为什么要使用Batch Normalization?
使用浅层模型时,随着模型训练的进行,当每层中参数更新时,靠近输出层的输出较难出现剧烈变化。对深层神经网络来说,随着网络训练的进行,前一层参数的调整使得后一层输入数据的分布发生变化,各层在训练的过程中就需要不断的改变以适应学习这种新的数据分布。所以即使输入数据已做标准化,训练中模型参数的更新依然很容易导致后面层输入数据分布的变化,只要网络的前面几层发生微小的改变,那么后面几层就会被累积放大下去。最终造成靠近输出层输出的剧烈变化。这种计算数值的不稳定性通常令我们难以训练出有效的深度模型。如果训练过程中,训练数据的分布一直在发生变化,那么将不仅会增大训练的复杂度,影响网络的训练速度而且增加了过拟合的风险。
Batch Normalization的作用
- 加快收敛速度:在深度神经网络中中,如果每层的数据分布都不一样的话,将会导致网络非常难收敛和训练,而如果把每层的数据都在转换在均值为零,方差为1 的状态下,这样每层数据的分布都是样的训练会比较容易收敛。
- 防止梯度爆炸和梯度消失:sigmoid函数在x过大或过小的时候,梯度是非常小的,BN可以把数据调整到x=0附近,可以保证梯度不会太小。
- 防止过拟合:在网络的训练中,BN的使用使得一个minibatch中所有样本都被关联在了一起,因此网络不会从某一个训练样本中生成确定的结果,即同样一个样本的输出不再仅仅取决于样本的身,也取决于跟这个样本同属一个batch的其他样本,而每次网络都是随机取batch,这样就会使得整个网络不会朝这一个方向使劲学习。一定程度上避免了过拟合。
1 Batch Normalization
1.1 归一化
计算所有输入数据的均值、方差
\[\widehat{x}^{(k)}=\frac{x^{(k)}-\mathrm{E}[x^{(k)}]}{\sqrt{\mathrm{Var}[x^{(k)}]}}\]
具体计算过程如下:

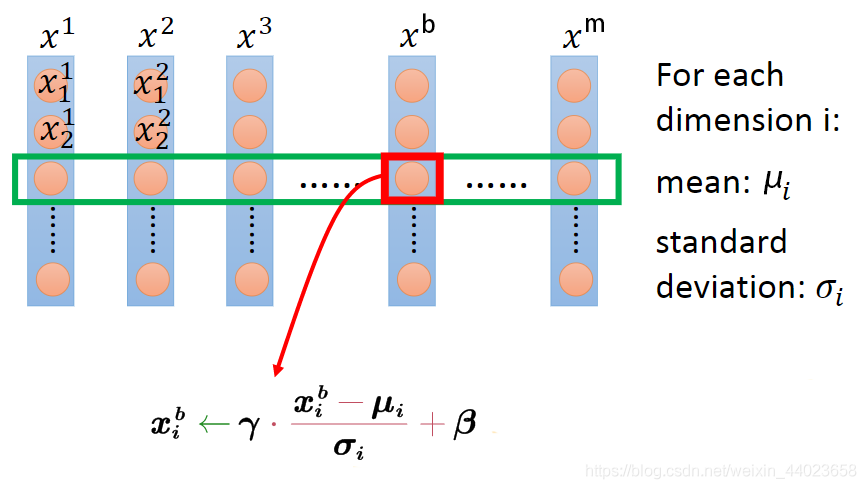
每一个\(x_i\)就是一个样本,共有m个样本,即batch_size=m,假设每个\(x_i\)的dimension为d,那么神经元的个数就是d。从图中可以\(\gamma\),\(\beta\)的数量和维度数相等,为d
1.2 Affine
如果是仅仅使用上面的归一化公式,对网络某一层A的输出数据做归一化,然后送入网络下一层B,这样是会影响到本层网络A所学习到的特征的。打个比方,比如我网络中间某一层学习到特征数据本身就分布在S型激活函数的两侧,你强制把它给我归一化处理、标准差也限制在了1,把数据变换成分布于s函数的中间部分,这样就相当于我这一层网络所学习到的特征分布被你搞坏了,为了解决这个问题,恢复出原始的某一层所学到的特征的,采用变换重构(scale and shift),引入了可学习参数γ、β,这就是算法关键之处
\[y^{(k)}=\gamma^{(k)}\widehat{x}^{(k)}+\beta^{(k)}.\]
每一个神经元\(\widehat{x}(k)\)都会有一对γ、β与其对应

1.3 卷积中的Batch Normalization如何实现的
通过上面的学习,我们知道BN层是对于每个神经元做归一化处理,甚至只需要对某一个神经元进行归一化,而不是对一整层网络的神经元进行归一化。既然BN是对单个神经元的运算,那么在CNN中卷积层上要怎么搞?假如某一网络层的输出的特征图的大小是C*H*W=6*100*100,这样就相当于这一层网络有6*100*100个神经元,如果采用BN,就会有6*100*100个参数γ、β,这样岂不是太恐怖了。因此卷积层上的BN使用,其实也是使用了类似权值共享的策略,把一整张特征图当做一个神经元进行处理。
卷积神经网络经过卷积后得到的是一系列的特征图,如果min-batch sizes为m,那么网络某一层输入数据可以表示为四维矩阵(m,f,p,q),m为min-batch sizes,f为channel数,p、q分别为特征图的宽高。在cnn中我们可以把每个特征图看成是一个特征处理(一个神经元),因此在使用Batch Normalization,于是对于每个特征图都只有一对可学习参数:γ、β(共享参数)。说白了,这就是相当于求取所有样本所对应的某一channel的所有像素的平均值、方差,然后对这个特征图神经元做归一化。
2 Conditional Batch Normalization
Conditional Batch Normalization出自Modulating early visual processing by language
这篇文章改进了一个基于图片的问答系统 (VQA: Visual Question Answering)。系统的输入为一张图片和一个针对图片的问题,系统输出问题的答案,如下图所示:
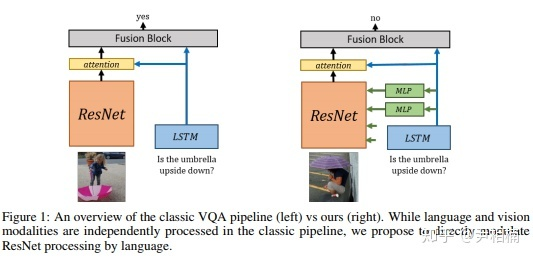
这类系统通常是这样设计的:一个预训练的图像识别网络,例如 ResNet,用于提取图片特征;一个 sequential 模型,例如 LSTM、GRU 等,用于提取句子的特征,并根据句子预测应该关注图片的什么位置(attention);将语言特征、由 attention 加权过后的图片特征结合起来,共同输入一个网络,最终输出问题的答案。
上图左侧为传统的 VQA 系统,我们发现,LSTM 提取的特征只在 ResNet 的顶层才和图片特征结合起来,因为通常意义上讲,神经网络的底层提取的是基础的几何特征,顶层是有具体含义的语义特征,因此,应该把语言模型提取的句子特征在网络顶层和图片特征结合。然而,作者认为,底层的图片特征也应该结合语言特征。理由是,神经科学证明:语言会帮助图片识别。例如,如果事先告诉一个人关于图片的内容,然后再让他看图片,那么这个人识别图片的速度会大大加快。因此,作者首创了将图片底层信息和语言信息结合的模型,如上图右侧所示。

传统Batch Normalization

简单来说,在BN中,\(\gamma\),\(\beta\)是网络再训练的时候就确定下来的,是固定的,但是在CBN中,\(\gamma\),\(\beta\)是通过前向传播计算得到的,是实时计算出来的,至于如何计算,应该与你的任务相匹配。
Example:但是在生成对抗网络 (Generative Adversarial Networks, GAN) 中使用 BN 会导致生成图片在一定程度上出现同质化的缺点。例如,在 CIFAR10 数据集中,有10类图片:6种是动物(分别为:鸟,猫,鹿,狗,青蛙和马),4种是交通工具(分别是:飞机,汽车,轮船和卡车)。显然,不同类别的图片在外观上看起来截然不同——交通往往具有坚硬而笔直的边缘,而动物倾向于具有弯曲的边缘和较柔和的纹理。
在风格迁移中我们已经了解了,激活的统计数据决定了图像样式。因此,混合批统计信息可以创建看上去有点像动物同时也有点像交通工具(例如,汽车形状的猫)的图像。这是因为批归一化在由不同类别图片组成的整个批次中仅使用一个 γ 和一个 β 。如果每种类别都有一个 γ 和一个 β,则该问题得以解决,而这正是条件批规范化的意义所在。每个类别有一个 γ和一个 β(不再像BN一样按照Channel分配γ与β),因此CIFAR10中的10个类别每层有10个 γ 和10个 β。