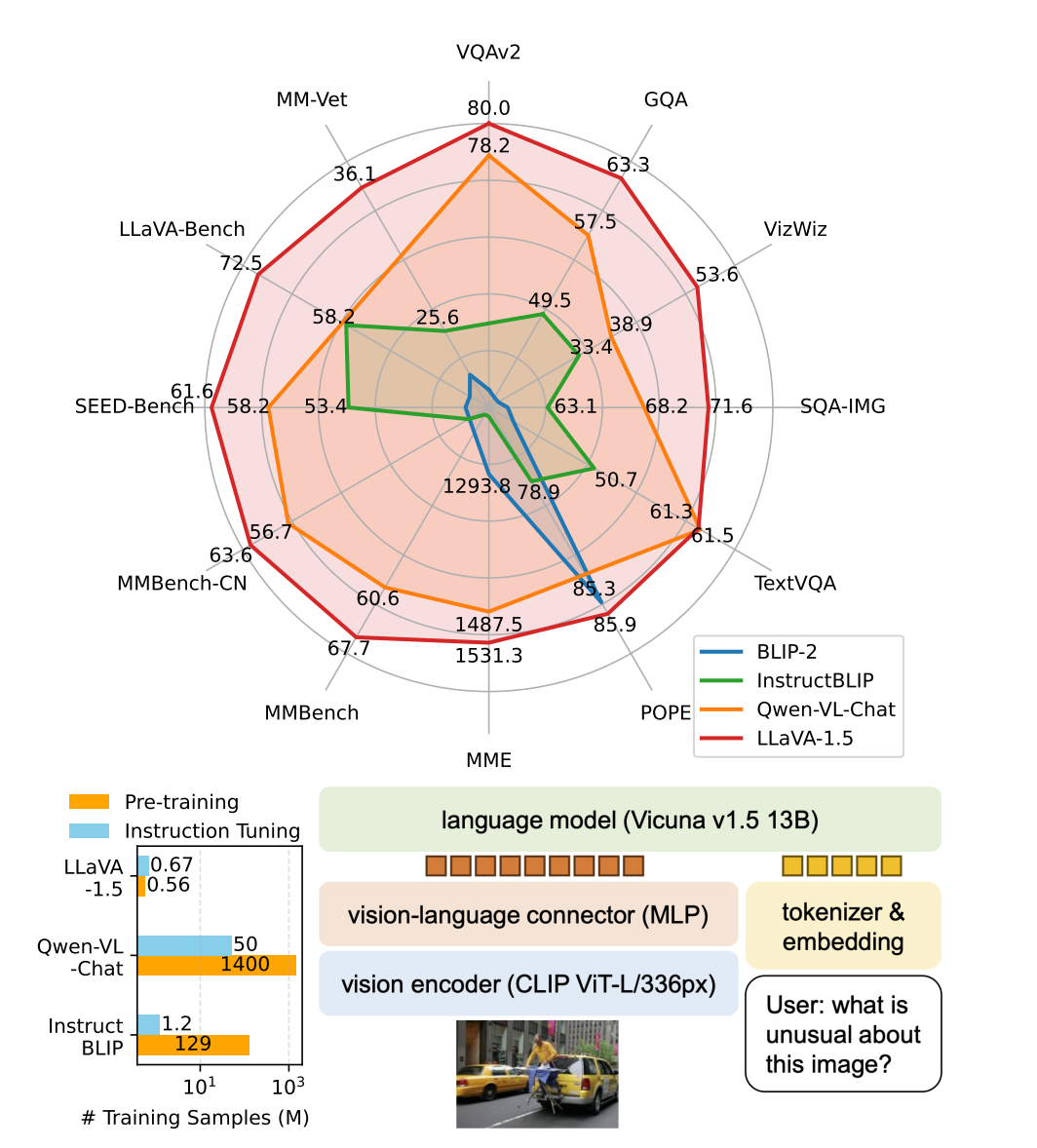
1 论文的结论&贡献
- 模型层面:原先把视觉投影到语言,使用的是Linear projection,它已经很强大,替换为MLP之后,会发现性能会有进一步的提升。
- 输入图片:使用更大的分辨率,会让模型看清更多细节,提高性能。使用更强的 CLIP-ViT-L-336px 视觉编码器替换原先的 CLIP-ViT-L/14
- 优化简单回答性能:将面向学术任务的 VQA-v2 数据集,纳入LLaVA instruction tuning的训练范畴,并且使用Response Format Prompting来优化VQA-v2的学习。这两者明显提升了LLaVA在短回答上的性能。(LLaVA之前在学术benchmark上,尤其要求简单回答的问题上,是短板)
- 分析图像分辨率、数据规模以及语言模型大小对性能的影响,揭示了模型的组合能力。
2 Methods & Architecture
2.1 Architecture
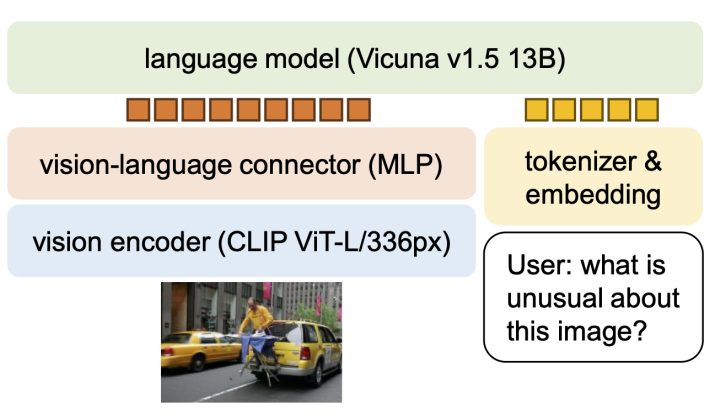
- 使用 CLIP-ViT-L-336px 视觉编码器替换原先的 CLIP-ViT-L/14
- 将原先的一层线性层替换为 MLP 层(两层线性层)
2.2 Additional Training on VQA-v2 and other Academic task oriented data
instructBLIP不太能平衡长回答和简短回答,有的时候,让其详细描述图片,它只会打yes和no,如下图所示:

作者认为有如下几个原因:
- 回答格式非常模糊,instructBLIP使用的是Q: {Question} A: {Answer},并没有详细说明想要的输出格式,会导致模型偏向于简短回答,即便是对于自然语言的对话。
- instructBLIP没有finetune LLM,其只finetune了Q-Former。也就是说,回答是长是短,完全由q-former提取的视觉特征来决定,显然,q-former并没有这个能力。
因此,作者为VQA-v2设计了response format,即在question之后加入:Answer the question using a single word or phrase。作者发现LLM就可以根据用户指示输出指定长度的回答了。
除了在VQA-v2上训练,还在一些Academic task oriented data进行训练。为了提升VQA、OCR性能,作者在OKVQA、A-OKVQA、OCRVQA、TextCaps上进行训练。作者还在visual geneme和RefCOCO上进一步训练,提升region level perception。
2.3 Scaling in image resolution and LLM model size
2.3.1 Scaling in image resolution
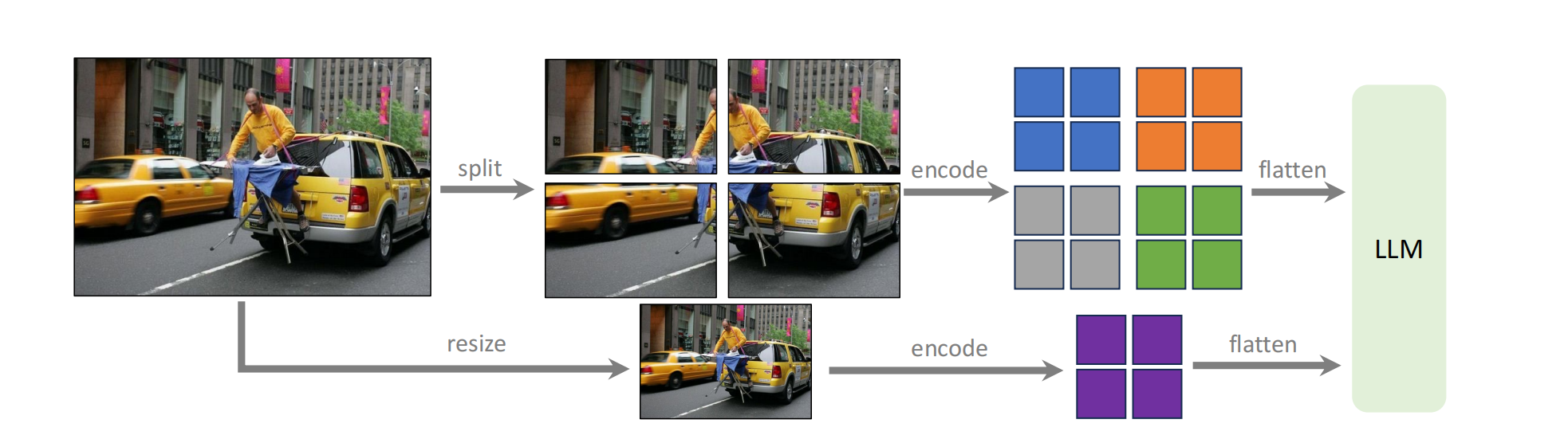
作者使用CLIP-ViT-L-336px,将224✖️224提升为336✖️336,发现性能有提升。并且又囊括了一个数据集:GQA,提供额外的视觉知识。但是作者并没有止步于此,为了能让模型适应任意尺寸的输入,作者采用AnyRes策略,具体步骤如下:
- 将高分辨率的图像分割成块,块的大小取决于视觉编码器能够处理的大小(例如 CLIP-ViT-L/14 可以处理的分辨率为 224*224)。视觉编码器单独处理每一块。
- 同时,将高分辨率的图像 resize 成视觉编码器能够处理的大小并使用视觉编码器进行编码,提供全局上下文,减少分割编码合并操作的伪影。
- 将上面两步的结果拼接在一起作为视觉特征
2.3.2 Scaling in LLM model size
当把模型scale up to 13B的时候,模型的性能又有提升。上文所说的所有额外添加的训练结果如下图所示:
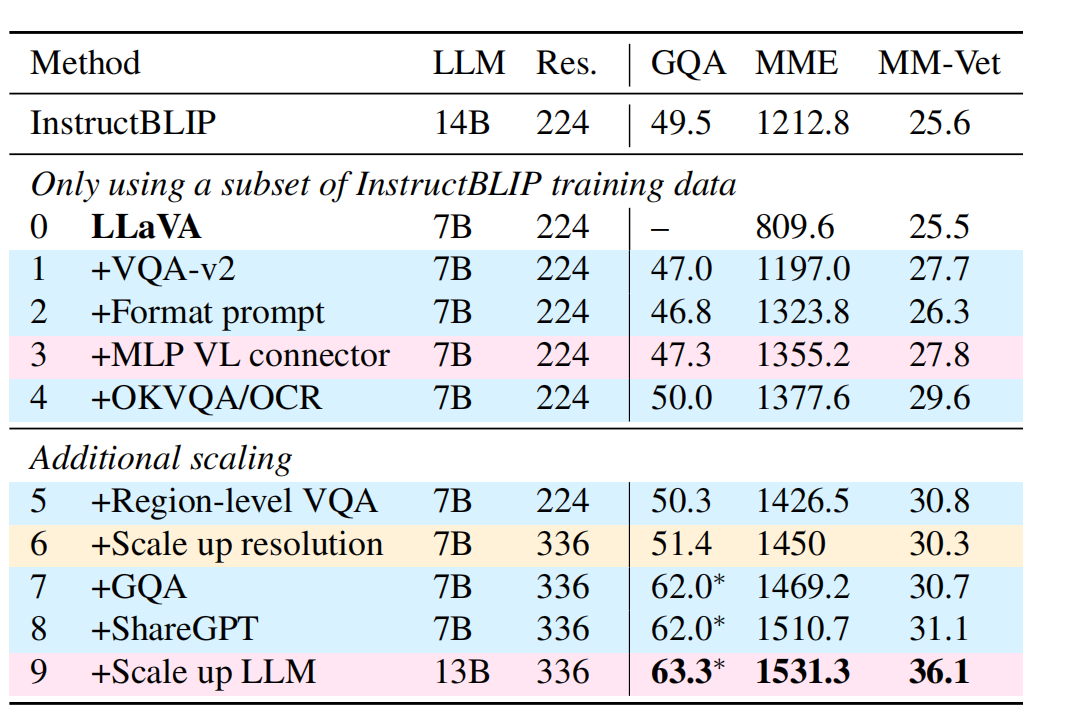
作者把最后两行(第八行、第九行)的训练模型命名为LLaVA-1.5
3 Open problem in LLM
Data Efficiency
作者发现,只用50%的数据集训练,模型仍然会保持超过98%的性能。当数据集规模葱50%变为30%,模型的性能还能保持稳定。这表明在数据集上还有很大的压缩空间,未来可以有更好的数据集压缩策略来提升训练效率。
Hallucination in LMMs
现在我们都把模型的幻觉问题归因于数据集中的错误。但是,作者把图像分辨率提升为448✖️448的时候,幻觉问题明显减弱,说明LLMs对于训练数据中的错误有一定鲁棒性。
除此之外,作者总结出:当输入分辨率不足以模型分辨出训练数据中的所有细节,或者训练数据的中那些粒度足够小,超过模型理解能力的数据过多的时候,会导致幻觉问题。
Compositional Capability
作者发现,当模型为了提升某种能力在某个数据集上训练的时候,模型的其他能力也有可能会提升。比如,在ShareGPT上进行训练,可以提升模型的多语种能力,并且模型在视觉对话中还能够提供更长、更详细的回答;在academic-task-oriented数据集上训练,会提升模型在视觉对话中的visual groundness。也就是说,可以这么理解:在一个数据集上训练,在其他数据集上也会涨点,并且模型的各种综合能力也会提升。