论文地址:Multiview Transformers for Video Recognition CVPR2022
文章是基于ViViT进行改造的
1 研究背景
在图像领域,多尺度处理通过金字塔结构实现。为了视频中的时间多尺度,以前SlowFast是有了2个分支。但是使用一个金字塔结构时,时间空间信息会因为下采样会有一部分信息的丢失。比如SlowFast的Slow分支,因为采样,丢失了空间信息。在本文,作者提出了一个简单的基于transformer的网络,不使用金字塔结构或者下采样输入,来获得多尺度的时间信息。通过多尺度表征,或者说不同的输入视频views来实现。作者也通过实验证明,并行处理更多的views相比于增加网络的深度对于性能的提升更加有效
2 Multiview Transformer for Video
需要ViViT的前置知识
2.0 什么是不同的view?
在ViViT中,从一个视频中只提取一个sequence,每一个token包含的frames数量是相同的,在Multiview中,会从一个视频中提取多个sequence,每一个sequence都有一个\(n_t\),也就是从不同的view取tokenize这个视频。
2.1 Multiview tokenization
对于每个view,会提取一组tokens组成一个sequence,对于\(V\)个view,有\(V\)个序列:\(\mathbf{z}^{0,(1)},\mathbf{z}^{0,(2)},\ldots,\mathbf{z}^{0,(V)}\),\(\mathbf{z}^{\ell,(i)}\)代表经过第\(\ell\)层transformer layer处理过后的第i个view对应的输出序列。使用不同kernel size的3D卷积,来提取不同view的tokens。比较小的token可以提取更加细粒度的动作变化,比较大的token可以提取到缓慢变化的场景语义信息。
2.2 Multiview Transformer
multiview encoder,包含许多并行的transformer encoder,来分别处理不同view对应的sequence。并行的transformer encoder之间通过cross-view fusion连接
2.2.1 multiview encoder
在encoder的设计上,采用了Factorised encoder(详见ViViT)的结构,但是只计算在相同temporal index下的attention,并没有temporal transformer attention。也就是说,对于每个view,有\(n_t\)个spatial transformer attention,每个spatial transformer attention经过全局平均池化产生一个token,所以对于每个view,output是\(n_t\)个token,每一个token代表该temporal index下所有空间位置的集中表示。
2.2.2 Cross-view fusion
作者为了从精细(每个token包含的帧数少)的view向粗糙(每个token包含的帧数多)的view融合信息,开发了三种fusion的方式。
2.2.2.1 Cross-view attention
对于view i和view i+1,\(N^{(i)}\leq N^{(i+1)}\),即i所包含的token数目要少,具体图示如下:
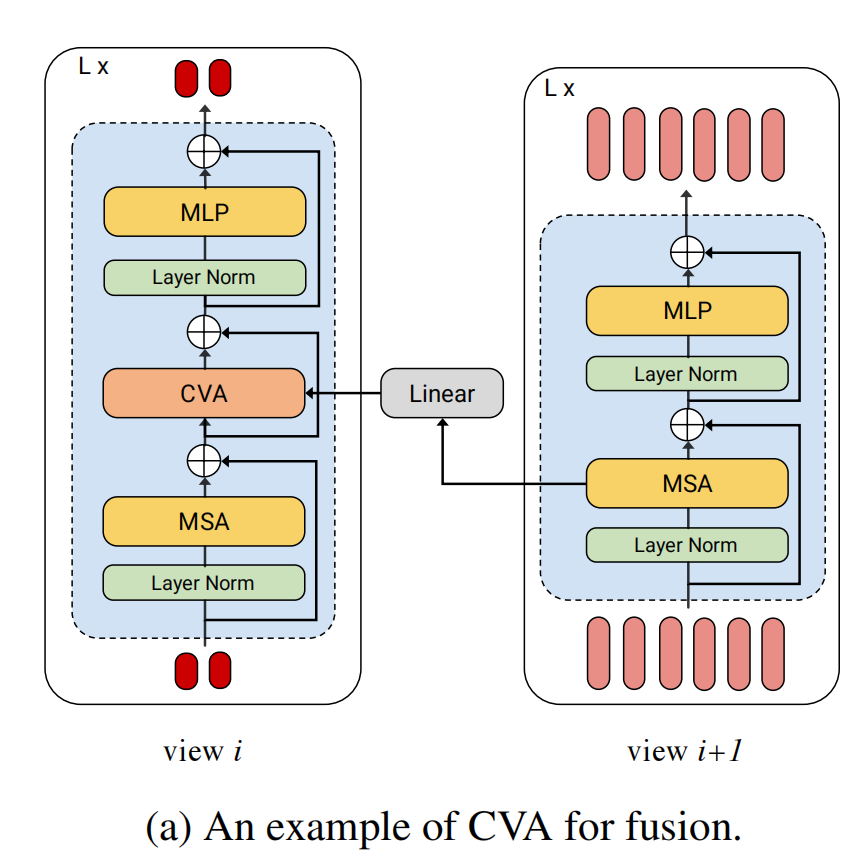
如上图所示,view i中经过residual connection的MSA的输出和view i+1中没经过residual connection的MSA的输出一起进入CVA模块,在CVA中,Query是view i的sequence,Key-Value pairs是来自view i+1的sequence,在输入进CVA中之前,要通过linear projection把view i+1的dimension \(d^{i+1}\)变为view i的dimension \(d^{i}\),这样query和key才能计算attention map。CVA模块的初始化是0,这样可以用在ImageNet上预训练的模型参数。
2.2.2.2 Bottleneck tokens
这种方式就是通过一个token来记录之前所有view的信息。具体见下图:
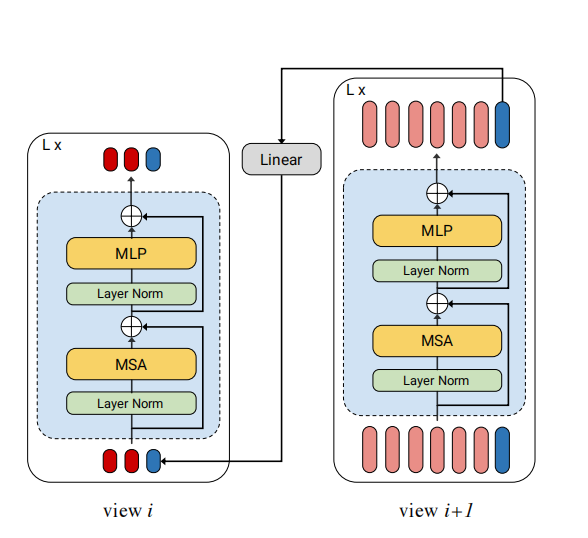
序列的最后一个token被标记为bottleneck token(上图中的蓝色token),view i+1的token会通过linear projection到view i的维度,和view i的input sequence做concat,然后依次类图,每一个蓝色bottleneck token都会记忆之前view的信息,通过bottleneck token可以实现不同view之间的信息融合。线性层的参数是随机初始化的。
2.2.2.3 MLP fusion
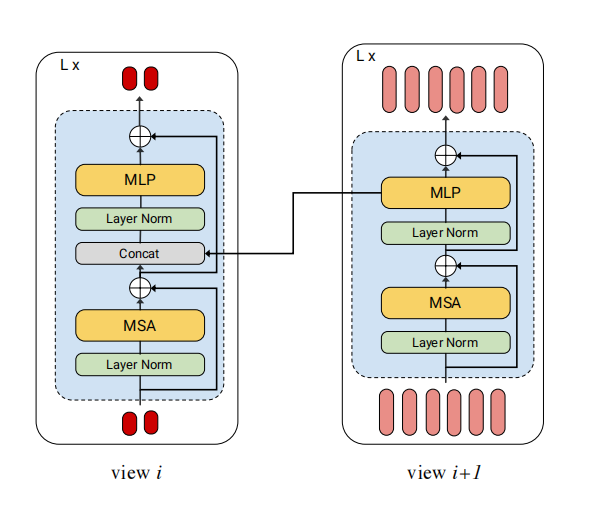
维度是\(d^{i+1}\)的来自view i+1的sequence和view i维度是\(d^{i}\)的tokens在特征维度上进行融合,构成维度是\(d^{i}+d^{i+1}\)的新tokens,然后通过MLP的projection,统一投影到\(d^{i}\).
2.2.3 Global encoder
通过最终的一个global encoder融合来自各个view的tokens。具体做法是,取每一个view的cls token,concat,然后使用一个encoder处理它们,最终产生的输出的cls token被map到C类进行分类。(C是类别的数量)global encoder的参数随机初始化。