Batch Normalization,Layer Normalization
1 motivation
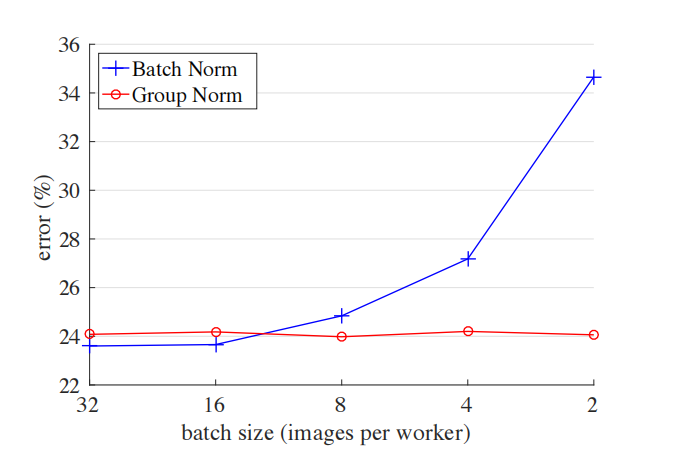
在视觉领域,其实最常用的还是BN,但BN也有缺点,通常需要比较大的Batch Size。如下图所示,蓝色的线代表BN,当batch size小于16后error明显升高(但大于16后的效果确实要更好)。对于比较大型的网络或者GPU显存不够的情况下,通常无法设置较大的batch size,此时可以使用GN。如下图所示,batch size的大小对GN并没有影响,所以当batch size设置较小时,可以采用GN。
2 计算过程
- 分组:首先,对于每个样本(与batch是无关的),输入特征的通道被分成若干个组。假设有C个通道,被分成G组,每个组会有C/G个通道
- 计算均值:对于每个组,计算该组内所有通道的均值。如果一个组内有 个数据点(这包括该组内所有通道的所有空间位置),组内均值 计算如下:\[\mu=\frac1N\sum_{i=1}^Nx_i\]
- 计算方差:接着,计算该组内所有通道的方差。组内方差 计算如下:\[\sigma^2=\frac1N\sum_{i=1}^N(x_i-\mu)^2\]
- 规范化:\[y_i=\frac{x_i-\mu}{\sqrt{\sigma^2+\epsilon}}\]
- 缩放\(\gamma\)和偏移\(\beta\):在计算了每个组的均值和方差,对组内特征进行规范化之后,GN通常会进行一个仿射变换。这两个参数是针对每个通道独立学习的,允许模型调整规范化后的输出,以更好地适应数据的特定特征。\[\hat{y_i}=\gamma\cdot y_i+\beta \]仿射操作的引入使得GN不仅仅是简单地标准化数据,而是提供了模型自适应调整规范化过程的能力。这种灵活性是非常重要的,因为它允许模型保留或恢复可能被规范化步骤过度压缩的重要信息。
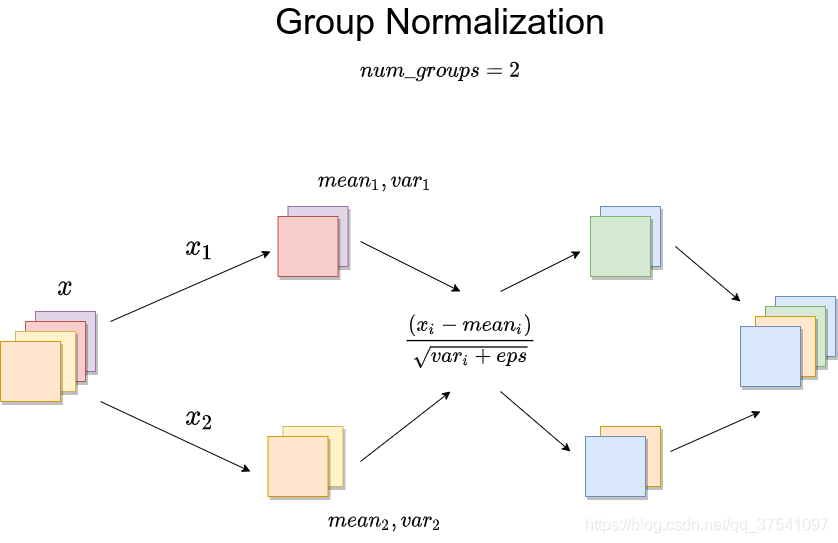
为了形象展示,我用了一张图(图片来源),下图中,每个样本被分成了两组