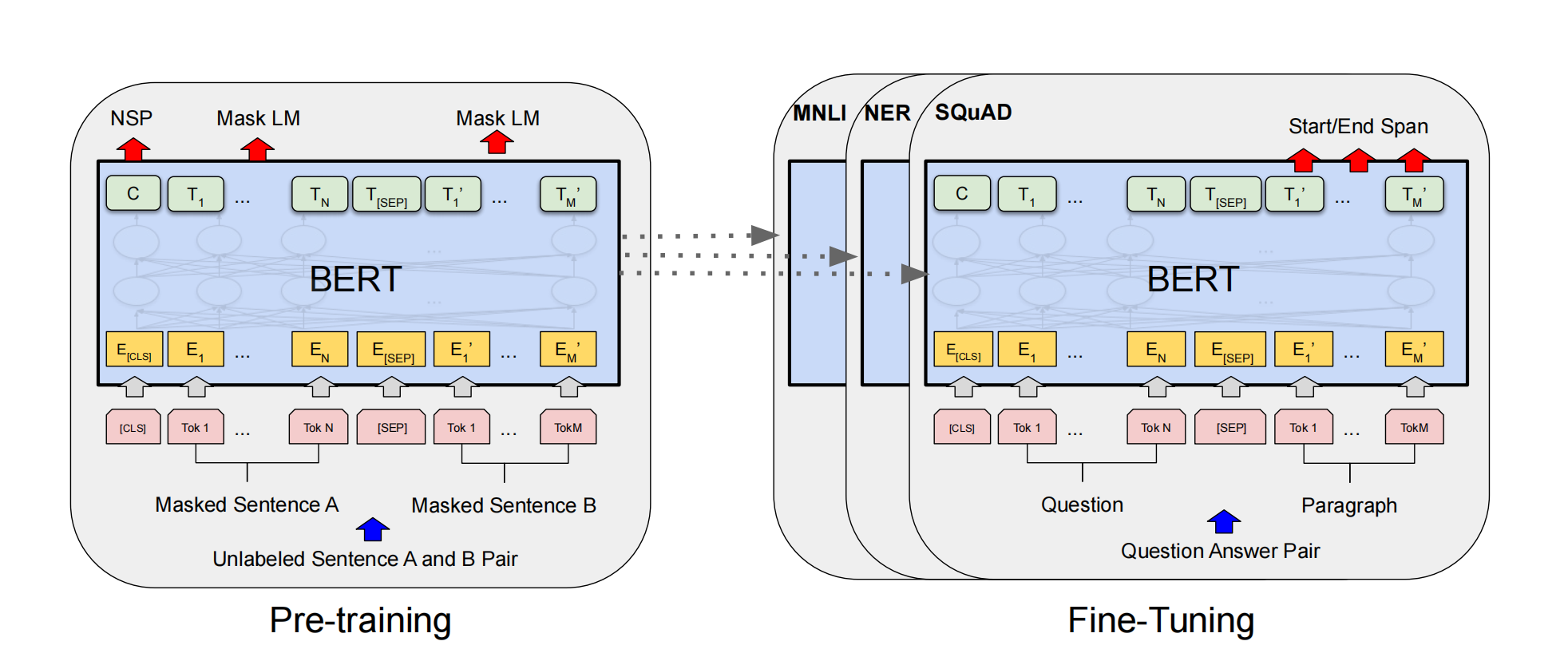
1 Introduction&Contribution
之前的模型比如GPT使用的是单向注意力机制,作者认为这种架构在sentence-level的task上finetuning是次优的,因为这个任务需要从双向建模上下文。
作者提出两种预训练任务,这两种预训练任务是同时进行的:
- masked language modeling:将句子中部分单词用[mask]替代,然后预测它们。
- Next Sentence Prediction:输入两个句子,使用[CLS]来判断第二个句子是不是第一个句子的下一句。
2 Methods
2.1 Input/Output Representations
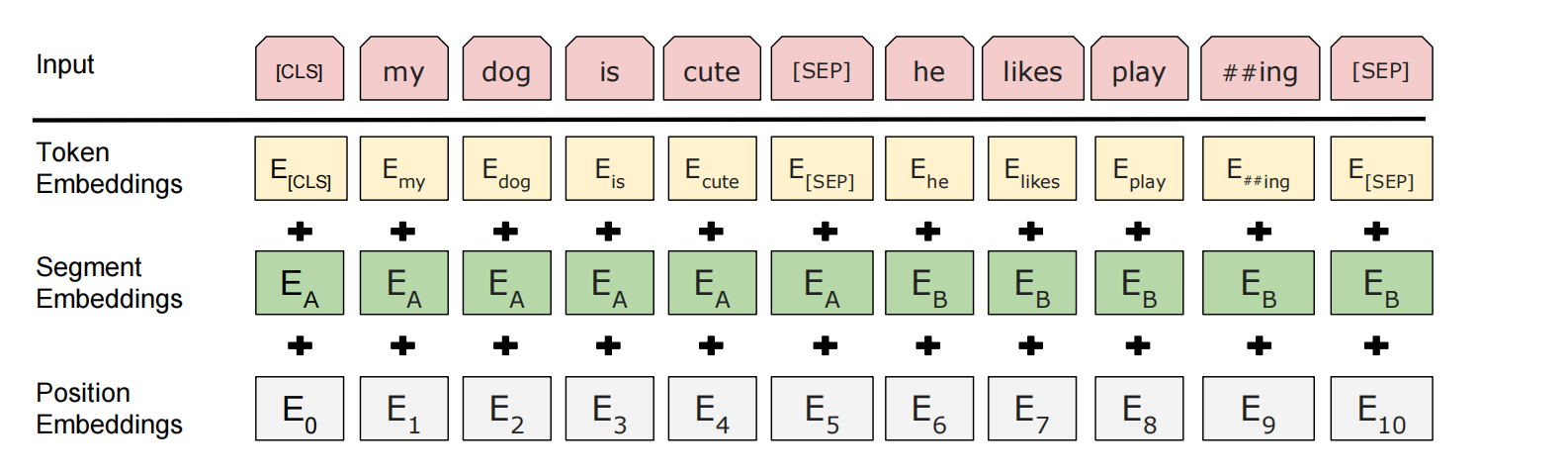
BERT的输入是两个masked的句子,并且两个pretraining task是并行同时进行的。对于每一个token来说,它的表征是由token embedding、segment embedding、position embedding相加得来。,其中,segment embedding一共有两种,表示该token属于两个句子中的哪一个。[CLS]表征两个sentence的的聚合表征。
2.2 Pretraining Stage
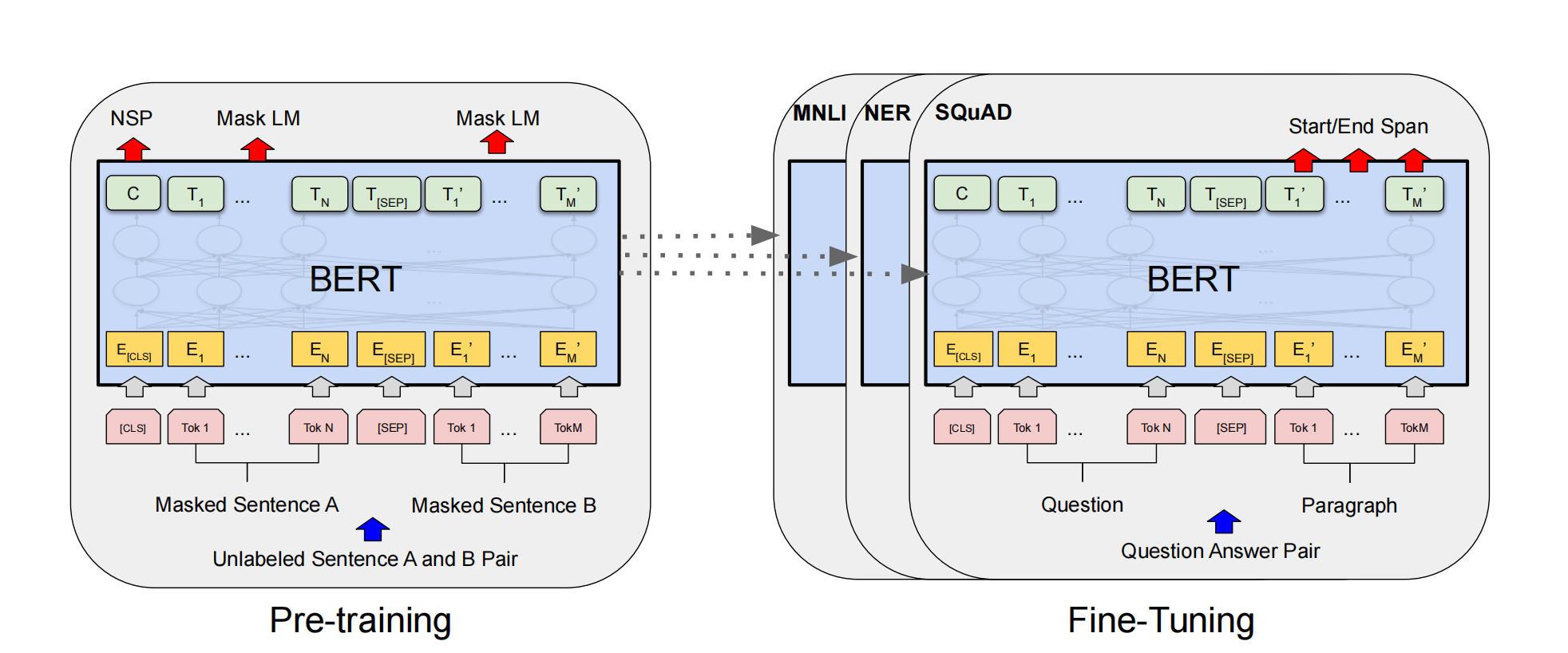
2.2.1 Masked LM
作者将每个句子随机masked掉15%,然后在这些token上进行预测本应该是哪个词,使用交叉熵计算loss。masked掉的token并不是全由[mask]替代,因为[mask]在finetune时并不会出现,会导致和下游任务不匹配。因此作者将这15%的token用以下三种替代:
- 80%用[mask]
- 10%用random token
- 剩下10%保持不变。
2.2.2 Next Sentence Prediction (NSP)
许多下游任务都需要理解两个句子之间的关系,比如Question-Answering,它输入question和passage,让你预测答案在passage的起始和结束位置。
BERT通过NSP来提高模型的句间理解能力。NSP时一个二分类问题,它的数据集很容易构造,从语料库里选出两个句子A、B,50%情况下,B是A的下一句,50%的情况下不是,通过CLS token对两个句子是否衔接进行判断。
2.3 Finetuning Stage
作者将BERT对不同任务的输入输出进行了适配,具体请见原论文Section 3.2和Section 4.
3 BERT参数量计算
参数量主要来自embedding层的权重矩阵、MHA、layer norm、FFN(未考虑bias)
表格可见How is the number of BERT model parameters calculated?
3.1 Embedding层
- token embedding:词表大小乘向量为度,30522*768
- segment embedding:区分上下句子,参数为2*768
- position embedding:文本输入最长为512,那么参数为512*768
3.2 MHA-qkv_proj/out_proj
qkv的每个投影矩阵大小为768*768,然后还有一个out_proj,参数为768*768
因此总参数为12*(4*768*768)12是因为有12个layer
3.3 LayerNorm
有两个参数,gamma和beta,有三个地方用到了LayerNorm,分别是embedding之后、MHA之后、FFN之后,也就是768+(768+768)*12,12是12个layer
3.4 FFN
中间维度为4d,也就是3072,参数量为12*(768*3062+3062*768)
3.5 总参数量
总的参数=embedding+multi-head attention+layer normalization+feed forward
=23835648+28311552+38400+56623104
=108808704
≈110M