论文地址:I Can Find You! Boundary-Guided Separated Attention Network for Camouflaged Object Detection
1 论文要解决的问题
我们人类在辨别那些伪装目标的时候,通常是先发现出前景和背景之间的微小区别,当逐渐发现他们之间的区别时,借此可以一步步发现边缘,然后通过边缘可以一点点发现Camouflaged Object。现有的方法没有考虑到这一点。
2 论文提出的解决方案
- separated attention module:这一模块分为两个流(stream),分为前景流和背景流,分别关注前景信息和背景信息,通过前景背景信息的协同,边缘信息可以显现出来(这就模拟了人类发现伪装目标的过程:通过前景和背景之间的区别发现边缘)原文中作者这么解释的:By coordinating the foreground and background information, the boundary of camouflaged object is highlighted. The boundary information is utilized to find camouflaged object.
- Boundary Guider:SOD、COD任务都是像素维度的prediction,但是在边缘附近的像素是很难预测的,因为边缘像素周围的分布是异常的,而且原图会经过多次提取特征,然后通过上采样恢复分辨率,这一操作必定会损失大量的信息,让边界更加难以预测,所以说作者采用Boundary Guider这一模块将边缘信息“integrate”或者“encode”进特征空间当中,来增强模型对边缘的敏感性,提高COD任务的精度。
3 模型结构
模型整体架构图:
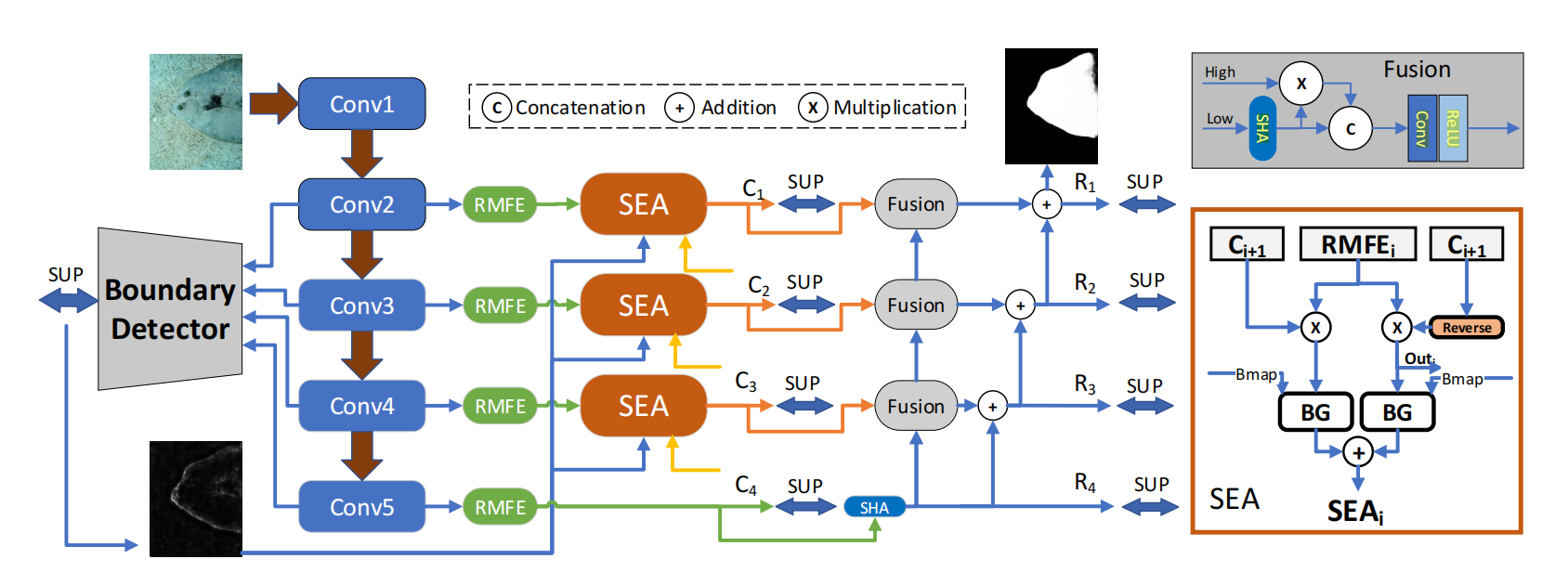
3.1 Residual Multi-scale Feature Extractor(RMFE)
- 输入:四个Conv Block的输出特征图。
- 输出:经过多尺度特征提取之后的特征图,会被送往SEA模块中。
- RMFE的目的:在这种顺序结构的网络模型中想要得到多尺度的特征图比较困难,但是如果我们直接采用side- output的话,底层的特征图由于没做几次卷积,导致每个元素感受野不大,并且不含有多尺度的信息。通过RMFE模块,让偏低层的side-output也能具有较大的感受野和多尺度信息
- RMFE结构图
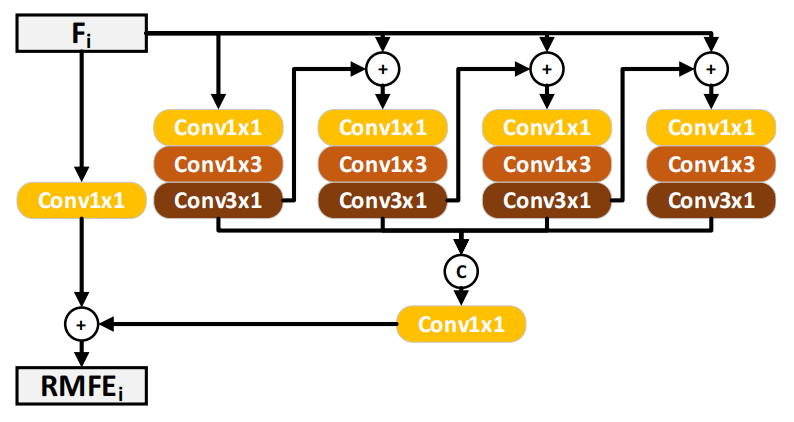
原文中说到“It utilizes stacked residual blocks to enlarge the receptive field layer by layer.”
3.2 Separated Attention
- 输入:本层RMFE模块的输出\(RMFE_i\),上一层分支预测的伪装图\(C_{i+1}\),以及Boundary Detector模块预测的边缘图\(B_{map}\)
- 输出:第一个输出为预测的伪装图\(C_i\),参与下一个SEA模块的预测;第二个是两个流以及边缘图充分融合得到的特征\(SEA_i\),他会参与到网络后半部分更精细的融合。可以说SEA模块最主要的作用还是增强特征,而不是预测伪装图。它预测得到粗略的伪装图\(C_1-C_4\)仅仅用于帮助下一个SEA模块分离前景背景,整个BSA-net对伪装图的预测是靠后半部分的Fusion模块预测出的\(R_1-R_4\)
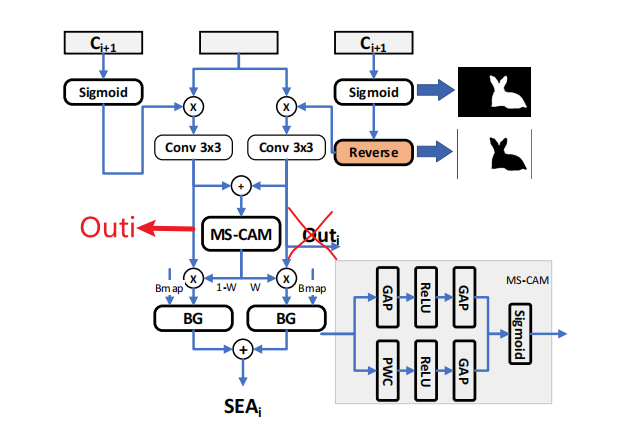
计算过程:
1 这个模块包含两个流,第一个流是前景流,将\(C_{i+1}\)与\(RMFE_i\)相乘,在这里,\(C_{i+1}\)相当于Query和Key相乘得到的attention map,\(RMFE_i\)相当于Value。然后经过一个3×3的Conv,在经过一个1×1的Conv;第二个流是背景流,首先用1减去sigmoid之后的 \(C_{i+1}\),再与\(RMFE_i\)相乘,后面的步骤等同于前景流。下式中\(W_{bai}\)与\(W_{fai}\)分别代表sigmoid之后的\(C_{i+1}\),\(Out_i\)代表输出,会当作\(C_{i}\)输入给下一层SEA。这里论文写的有误,通过查看源码,可以看出\(Out_i\)应该是\(Fa_i\)而不是\(Ba_i\)
# ra_4是C_{i+1}
ra_4 = F.interpolate(rme4, size=rme3.size()[2:], mode='bilinear')
ra_4 = self.ra41_conv(ra_4)
ra_4 = 1 - torch.sigmoid(ra_4)
ra_4_weight = ra_4.expand(-1, rme3.size()[1], -1, -1)
rra_4_weight = 1 - ra_4_weight
ra_4_out = ra_4_weight * rme3
rra_4_out = rra_4_weight * rme3
ra_4_out = self.ra4_conv(ra_4_out)
rra_4_out = self.rra4_conv(rra_4_out)
map_3 = self.linearr3(ra_4_out)
out_3 = F.interpolate(map_3, size=image_shape, mode='bilinear')
# 下一层SEA的输入是ra_4_out(C_{i}), 其由ra_4_weight * rme3(前景流)得到,而不是rra_4_weight * rme3(背景流)
# 通过源码可以看出,作者在论文里表述有误
ra_3 = F.interpolate(ra_4_out, size=rme2.size()[2:], mode='bilinear')
ra_3 = self.ra31_conv(ra_3)
ra_3 = 1 - torch.sigmoid(ra_3)
ra_3_weight = ra_3.expand(-1, rme2.size()[1], -1, -1)
rra_3_weight = 1 - ra_3_weight
ra_3_out = ra_3_weight * rme2
rra_3_out = rra_3_weight * rme2
ra_3_out = self.ra3_conv(ra_3_out)
rra_3_out = self.rra3_conv(rra_3_out)
map_2 = self.linearr2(ra_3_out)
out_2 = F.interpolate(map_2, size=image_shape, mode='bilinear')
\[\begin{aligned}Ba_i&=Conv_s(RMFE_i\otimes expand(W_{bai})),\\Fa_i&=Out_i=Conv_s(RMFE_i\otimes expand(W_{fai})),\end{aligned}\]
注意,在计算之前,\(C_{i+1}\)会做一个upsampling操作以保证\(C_{i+1}\)和\(RMFE_i\)的H和W一样,还会做一个\(expand\)操作以保证\(C_{i+1}\)和\(RMFE_i\)channel数一样,这样\(C_{i+1}\)与\(RMFE_i\)就可以在每个通道上做相乘
2 然后是MS-CAM,这个模块用于增强两个分支流之间的信息交互,利用MS-CAM模块对两个分支的特征进行增强之后,将其送入BG模块之中,利用网络最初预测出的\(B_{map}\)
,进一步增强边缘的完整性。最后将两个流的输出直接相加,得到SEA模块的输出特征。此特征会用于后续的fusion模块用于聚合并预测精细的伪装图.
\[\begin{aligned}SEAF_i&=BG_i(W(Ba_i+Fa_i)\otimes Ba_i,Bmap),\\SEAB_i&=BG_i((1-W(Ba_i+Fa_i))\otimes fa_i,Bmap),\\SEA_i&=SEAF_i\oplus SEAB_ii=2,3,4,\end{aligned}\]
上式中\(W(*)\)代表MS-CAM模块的输出的attention map
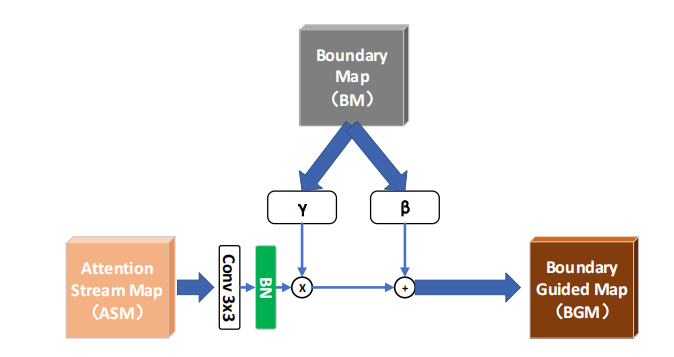
3.3 Boundary Guider
- 获得Boudary Map:作者使用backbone的四层side-features,把他们做concat,并且然后使用卷积获得Boudary Map,这一过程受Ground Truth的监督
- 使用Boudary Map增强前景和背景中的边缘信息:这一模块将边缘信息“integrate”或者“encode”进特征空间当中。在这一模块中,作者采用了Conditional Batch Normalization,利用由Boudary Map得到的\(\gamma_{pred}\)和\(\beta_{pred}\)(因为\(\gamma_{pred}\)和\(\beta_{pred}\)是由Boudary Map得到的,故\(\gamma_{pred}\)和\(\beta_{pred}\)内含了Boundary Map的信息)。然后通过\(BGM_{i}=CB(ASM_{i})\otimes\gamma(BM)\oplus\beta(BM)\),把Boudary Map的信息整合到Attention Steam Map中去。得到Boudary Guided Map
普通的BN层中的\(\gamma\)还有\(\beta\)是通过反向传播学习的,但在CBN中,\(\gamma\)还有\(\beta\)(在这里我们称作\(\gamma_{pred}\)和\(\beta_{pred}\))是通过将feature送进一个小型神经网络进行前向传播得到的,而不是学习得到的网络参数(普通的BN层中\(\gamma\)还有\(\beta\)在推理时和feature无关,但是在CBN中,\(\gamma_{pred}\)和\(\beta_{pred}\)取决于feature,是由feature前向传播得到的)
- 将两个流得到的两个Boudary Guided Map相加,得到\(SEA_i\)为SEA module的最终输出,该输出会被用于fusion,得到最终的伪装目标检测图
4 Experiment
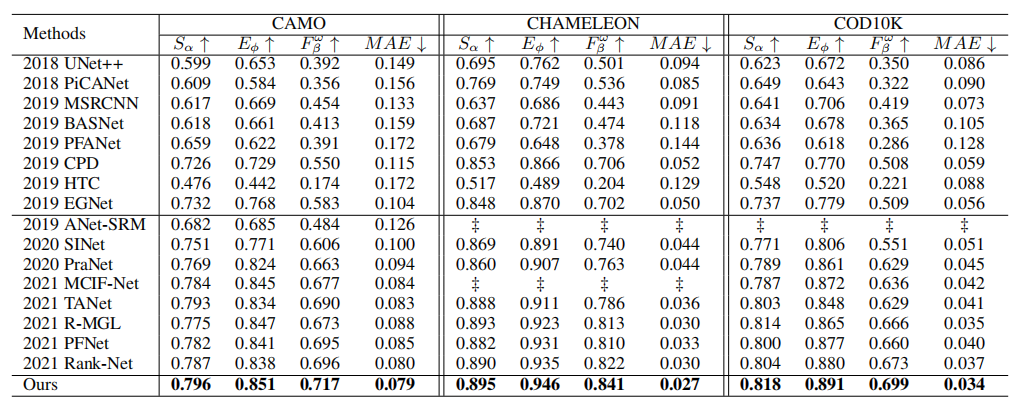
4.1 Comparison with SOTA
4.2 Ablation Study
模型a由骨干网络Res2Net和剩余多尺度特征提取器(RMFE)模块组成;模型b在模型a上添加了分离的注意(SEA)模块;模型c在模型a上添加了边界引导器(BG),模型d是最终模型。

5 Contributions
对于COD任务,作者提出了一种新的边界引导分离注意力网络,即BSA-Net,通过模拟人类寻找伪装物体的方式,设计了分离注意力模块(SEA), 一个流关注前景,另一个流擦除前景关注背景,并且设计了一个边界引导模块将边缘先验传播到两个流中,之后将两个流合并用于突出伪装物体的边界,最后通过跨层融合的方式将多个SEA模块的输出进行融合,生成最后的伪装图,取得了较好的效果。