论文地址:Deep Texture-Aware Features for Camouflaged Object Detection
1 总览
通过学习纹理相关的特征,增大伪装目标和背景之间细微的差别,来更好的发现伪装目标。作者通过计算特征的协方差矩阵提取纹理特征,设计了相似度损失去学习参数图来放大背景和伪装目标之间的细微差异,用边缘一致性损失去完善物体的细节特征。
2 Methodology
2.1 Overall Architecture
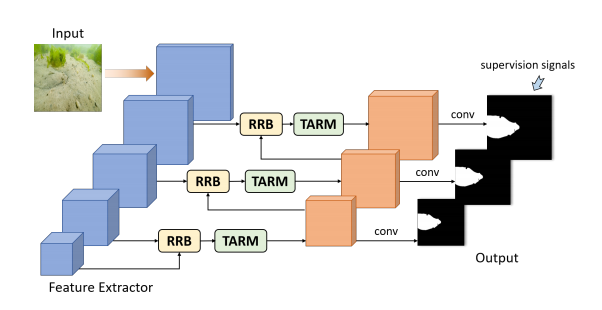
上图是总体网络架构,在原论文中,作者使用ResNetX50作为backbone,对于每一层的side output,首先经过residual refine blocks(RRB)去精细化(目的是增强细节,去除背景噪声,但是在原论文中对于这个blocks没有具体解释),然后通过TARM学习纹理特征并根据学习到的纹理特征扩大背景和伪装目标之间的差异,在进行predicate,然后选取分辨率最高的那一个prediction map作为最终预测结果。
2.2 Texture-Aware Refinement Module
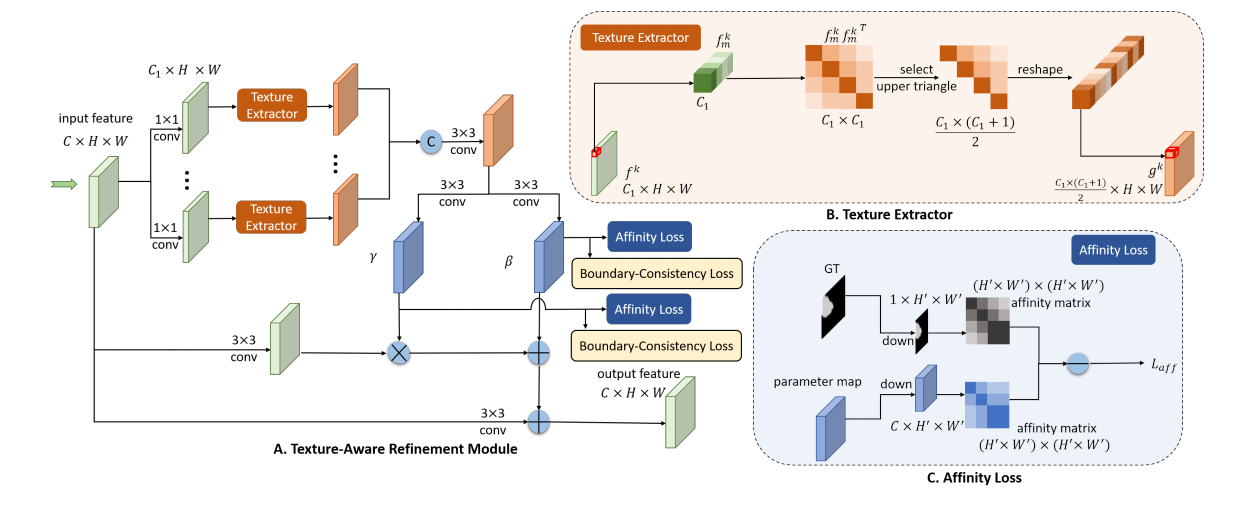
- 计算纹理特征:首先feature map通过若干个1×1卷积层得到不同种类的特征图,并且为了节省计算,特征图的通道数量是要小于原本特征图的,对于得到的每一个种类的特征图,计算协方差(Texture Extractor),计算过程是:计算每一处像素点所有通道位置之间的协方差,会得到\(C_1\times C_1\)的矩阵,由于对称性,只保留上三角矩阵\(\frac{C_1\times(C_1+1)}2\),对于每一个\(\begin{aligned}g^k\in\frac{C_1\times(C_1+1)}2\end{aligned}\),其包含了纹理特征信息,计算协方差之后,就会得到\(\frac{C_{1}\times(C_{1}+1)}2\times H\times\bar{W}\)的包含纹理特征信息的特征图,然后将这些特征图concat之后通过3×3的卷积层进行融合。
- 通过参数图(parameters map)放大背景和伪装目标之间的差别:3×3的卷积作用在刚刚得到的特征图,分化得到两个parameter maps,分别是\(\gamma\)和\(\beta\),空间尺寸是\(\begin{aligned}C^{\prime}\times H\times W\end{aligned}\),它们通过调整输入特征\(f_in\)(图中的input feature),来放大伪装目标和背景之间的微小差别,具体计算方式见下式,其中\(f_{i\textit{n}} ^ { ‘}\)是经过3×3卷积之后的input feature,\(\mu(f_{in}^{‘})\)和\(\sigma(f_{in}^{‘})\)是均值和方差,通过计算式子可以看出,计算过程类似于根据得到的纹理特征将input feature进行batch normalization和affine。
\[f_{out}=conv(\gamma\frac{f_{in}^{‘}-\mu(f_{in}^{‘})}{\sigma(f_{in}^{‘})}+\beta)+f_{in},\]
如何学习parameter maps? 可以通过对predication map的supervision去反向传播学习parameter,去学习如何更好地扩大更好地扩大背景和前景的细微差别,但更直接的方式就是直接对parameter maps进行supervise,更直接地让parameter maps学习如何更好地增大背景和伪装目标之间的细微区别。作者通过Affinity Loss(相似度损失)对parameters进行监督,过程如下:
- 对于两个parameter maps:先下采样(downsample),然后计算相似度矩阵,\(h_m\)和\(h_n\)是parameter maps中每一个像素点对应的向量。\(A_h\)是最终得到的矩阵,它表示了像素点之间的纹理相似度,
\[A_{m,n}^{h}=\frac{h_{m}^{T}h_{n}}{\parallel h_{m}\parallel_{2}\parallel h_{n}\parallel_{2}},\]
- 对于Ground Truth:通过如下方式计算相似度损失,\(\mathbb{1}_{C_m=C_n}\)当m和n处的label相等时为1,否则为0;通过如下计算,会得到一个只有1和-1的GT相似度矩阵。
\[A_{m,n}^{gt}=2\times\mathbb{1}_{\{C_m=C_n\}}-1,\]
- Affinity Loss:\(A^{gt}\)就是要学习的目标结果,\(A^{h}\)就是要优化的对象,要把\(A^{h}\)通过affinity loss学习成\(A^{gt}\),其中\(w_{m}=1-\frac{N_{Cm}}{H^{\prime}W^{\prime}}\),\(w_{n}=1-\frac{N_{Cn}}{H^{\prime}W^{\prime}}\),\(N_{C_m}\)是和m具有同样label的像素的数量,\(N_{C_n}\)同理,这样可以解决前景和背景像素数量差异过大导致的问题。
\[L_{aff}=\sum_m\sum_nw_mw_nd(A_{m,n}^h,A_{m,n}^{gt}),\]
通过上述loss function,参数图可以学会如何扩大纹理差异。
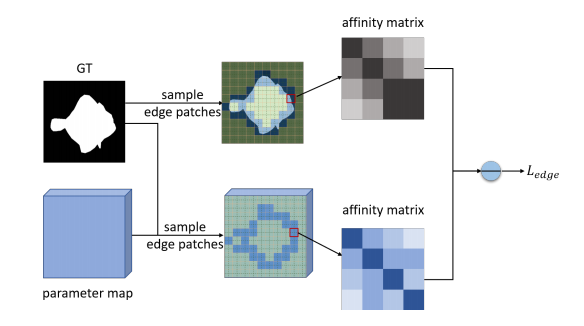
2.3 Boundary-Consistency Loss
因为parameter loss的affinity loss是经过downsample的,所以分辨率较小,如果直接得到prediction map,在边缘细节部分会很模糊,为了增强边缘与细节,引入边缘一致性损失\(L_{edge}\),它会再次考量(revisit)预测图的边缘区域。
\[L_{edge}=\sum_{\forall i,b_i\in\mathcal{B}}\sum_{m,n\in b_i}d(A_{m,n}^{h},A_{m,n}^{gt}),\]
其中\(b_i\)是\(\mathcal{B}\)里的第i个图像patch,\(\mathcal{B}\)是和边缘区域有关的所有patches,值得注意的是,\(L_{edge}\)是在没有经过downsample的parameter maps上进行计算的,这样,有了更高的分辨率,就可以提供更多的细节信息,并且计算复杂度可以接受,因为只计算了和边缘区域有关的图像patches
2.4 Overall loss function
\[L=\lambda_{0}L_{seg}+\lambda_{1}L_{aff}+\lambda_{2}L_{edge},\]
3 Summary
本文的核心是两个,一个是通过纹理特征来扩大背景和伪装目标之间的差异,另一个是通过affinity loss去学习如何更好地扩大差异,BC Loss去学习边缘细节信息。
- 通过covariance计算texture features,借此得到parameter maps \(\gamma\)和\(\beta\),并根据它们去扩大背景和伪装目标之间的差异。
- 先计算parameter maps和Ground Truth的相似度矩阵(注意优化的相似度矩阵,而不是直接优化\(\gamma\)和\(\beta\),因为\(\gamma\),\(\beta\)是特征,与Ground Truth有很大的语义差距,直接优化它们是不合理的,通过优化相似度可以解决这一问题),然后计算affinity loss。
- 因为affinity loss是在低分辨率的图上进行的,所以可能会缺少很多细节信息,因此提出了Boundary-Consistency Loss去在没经过downsample的parameter maps进行计算,但是只计算与边缘有关的区域,这样可以丰富细节信息。