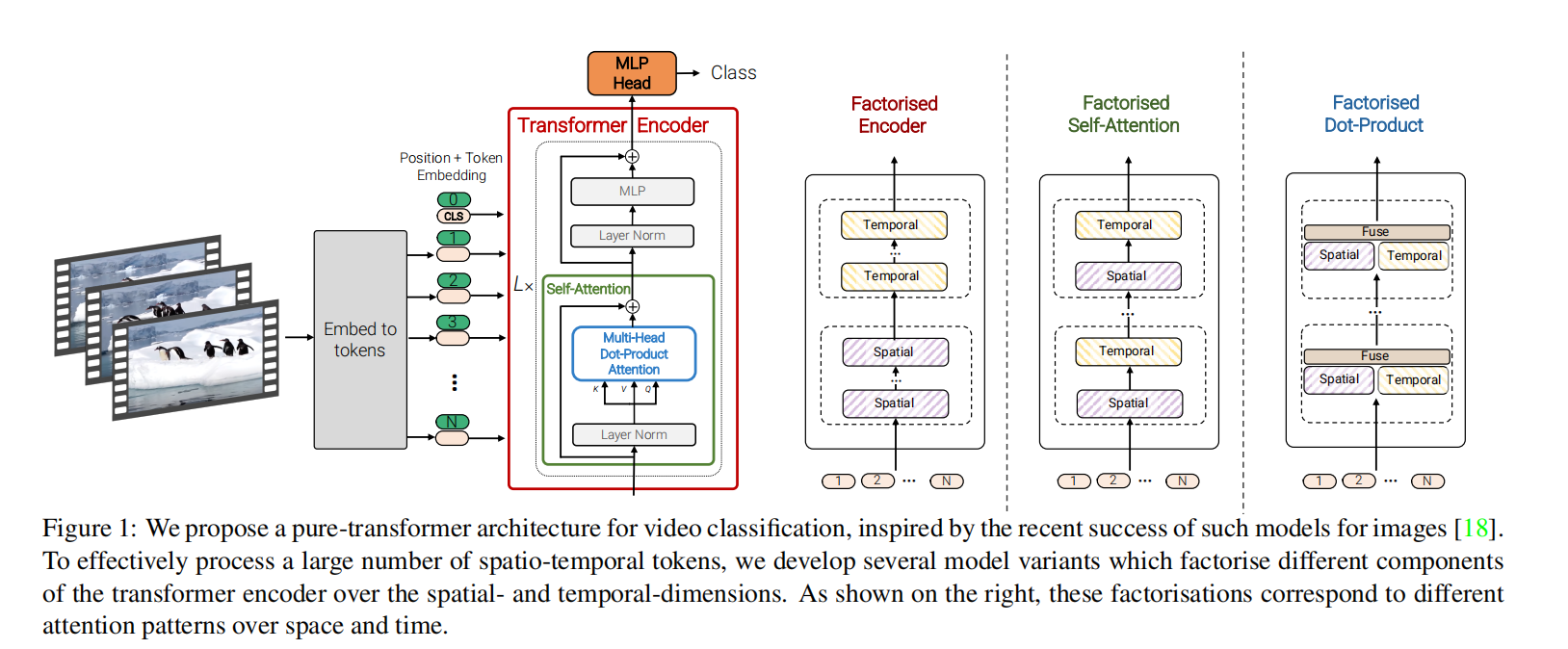
论文地址:ViViT: A Video Vision Transformer
0 divided attention
divided attention是ViViT的先验知识,它在Is Space-Time Attention All You Need for Video Understanding?这篇文章中提出,我们知道,视频区别于图片,除了空间维度,还有时间维度,如果时间维度和空间维度同时计算,由于transformer的平方复杂度,必然会带来巨大的computational cost,这篇文章作者提出,空间(spatial)和时间(temporal)两个维度分开计算attention,这样可以减少计算复杂度。具体来说,先通过计算同一位置的所有不同temporal index(或者说帧,frame)的patch之间的关系来计算temporal attention,再通过计算同一temporal index下不同时空位置的patch之间的关系来计算spatial attention得到最终输出。(在一个layer有两个multi-head-attention块)
1 Embedding video clips
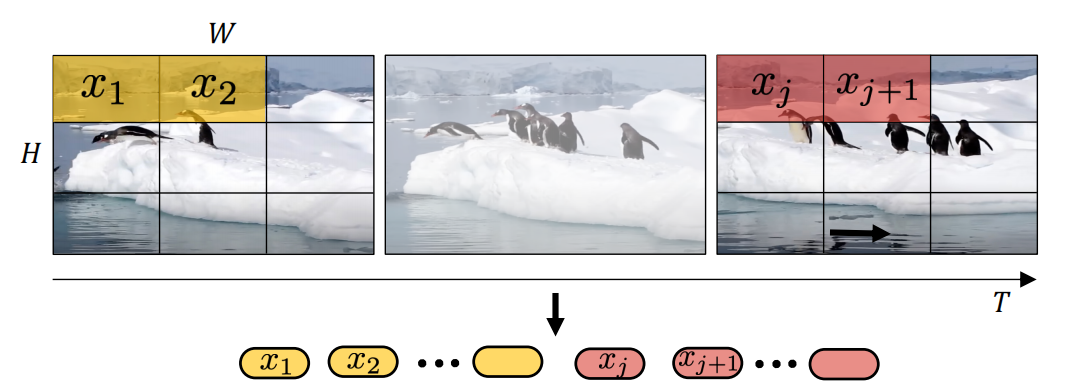
1.1 uniform frame sampling
这种方式也是在Is Space-Time Attention All You Need for Video Understanding?这篇文章中采用的tokenization的方式,假设一个样本有\(n_{t}\)帧,每个patch的长和宽为\(n_h\cdot n_w\),最终这个sample会产生\(\begin{aligned}n_t\cdot n_h\cdot n_w\end{aligned}\)个tokens,每个patch只会包含1帧的内容。具体tokenization如下图所示:
1.2 tubelet embedding
这种tokenization的方式也是ViVit采用的方式。每个token叫做一个tube,在形状上像一个管道(tube),一个patch可以包含多个帧的内容。
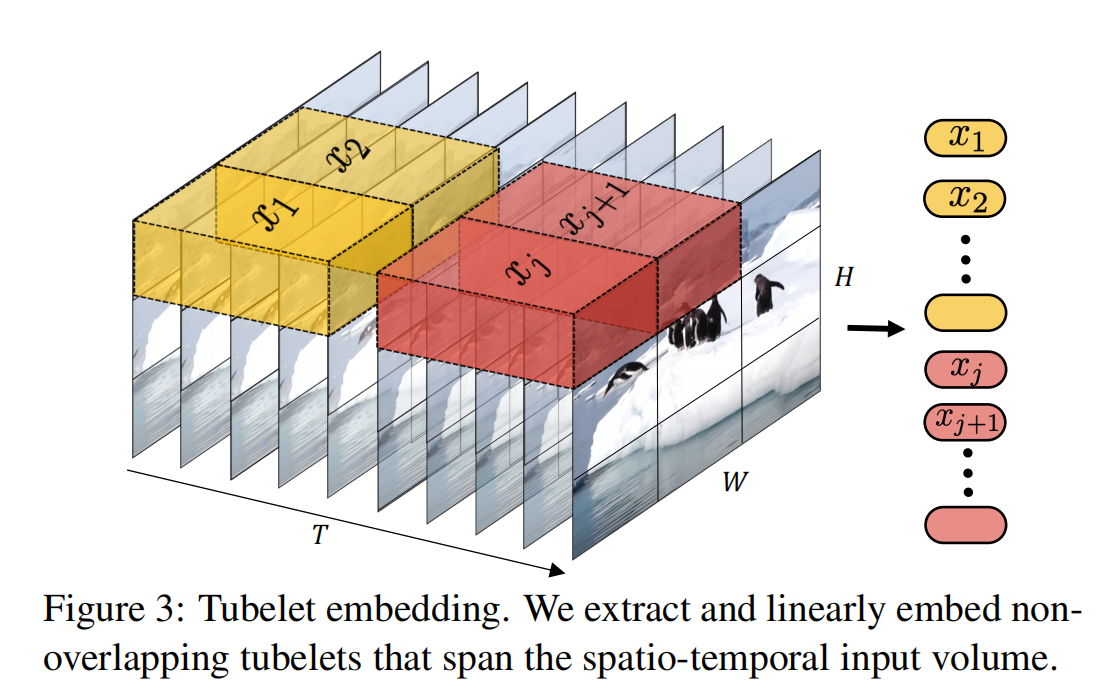
一个TxHxW的视频,我们每一个token(tube)的维度是\(\begin{aligned}t\times h\times w\end{aligned}\),那么就会产生\(\begin{aligned}n_t\cdot n_h\cdot n_w\end{aligned}\)个tokens(即sequence的长度),\(\begin{aligned}n_t=\lfloor\frac{T}{t}\rfloor,n_h=\lfloor\frac{H}{h}\rfloor\text{ and }n_w=\lfloor\frac{W}{w}\rfloor\end{aligned}\),在fig.3中,\(t=T/2\)。
值得注意的是,tubelets embedding可以在tokenize的时候就可以实现时间、空间信息的融合(因为tokens会展平成一维)。但是uniform embedding每个token是有一帧的信息,知道transformer计算的时候才会实现时间、空间信息的融合。
2 Several Transformer Models For Video Recognition
2.1 model1: Spatio-Temporal Attention
这种方式在每个layer都一次性的把所有tokens进行计算,但是transformer的计算复杂度是二次复杂度,会根据token_num按照平方速度增长,如果token多了,会带来巨大的computational costs。为了解决这个问题,作者采用了之前所说的divided-attention,设计了三种attention计算方式。
2.2 model2: Factorised encoder
分为两部分,spatial encoder和temporal encoder,每个encoder会由多个layers组成,spatial encoder会计算同一temporal index的tube之间的关系。temporal encoder会计算同一空间位置下的tubes之间的关系。

2.2.1 spatial encoder
有几个temporal index就会有几个spatial encoder,即有\(\frac{T}{t}\)个spatial encoder。经过spatial encoders,会产生\(\frac{T}{t}\)个sequence,作者这里仅用一个token代表一个sequence,有两种方式,取cls token(分类token)来代表整个token,或者通过global average pooling整个序列中所有的token得到一个token。这样\(\frac{T}{t}\)个sequence会由\(\frac{T}{t}\)个token代表,即\(\mathbf{H}\in\mathbb{R}^{n_t\times d}\)。
2.2.2 temporal encoder
spatial encoder的输出\(\mathbf{H}\in\mathbb{R}^{n_t\times d}\)每一个token就代表一个temporal index所有空间位置的集中表示,然后将\(\mathbf{H}\in\mathbb{R}^{n_t\times d}\)送进temporal encoder取model temporal dependency。值得注意的是,model2的计算复杂度是\(\begin{aligned}\mathcal{O}((n_h\cdot n_w)^2+n_t^2)\end{aligned}\),而model1的计算复杂度是\(\begin{aligned}\mathcal{O}((n_t\cdot n_h\cdot n_w)^2)\end{aligned}\)
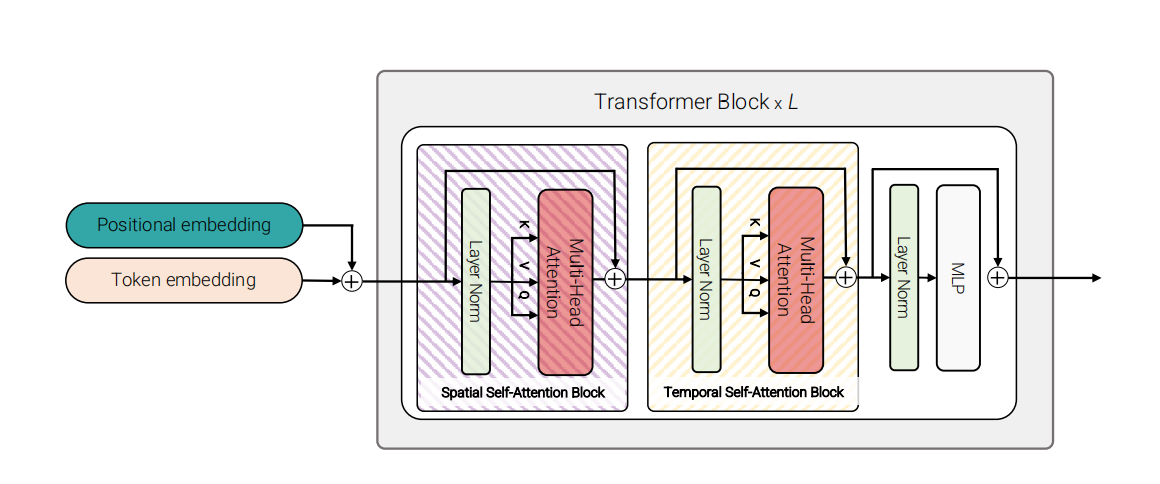
2.3 model3: Factorised self-attention
这个模型和model1有相同的layer数目。
每个layer里面包含两个self-attention块,第一个块计算同一temporal index下不同空间位置的token(tube,patch)之间的关系。第二个块计算同一空间位置下不同temporal index的token之间的关系。model3的具体实现和divided-attention一样。
在代码中,是通过矩阵变换实现的。把输入sequence从\(\mathbb{R}^{1\times n_t\cdot n_h\cdot n_w\cdot d}\)reshape到\(\mathbb{R}^{n_h\cdot n_w\times n_t\cdot d}\)去计算spatial-attention,然后reshape到\(\mathbb{R}^{n_t\times n_h\cdot n_w\cdot d}\)去计算temporal-attention(这里我感觉原论文写反了)
通过这种操作,相比于model1,大幅降低了计算复杂度,计算复杂度和model2一样。
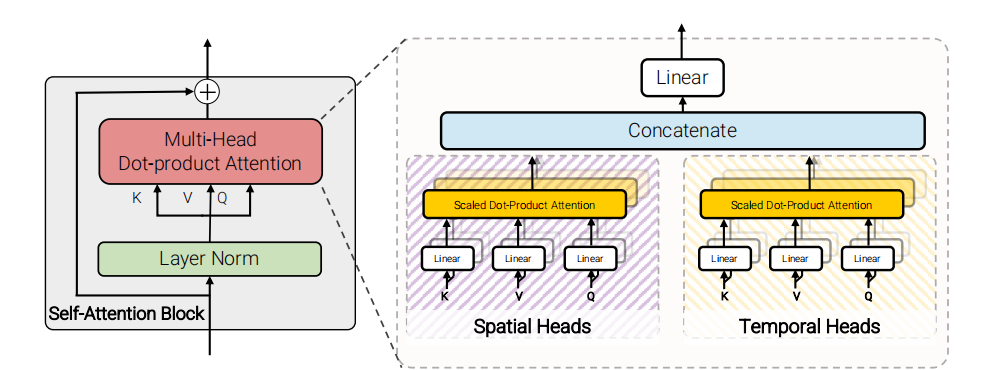
2.4 model4: Factorised dot-production attention
model3中spatial和temporal是串联的关系,但是在model4中spatial和temporal是并联的关系。transformer中,在计算attention是multi-head的,在model4中,一半的head用来计算spatial attention,另一半的head用来计算temporal attention。spatial、temporal attention共用同一套query,spatial attention的key-value:\(\mathbf{K}_s,\mathbf{V}_s\in\mathbb{R}^{n_h\cdot n_w\times d}\),temporal attention的key-value:\(\mathbf{K}_t,\mathbf{V}_t\in\mathbb{R}^{n_t\times d},\),共用的query:\(\mathbf{Q}\in\mathbb{R}^{N\times d}\)。两部分得到的输出\(\mathbf{Y}_s,\mathbf{Y}_t\in\mathbb{R}^{N\times d}\)做concat然后通过linear层。
3 Initialization by leveraging pretrained models
我们知道,由于inductive bias(归纳偏置),为了能达到和CNN一样的效果,transformer需要巨大规模的数据集的训练。但是现在的视频数据集比如Kinetics,是不够一个transformer从零开始学的(from scratch),所以说作者想在image1k上预训练过的model上通过视频数据集进行fine-tune,但是作者设计的transformer和预训练过的model在模型结构上有差异,所以作者在本节中探讨通过pre-trained的模型上的参数,来初始化作者自己创建的transformer。
3.1 positional embedding
在ViT中sequence得维度是\(\mathbb{R}^{n_w\cdot n_h\times d}\),但是在ViViT中,sequence的维度是\(\mathbb{R}^{n_t\cdot n_h\cdot n_w\times d}\),是ViT的\(n_t\)倍。在进行初始化时,作者为同样temporal index的token赋予同样的position embedding。
3.2 Embedding weights
embedding weight就是把3D(video)或者2D(image)的数据变成1D的token。在2D数据中,通过2D卷积实现,在3D数据中,通过3D卷积实现,ViT中时处理图片的,也就是2D conv,但是作者是视频数据,要把ViT中2D Conv的数据扩展成作者需要的3D conv。作者使用“inflate”(膨胀)操作,在时间维度复制2D conv,并且对他们平均化,具体来说:
\[\mathbf{E}=\frac1t[\mathbf{E}_{\mathrm{image}},\ldots,\mathbf{E}_{\mathrm{image}},\ldots,\mathbf{E}_{\mathrm{image}}].\]
还有另外一种inflate的方式:
\[\mathbf{E}=[\mathbf{0},\ldots,\mathbf{E}_\mathrm{image},\ldots,\mathbf{0}].\]
这种方式有点类似 uniform frame sampling,在初始化时只有一个帧时起作用的,但是和uniform frame sampling也有不同,因为这些0是会随着学习变化的,也就是网络会学习如何aggregate这t个frames,但是uniform frame sampling中,每个token始终只有一个帧。在后续实验中,证明第二种initialization方式效果更好。
3.3 model3中的权重初始化
model3和ViT中的encoder block不同,model3有两个self-attention block,作者用ViT得权重初始化spatial attention的权重,为temporal attention的部分赋0值
4 Experiment
作者做了许多对比实验,消融实验,和SOTA的比较,只要理解了上述内容,实验部分很简单,这里就不再赘述了,自行阅读论文。