论文地址:Multiscale Vision Transformer CVPR2021
1 introduction
在视觉领域,特征金字塔结构是一种常用的结构,即随着网络的加深,特征图的分辨率越来越小,但是特征图的深度,即channel数,越来越多。高空间分辨率的特征图具有low-level的细节信息,低分辨率的深层特征图具有high-level semantic features。传统的trnasformer,每一层的通道容量(channel capacity)都保持一致,作者以金字塔结构为启发,对transformer进行改造。在本论文中,作者认为tokens的数量被看作分辨率,\(d_{model}\)认为是channel 数量
本文的研究范畴主要是视频识别,但是在最后也做了图像分类的相关实验
2 Multiscale Vision Transformer(MViT)
2.1 Multi head pooling attention
与multi head self-attention不同,数据在经过multi head pooling atteniton之后,sequence length会变少,在transformer结构中,sequence length是由query的数量决定的。
输入数据\(\begin{aligned}X\in\mathbb{R}^{L\times D}\end{aligned}\),通过linear projection产生intermediate query,key-value:
\[\hat{Q}=XW_Q\quad\hat{K}=XW_K\quad\hat{V}=XW_V\]
Pooling Operator pooling kernel可表示为:\(\boldsymbol{\Theta}:=(\mathbf{k},\mathbf{s},\mathbf{p})\),其中kernel size \(\mathbf{k}\):\(k_T\times k_H\times k_W\),stride \(\mathbf{s}\):\(s_T\times s_H\times s_W\), padding \(\mathbf{p}\):\(p_{T}\times p_{H}\times p_{W}\)。对于序列长度为\(\mathbf{L}=T\times H\times W\)经过pooling之后,变为:
\[\mathbf{\tilde{L}}=\lfloor\frac{\mathbf{L}+2\mathbf{p}-\mathbf{k}}{\mathbf{s}}\rfloor+1\]
作者在论文里提到,使用了overlapping kenel还有shape preserving padding,所以最后length的变化只由\(s_T\times s_H\times s_W\)决定
对产生的intermediate query,key-value:\(\hat{Q} \hat{K} \hat{V}\),使用pooling operator,得\(\tilde{Q}=\mathcal{P}({\hat{Q}};\boldsymbol{\Theta}_Q),\)\(K=\mathcal{P}(\hat{K};\boldsymbol{\Theta}_{K})\mathrm{and}V=\mathcal{P}(\hat{V};\boldsymbol{\Theta}_{V})\),新得到的q,k,v就是序列长度缩短之后的。
总体来说,计算过程如下:
\[\mathrm{PA}(\cdot)=\mathrm{Softmax}(\mathcal{P}(\hat{Q};\boldsymbol{\Theta}_Q)\mathcal{P}(\hat{K};\boldsymbol{\Theta}_K)^T/\sqrt{d})\mathcal{P}(\hat{V};\boldsymbol{\Theta}_V),\]
图示:
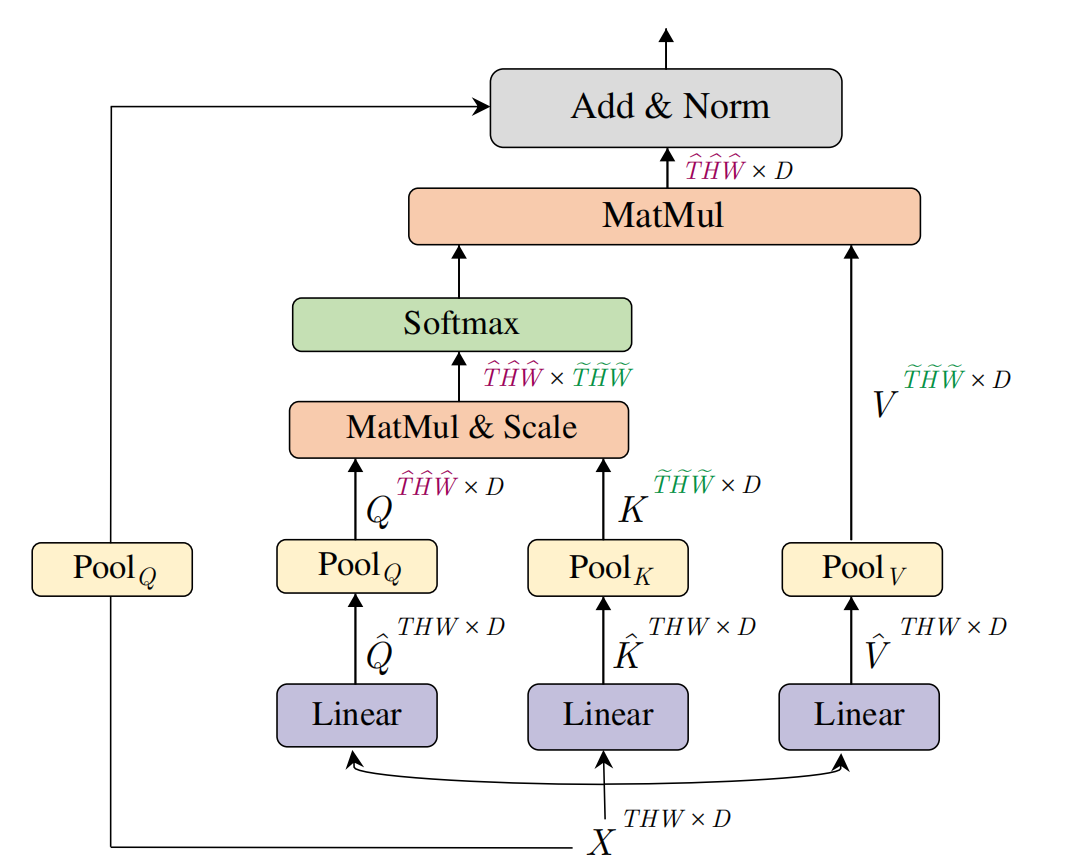
值得注意的是,在残差连接上加入了pooling操作,因为input X和输出尺寸不一样,需要pooling调整尺寸才能相加。
2.2 multiscale vision transformer networks
2.2.1 scale stages
每一个scale stage由n个transformer block组成,每一个scale stage内的数据都具有相同的分辨率,随着stage的变化,channel数变多,resolution变小。
2.2.2 channel expansion
channel expansion就是增大token的维度,作者在每一个scale stage之间使用mlp进行channel expansion
2.2.3 Query pooling and Key-value pooling
query pooling:
transformer中输出的sequence length是由query的数量决定的,作者设计的tranformer在每一个scale stage内部,sequence length是不变的,所以在每一个scale stage里第一个transformer layer的pooling stride为\(\mathbf{s}^{Q}>1\),其他layer的pooling stride为\(\mathbf{s}^Q\equiv(1,1,1).\)
key-value pooling:
key value的sequence length和output的sequence length是无关的,但是在transformer中,key value的sequence length必须保持一致才能计算,所以要保证在每一个scale stage内:\(\Theta_K\equiv\Theta_V\)