1 动机&基本实现方法
大多数伪装目标检测的方法,大多都致力于提高前景像素的置信度,然而,从另一个角度看,通过抑制背景像素,来让伪装目标浮现出来可能会是一个更有效的方法,并且,背景像素相较于前景像素更容易发现。
因此从背景抑制出发,设计了DSM,将特征分成了高频流和低频流分别处理,使用ORI,对低频进行抑制,对高频进行增强。处理完的特征通过FMD,用低频特征调制高频特征,以补充高频信息,因削弱过后的低频特征内仍然包含一些有用的信息,比如色块、纹理等。
2 Methods
2.0 Obect Mining Module
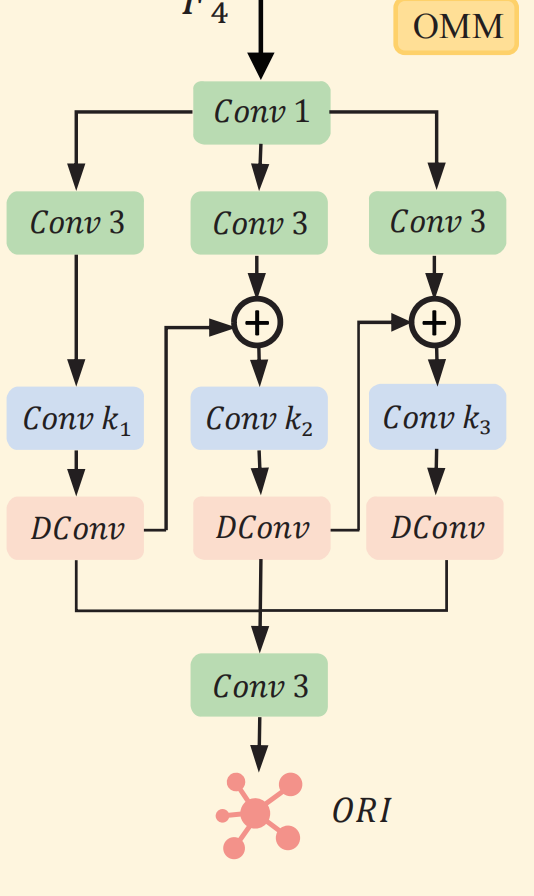
我们将backbone的最后一层特征送进OMM里,它通过不同大小的卷积核提供的不同的感受野,还有膨胀卷积,实现提取丰富的上下文信息,增强小目标的分割,输出的特征为Object-Related Information(ORI),为了提高其提取物体相关特征的信息,我们用GT来监督它。
2.1 DSM
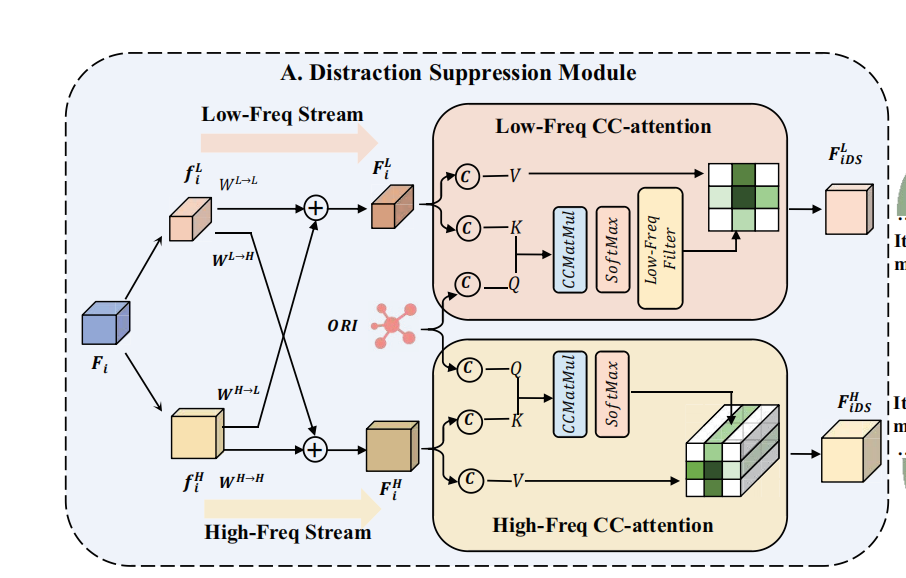
高频特征总是有助于区分伪装目标,然而,低频特征通常代表具有缓慢变化的像素,这些像素容易受到复杂环境引入的干扰信息的污染。
因此可以需要增强高频特征,削弱低频特征,来增强伪装目标的效果。
受限需要将特征分流,分为高频和低频,这里使用的是八度卷积:
\[F_i^H=conv(f_i^H,W^{H\to H})+UP(conv(f_i^L,W^{L\to H})),F_i^L=conv(f_i^L,W^{L\to L})+conv(Down(f_i^H),W^{H\to L}),\]
得到高频低频特征之后,我们使用low-freq attention和high-freq attention对低频削弱、高频增强。具体来说,这两个attention的query都相同,均为ORI,low-freq的key-value是低频特征,high-freq的key-value是高频特征。对于高频特征,就是原始的cross attention,对于低频特征,我们使用低频过滤器,对attention map进行过滤,对于其中每一行,我们只选择前两个最大值,其他置为-inf,然后进行softmax。
在实际代码中,DSM迭代了三次达到了效果和计算效率之间最好的平衡。
2.2 FMD
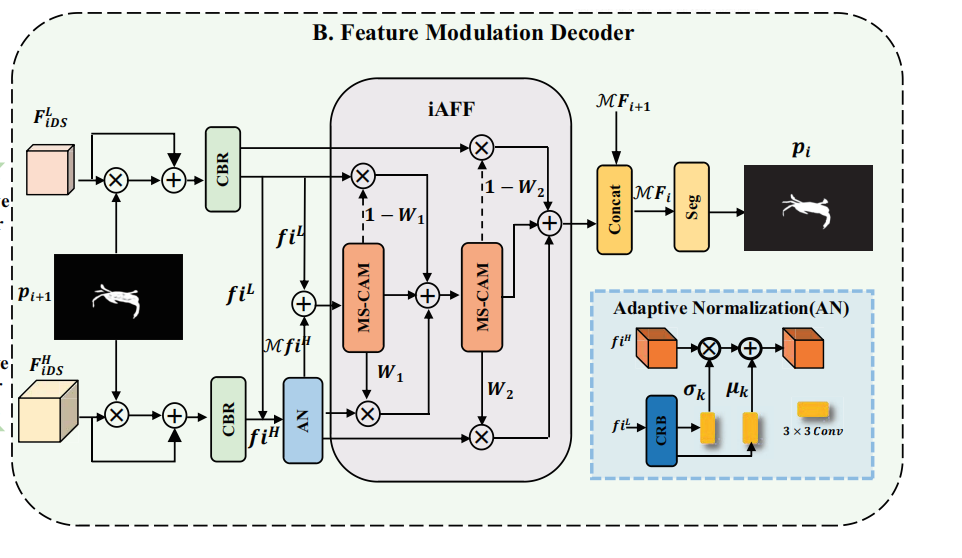
FMD的结构图上图所示,受限用上一阶段的粗分割图和低频、高频特征相乘,得到foreground-interested features,然后经过一层CBR,并且,使用adaptive normalization,用低频特征对高频特征进行调制。可以这么理解,类似于一个传统的视觉任务,风格迁移,就是想要把低频特征的“颜色”、“纹理”等低频特征迁移到高频特征中去,具体来说,batch norm要学习一对仿射变换参数gamma和beta,在adaptive norm里,就直接用低频特征的均值、方差去替代高频特征batch norm里的gamma、beta,但是高频特征batch norm的均值、方差还是它自己的。
3 Experiments
3.1 loss
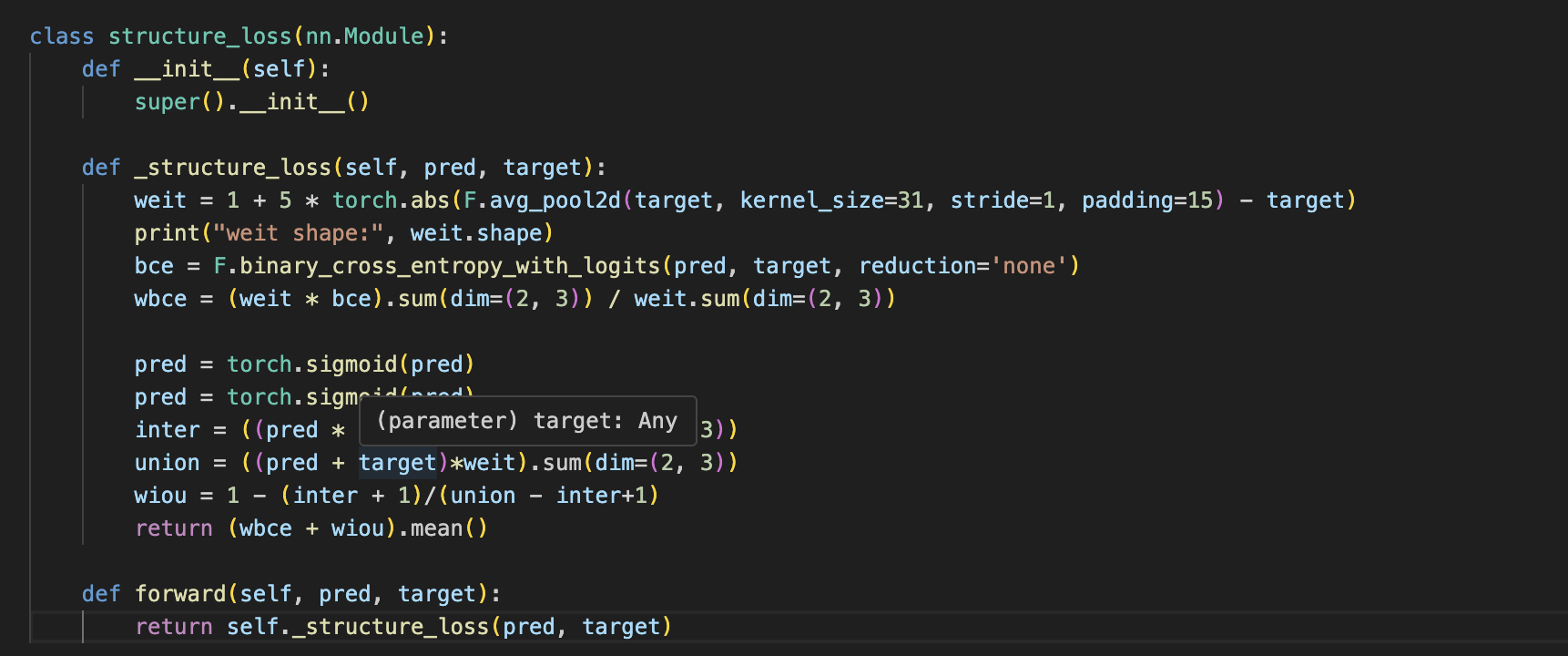
loss用的是weighted BCE loss + weighted IoU loss
- 之前的BCE loss就是简单求每个像素的BCE,然后再平均,忽视了对象的内部结构。
- 对于小目标而言,整张图像的loss会被背景类所主导,导致难以对前景进行学习
- 对象的边缘位置像素非常容易分类错误,不应该与其他位置像素一样给予相似的权重
怎么做weighted?就是对于某一个像素,比如它为前景,但是它周围许多像素都为背景,这种像素应该给予高权重,如果一片区域它的像素都为0或者都为1,则其权重应该较小。某种程度可以理解为这是不需要显式输入边缘信息的boundary-aware,small-object aware的方法。
4 Focal Loss
5 Transformer八股
5.1 为什么要除根号下\(d_k\)
\[\mathrm{Attention}(Q,K,V)=\mathrm{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V\]
attention map里面的每一个值都是由Q里面的一个向量和K里面的一个向量点积得来,当\(d_k\)很大的时候,会导致这个值很大,因此softmax的输出值会不稳定,即大部分趋近于0,小部分趋近于1,会导致梯度几乎为0,训练起来很困难。
那为什么除的是\(\sqrt{d_k}\)?
首先,我们假设向量中的每个元素是同分布的独立变量,并且均值为0,方差为1,那么\(d_k\)个元素,其均值为0,方差为\(d_k\),所以将它除\(\sqrt{d_k}\)可以让这些元素方差为1,使 softmax 的输入值保持在合理范围内,方便训练。
5.2 为何Transformer 模型中采用 Layer Normalization 而非 Batch Normalization?
具体原因详见Lyaer Norm
Layer Normalization 对每个样本独立进行归一化,适用于序列化数据和变长输入,而 Batch Normalization 在批处理时对特征进行归一化,不适用于序列长度变化的情况。
BatchNorm是多个样本同一特征维度归一化,LayerNorm是单个样本所有特征维度归一化
5.3 Transformer中的位置编码
位置编码是用来给模型提供关于单词在序列中位置的信息的。由于Transformer的自注意力机制并不自然地考虑序列中元素的顺序,位置编码通过为每个元素的表示添加位置信息来解决这个问题。
transformer的位置编码满足下列:
- 它能为每个时间步输出一个独一无二的编码;
- 不同长度的句子之间,任何两个时间步之间的距离应该保持一致;
- 模型应该能毫不费力地泛化到更长的句子。它的值应该是有界的;
- 它必须是确定性的。
5.4 Transformer中FFN的作用
- 增强非线性能力:注意力机制是一种线性变换,FFN 通常由两层线性变换和中间的激活函数(如 ReLU、GELU)组成,加入非线性性,提升模型表达能力
- 提升模型特征表达能力:FFN 通常会先将输入维度(d)映射到更高维度(4*d),再降维回原维度,通过 “升维 – 降维” 过程扩展特征空间,捕捉更细粒度的特征。
- 训练稳定性和表达能力提升:FFN 的存在能增强模型的容量(通过更高的中间维度)和梯度流动(非线性激活缓解梯度消失问题),让模型在深层网络中更易训练。例如,Transformer 通常有 6~12 层甚至更多,每一层由 “注意力 + FFN” 组成。如果去掉 FFN,仅靠注意力的线性变换堆叠,模型容易出现表达能力饱和(无法随层数增加而提升性能)。、
- 与注意力机制功能互补:注意力机制是全局的,可以捕捉全局依赖,但对每个位置的局部特征精细化加工较弱,FFN 对每个位置进行独立处理,相当于在 “全局交互” 后,再对每个位置的特征进行 “局部精炼”。
Transformer中的FFN为什么是Position-wise FFN?
attention会输出一个b,s,d大小的序列,有s个d维向量,FFN会对每个d维向量先投影到4d,然后经过ReLU,再投影回d,这种对每个序列都做投影,就是每个position,也就是position-wise,从FFN的流程可以看出,s这个维度一直没有被“触碰”,因此操作是针对每个向量,所有操作(矩阵乘法、激活函数)都是针对
d或4d这个 “特征维度” 进行的,每个位置的处理完全独立于其他位置(比如位置i的计算不会用到位置j的信息)。
5. 5 为什么要有QKV proj,attention不能输入三个一样的吗?
- 打破对称性:一个序列里面的token,A和B,很有可能,A对B的重要程度与B对A的重要程度是不一样的,如果不qkv proj的话,无法体现这种差异
- 增加模型参数,让模型可学习,如果没有这一层,那一个layer参数只有FFN那一块了。
- 增强模型表示能力
- 避免自己和自己点积太大,并且,如果没有qkv proj,那么相似度最大值始终是自己和自己,这严重限制了模型的能力。
6 开放词汇伪装目标分割
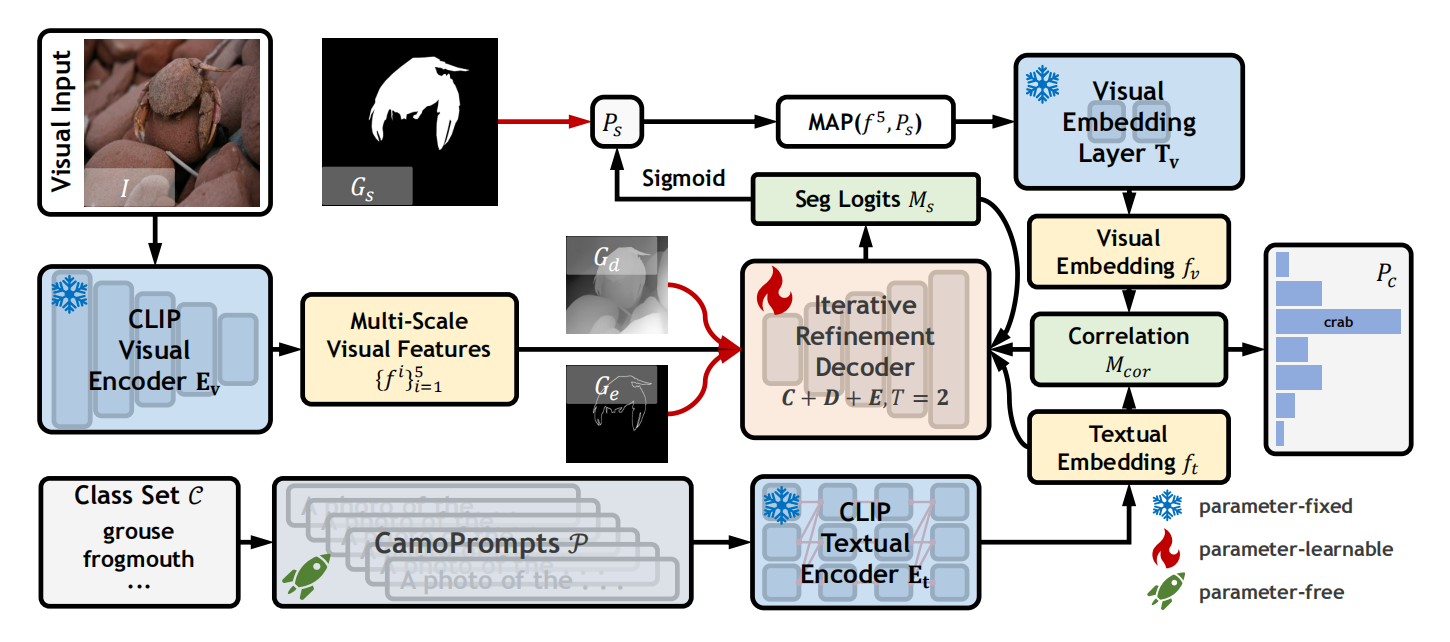
提示工程

使用上图中右侧表的prompts生成句子,并平均,作为某个类的文本特征。
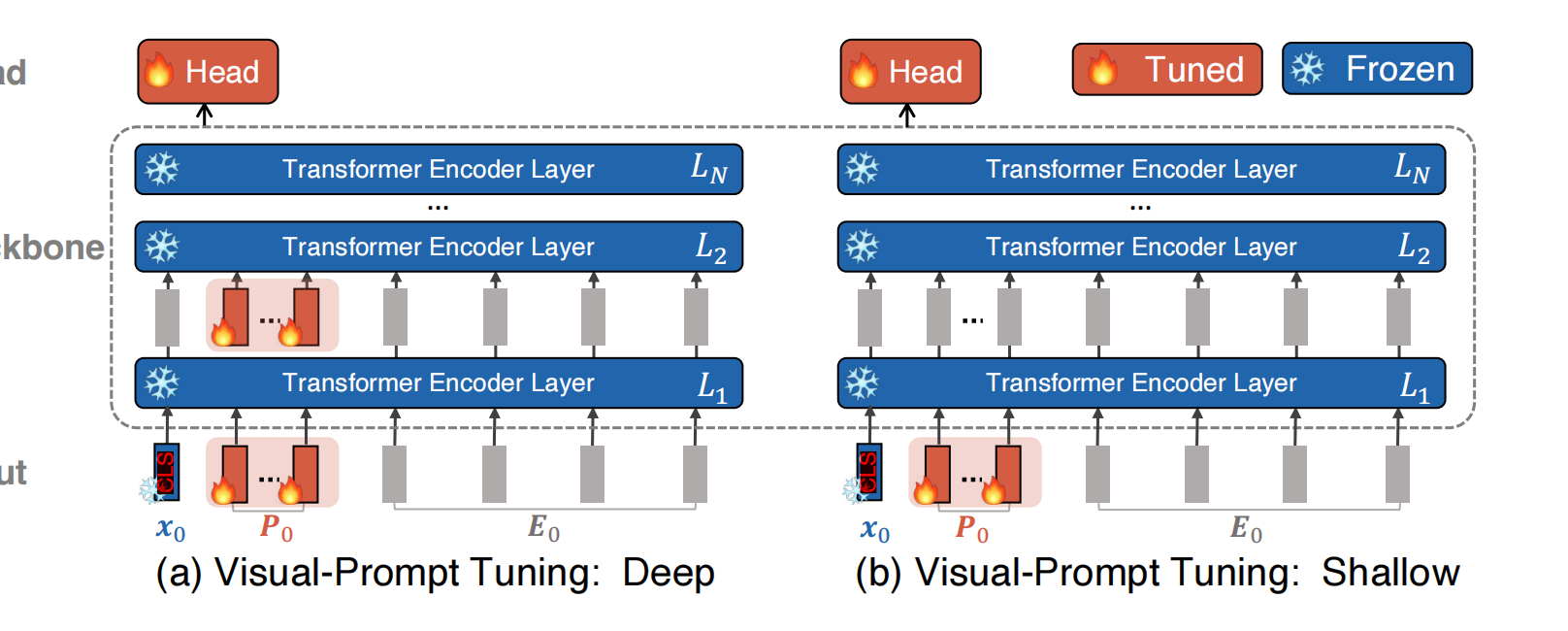
Visual Prompt Tuning
怎么做的类先验?
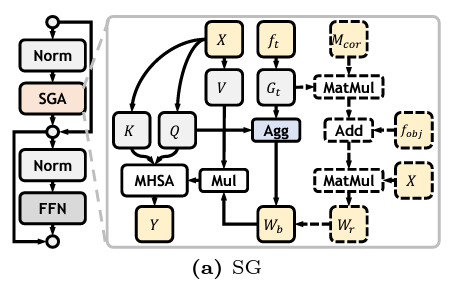
ft是词库向量,它和Q做乘积,会得到每个空间位置,在每个类别上的激活(相似度)。然后在每个空间位置做softmax,然后在每个空间位置上根据softmax的结果做加权平均,得到Wb,叫他类嵌入矩阵,其反应每个位置被类嵌入感知的程度,通俗来讲就是有没有可能是潜在的前景。
怎么使用粗分割的信息去进一步调制类先验?
之前的Wb可能不准确,仅仅通过词信息去判断哪个地方是不是前景。因此引入上一个阶段的粗分割图,对类嵌入矩阵中前景趋于进行放大
怎么引入多源信息(边缘、深度)?
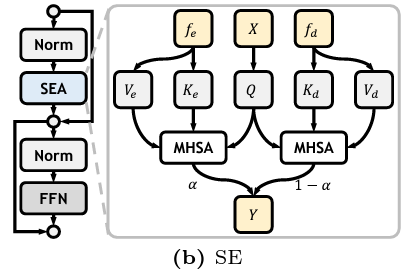
X是来自SE的输出,fe、fd分别是经过卷积之后的边缘、深度特征,经过cross attention,得到两个输出,然后按比例融合
7 cross-modal fusion
跨模态矫正
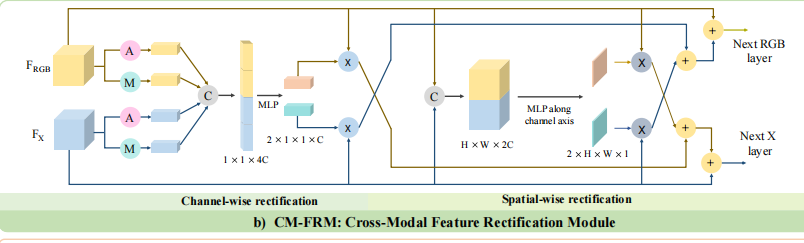
不同模态的信息通常是互补的,但是通常包含噪声。某个模态里面的噪声可通过另一个模态的特征被过滤、矫正。CM-FRM在两个维度进行处理,一个是channel-wise一个是spatial-wise。据此,实现双向矫正。
双阶段特征融合
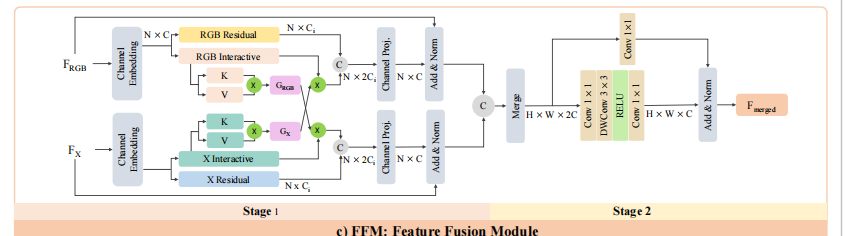
这一模块负责融合两个模态的特征,形成一个统一的特征图。分为两个阶段:信息交换阶段和融合阶段
1. 信息交换阶段:
将RGB模态和X模态序列化,投影成embedding,然后分别经过一个投影层,得到一个残差向量和一个用于和其他模态交互的向量(用作value),在每一个模态的cross-attention里,其value来自本模态,但是Q、K来自其他模态,也就是说,attention map又另一个模态产生,实现一个信息交换,经过信息交换玩的value和之前的残差向量相加。
2.融合阶段:
信息交换阶段会有两个输出,concat之后通过1×1卷积让他们融合。但是这只是通道维度的融合,又加了一个depth-wisse conv去充分融合空间维度的特征。
通过上述两个阶段,两个模态的特征充分融合,送到下一个feature decoding阶段。