution 之前的模型比如GPT使用的是单向注意力机制,作者认为这种架构在sentence-level的task上finetuning是次优的,因为这个任务需要从双向建模上下文。 作者提出两种预训练任务,这两种预训练任务是同时进行的: masked language modeling:将句子中部分…
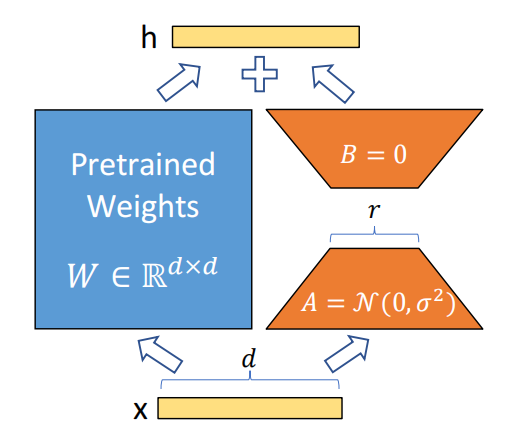
1 参数高效微调 以语言模型为例子,微调一个预训练模型权重\(\Phi_0\)到\(\Phi_0+\Delta\Phi\)(\(\Delta\)就是参数更新量),通过一下LM objective去训练: \[\max_\Phi\sum_{(x,y)\in\mathcal{Z}}\sum_{t=1}^{|y|}\log\left(P_\Phi(y_t…
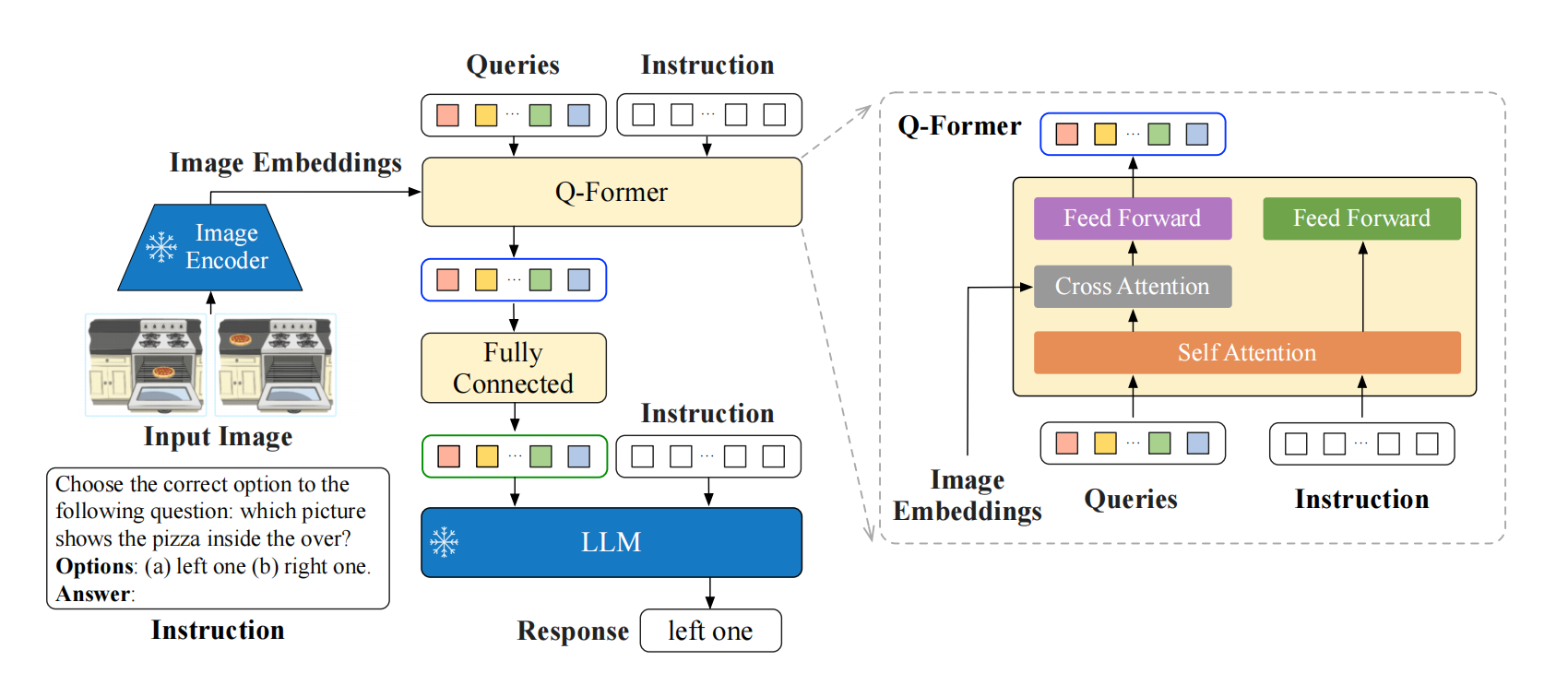
1 Why instructBLIP? 视觉语言任务通常更加多样,更加复杂,因为他有视觉模态的输入,而视觉模态的输入可能来自不同的域。所以说,一个统一的模型能泛化到不同的任务,泛化到一些没见过的数据,是很重要的。之前的工作大致分为两类,一类是多任务学习,把不同的视觉语言任务变成相同的输入输出格式,进行训练,但是发现它们在没见过的任务和数据集上表现比…
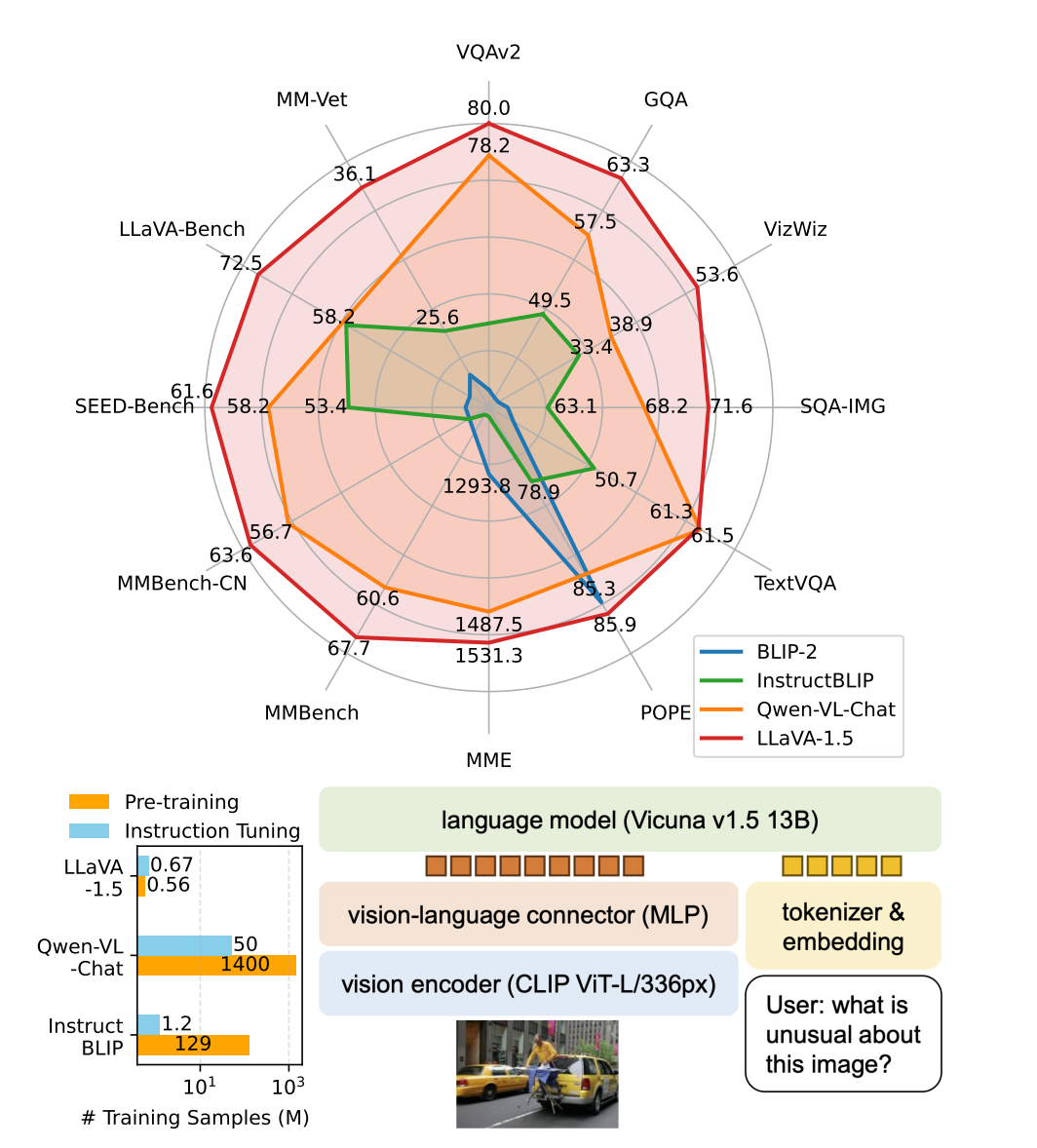
1 论文的结论&贡献 模型层面:原先把视觉投影到语言,使用的是Linear projection,它已经很强大,替换为MLP之后,会发现性能会有进一步的提升。 输入图片:使用更大的分辨率,会让模型看清更多细节,提高性能。使用更强的 CLIP-ViT-L-336px 视觉编码器替换原先的 CLIP-ViT-L/14 优化简单回答性能:将面向学…
现在大模型一般训练过程是pretrain->SFT->RLHF,现在大部分模型都是decoder-only,这里讲解也都是以decoder-only为例子。 第一阶段是pretrain的目的就是语言建模,让模型学会语言模式和知识,学会语言本身,它通常会使用规模很大的数据集,来自大规模网络文本(如 Wikipedia、Books、Comm…