1 研究目的
特征融合是提高CNN表达能力的一种手段,它将来自不同层次或分支的特征进行组合。什么是特征融合?简单来说,就是有两个特征图X和Y,将X和Y以一定的weight(或者说attention)融合成一个新的特征图。目前来说,特征融合存在以下问题:
- 不健康的初始聚合:通常,在进行X+Y的时候,要么是add,要么是concat,但是如果当X是low level detailed feature,Y是high level semantic feature,两者信息差异过大,如果直接进行add/concat,会导致不好的效果。这种粗暴的add/concat可能会导致瓶颈
- 产生attention时只有全局尺度(Global scale):比如说SENet,在产生channel-wise attention的时候,直接将特征图的每一层做GAP,这样就会损失一些局部的细节,导致在小目标上的识别效果很不好。
- 在融合特征X和Y的时候,产生的attention通常只与一方有关,要么是G(X),要么是G(Y),但是更好的方式是G(X+Y)。X和Y在融合是,通常是一方乘以attention后直接加到另一方是,而不是以一种软选择或者加权平均的方式。
作者为了解决上述问题,提出了Multi-scale Channel Attention(用于解决问题2),iterative Attention Feature Fusion(用于解决问题1和3)
2 Multi-scale Channel Attention
2.1 回顾SENet
SENet通过将一个C✖️H✖️W的特征图变成一个C✖️1的一维向量来产生attention(共有C个attention)的,具体式子如下:
\[\mathbf{w}=\sigma\left(\mathbf{g}(\mathbf{X})\right)=\sigma\left(\mathcal{B}\left(\mathbf{W}_2\delta\left(\mathcal{B}\left(\mathbf{W}_1(g(\mathbf{X}))\right)\right)\right)\right)\]
其中\(g(\mathbf{X})~=~\frac1{H\times W}\sum_{i=1}^H\sum_{j=1}^W\mathbf{X}_{[:,i,j]}\)是分通道进行GAP,\(\delta\)是ReLU,\(\mathbf{B}\)是Batch Norm,\(\sigma\)是sigmoid,\({\mathbf{W}_1}\in\mathbb{R}^{\frac Cr\times C}\),\(\begin{aligned}\mathbf{W}_2\in\mathbb{R}^{C\times\frac Cr}\end{aligned}\)是线性层。
从上述计算过程可以看出,SENet用的是全局平均池化对每一个通道进行平均,这样“Global Scale”的操作势必会损失掉small objects的细节,导致效果不佳。
2.2 Multi-scale Channel Attention
为了在产生attention的时候,既能关注到Global Scale,又能关注到Local Scale,作者创建了Multi-scale Channel Attention。网络结构如下
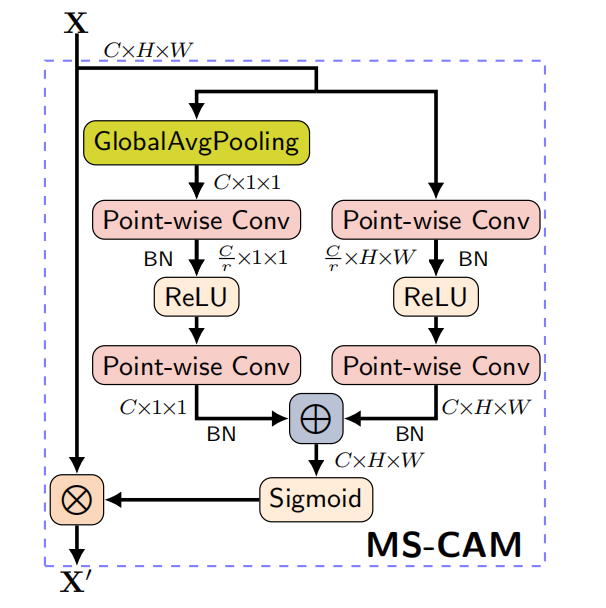
左边数据流是Global Scale,右边数据流是Local Scale
- Global Scale上,处理方式同SENet,产生通过GAP以及两个全连接层产生一维向量weight,具有全局尺度的信息
- Local Scale上,通过两个1✖️1的卷积层产生一个和X同样shape的weight,具有局部的细节信息
数学表达式:
\[\mathbf{X}^{\prime}=\mathbf{X}\otimes\mathbf{M}(\mathbf{X})=\mathbf{X}\otimes\sigma\left(\mathbf{L}(\mathbf{X})\oplus\mathbf{g}(\mathbf{X})\right)\]
L是右边的数据流的输出,g是左边数据流的输出,\(\oplus\)是广播相加(broadcasting addition)
通过MS-CAM,解决了生成attention的时候,只有全局尺度,没有局部细节的问题了
3 Attention Feature Fusion
上一节中的MS-CAM,解决了如何生成更健全的attention的问题。但是给定两个特征图X和Y,如何把他们进行融合,给MS-CAM传入什么样的信息去产生attention,这是AFF module要解决的问题。
3.1 AFF
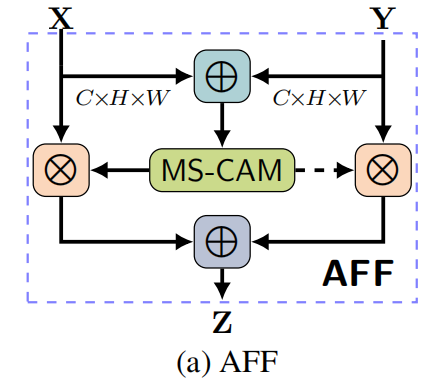
上图很好理解,作者的图画的很好,计算过程一目了然。数学表达式:
\[\mathbf{Z}=\mathbf{M}(\mathbf{X}\uplus\mathbf{Y})\otimes\mathbf{X}+(1-\mathbf{M}(\mathbf{X}\uplus\mathbf{Y}))\otimes\mathbf{Y}\]
值得一提的是,作者采用的X和Y前的系数,\(\mathbf{1-M}(\mathbf{X}\uplus\mathbf{Y})\)和\(\mathbf{M}(\mathbf{X}\uplus\mathbf{Y})\)让网络能够在X和Y之间进行软选择(soft selection)或者加权平均
还有一点需要注意,这里的\(\uplus\)(也就是初始特征的聚合,initial integration)是如何计算的,是直接进行粗暴的add或者concat,还是有更好的方式进行\(\uplus\)操作?(其实就是问题1),作者使用iterative Attention Feature Fusion(iAFF)来解决.
3.2 Iterative Attention Feature Fusion
在论文中,作者采用一个AFF module来实现X与Y的initial integration。
\[\mathbf{X}\uplus\mathbf{Y}=\mathbf{M}(\mathbf{X}+\mathbf{Y})\otimes\mathbf{X}+(1-\mathbf{M}(\mathbf{X}+\mathbf{Y}))\otimes\mathbf{Y}\]
\(\mathbf{X}\uplus\mathbf{Y}\)就是相互融合得到的信息,取代了add/concat(注意,这里的相互融合不是指特征融合Feature Fusion,\(\mathbf{X}\uplus\mathbf{Y}\)是initial integration的结果,而不是feature fusion的结果)
接着,作者将\(\mathbf{X}\uplus\mathbf{Y}\)作为MS-CAM的输入计算出来\(\mathbf{M}(\mathbf{X}\uplus\mathbf{Y})\)(就是attention map),然后根据attention map 将X与Y进行soft selection或者说加权平均
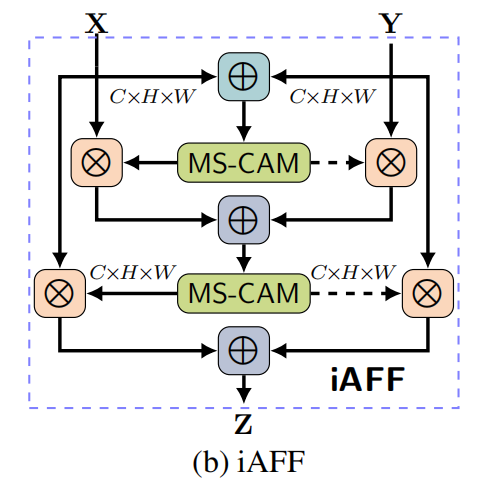
如何理解迭代的这两层呢?
第一层AFF,也就是\(\mathbf{X}\uplus\mathbf{Y}\),在学习X与Y的内在信息,将X与Y相融合(不是feature fusion,叫initial integration),然后第二层,根据X与Y的内在信息,去做X和Y的feature fusion。换一种说法,让网络自己学习如何更充分的利用X和Y的内在信息去更好的fuse X与Y,而不是简单的根据X+Y去生成attention(原因前面讲过,X和Y可能一个低层,一个高层,两者直接相加可能会有“生殖隔离”)
4 paper中一些名词的解释

上图中的Context-aware,Type分别是什么意思,指的是什么?
首先说明,在作者的图里,对于long skip connect,X是low-level-detailed-feature,Y是high-level-semantic-feature
我们可以吧feature fusion分成两步
- 第一步,生成attention map(或者说weights)
- 第二步,根据attention map将X和Y进行fusion
第一个名词Context-aware就是在生成attention map的时候是否用到/是否部分用到/是否全部用到X与Y,None就是根本没有注意力机制,没有attention map,压根没用X和Y;Partially就是在生成attention map的时候,仅用了X或Y一者,即G(X)或者G(Y);Fully就是在生成attention map的时候,X和Y都用到了,是最全面的一种,即G(X, Y)。
第二个名词,Type,就是采用哪种方式进行X与Y的fusion。addition/concat无需再解释,是X和Y fusion的最初等的方式;Refinement,就是通过Y以及Y产生的attention对X进行一个精修(refine)操作;Modulation是对于Long Skip来说的,X和Y通常信息有很大的差异,一般是通过高层的语义信息产生attention map来指导X如何与Y融合;soft selection,与之前的Refinement和modulation不同,它不再是把一方乘以一个权重加到另一方,而是两者是一个平等关系,通过一个权重进行加权平均。
值得注意的是,SKnet和iAFF数学表达式是差不多的,但还是有区别的,区别如下:
- 两者产生attention1的方式不同,iAFF是通过MS-CAM产生的,具有Global Local两个尺度,但是SKNet只有Global尺度
- 两者在初始融合(initial integration)上不同,SKNet是通过直接将X与Y进行addition,但是iAFF是通过网络学习,学习到一个更加适合任务的integration way
5 Experiment
5.1 Impact of Multi-Scale Context Aggregation
这一部分实验是探究在产生attention的时候,MS-CAM同时关注Global和Local是否会对网络有提升,作者设计了三个实验,分别是‘Global+Global’,‘Local+Local’,‘Global+Local’。其中‘Global+Local’就是MS-CAM。前两者结构图如下:
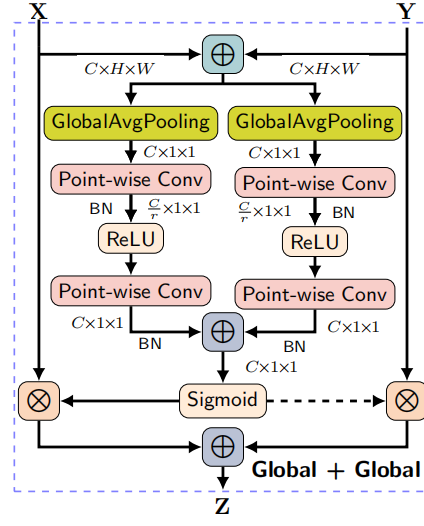
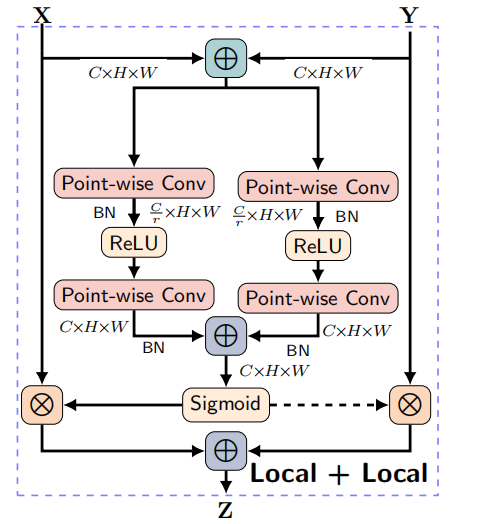
实验结果:

5.2 Impact of Feature Integration Type
这一部分就是探究X和Y的initial integration的方式对网络性能的影响。
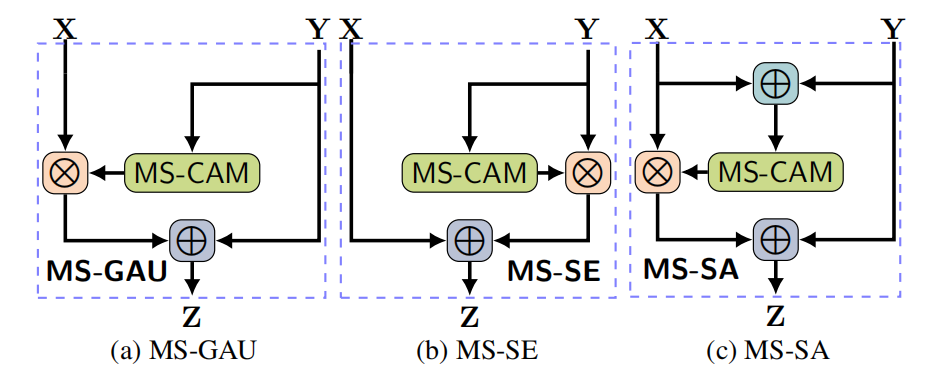
作者为了消除变量的影响,在产生attention时,统一用MS-CAM。,经过MS—CAM改造后的GAU、SE、SA见上图,作者总共做了七组对比实验:
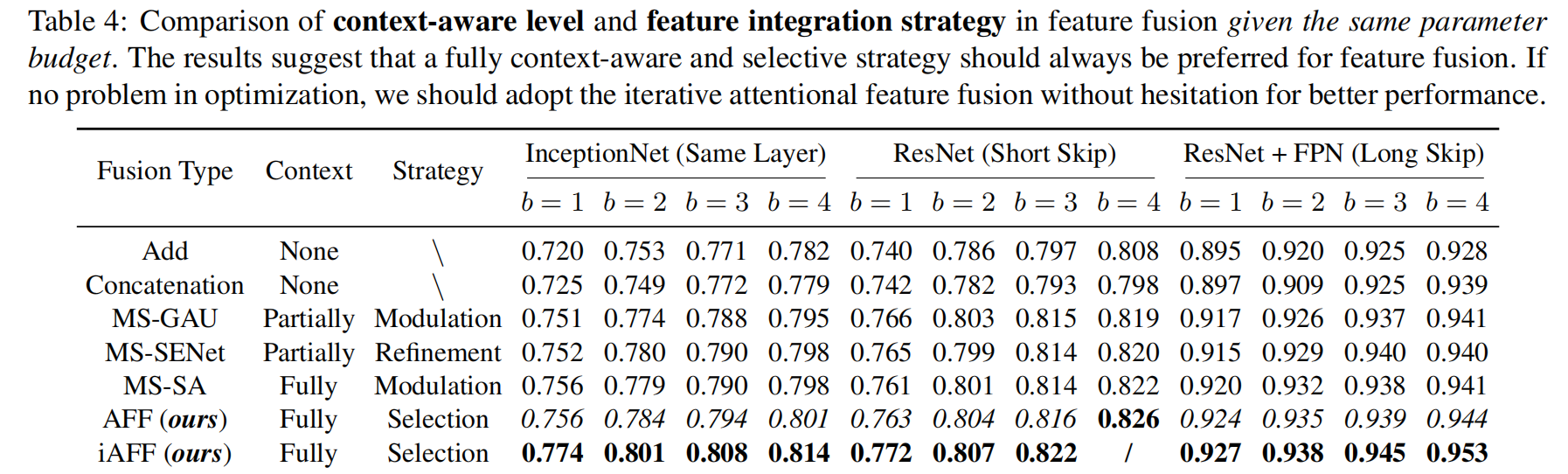
前六组,即add到AFF(ours),是代表最普通的X+Y的integration,iAFF(ours)是代表通过网络学习合适的integration的方式。可以看出,iAFF效果是最好的。
除此之外,作者还做了一些visualization还有comparison with SOTA的实验,这里不再展示,可以自行查阅论文。