论文地址:CamoFormer: Masked Separable Attention for Camouflaged Object Detection
1 研究动机
现在的伪装目标识别的模型都没有把前景和背景分开处理,这就很难从相似的环境中识别出伪装目标,现在的目标,关键就是分别encode前景和背景。受到Masked Multi-Head Attention的启发,作者设计了masked separable attention(MSA),每一个head负责特定的功能,一个head处理前景,一个head处理背景,一个head处理前景和背景的交融。
2 CamoFormer
2.1 Overall Architecture
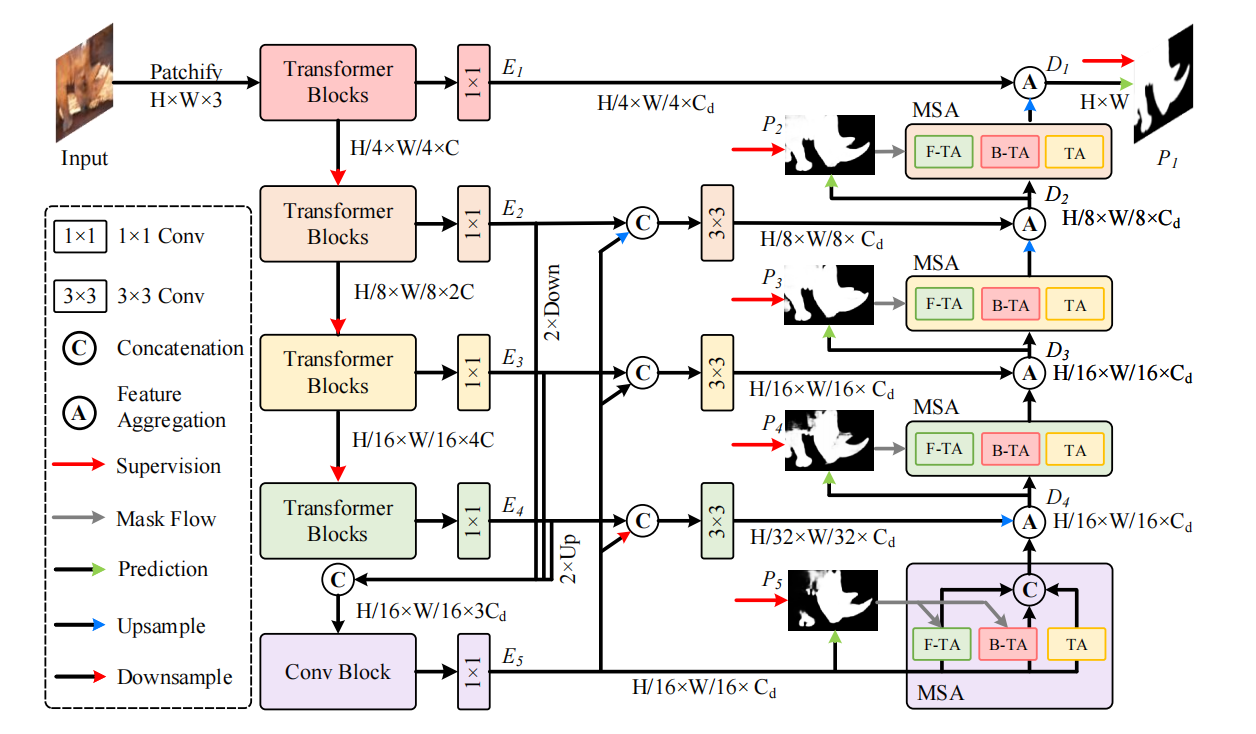
2.1.1 Encoder
采用PVTv2作为encoder,产生四个阶段(尺寸)的特征图,并将最后三个阶段的特征图聚合,然后通过一个Conv产生高语义信息表达\(E_5\)
2.1.2 Decoder
采用渐进的,自下而上的逐渐优化特征的方式去进行decode,对于最开始产生的aggregated feature,方式如下:
\[D_4=\mathrm{MSA}(E_5)\cdot\mathcal{F}_{\mathrm{up}}(E_4)+\mathcal{F}_{\mathrm{up}}(E_4),\]
对于后续aggregated feature的产生:
\[D_i=\mathcal{F}_{\mathrm{up}}(\text{MSA}(D_{i+1}))\cdot E_i+E_i.\]
住得注意的是,作者在聚合特征的时候并没有直接进行相加操作或者concat,而是先把\(D\)和\(E\)进行element-wise相乘,在进行相加,作者发现通过这种方式,性能可以提升0.2%。
2.1.3 Loss Function
图中的全红箭头就是supervision,从图中可以看出,作者对不同层级decoder产生的prediction都进行了监督,\(\{{P_{i}}\}_{i=1}^{5}\)就是5个层级产生的prediction map,\(G\)是Ground Truth。Loss Function如下:
\[\mathcal{L}(P,G)=\sum_{i=1}^5\mathcal{L}_{bce}(P_i,G)+\mathcal{L}_{iou}(P_i,G),\]
2.2 Masked Separable Attention
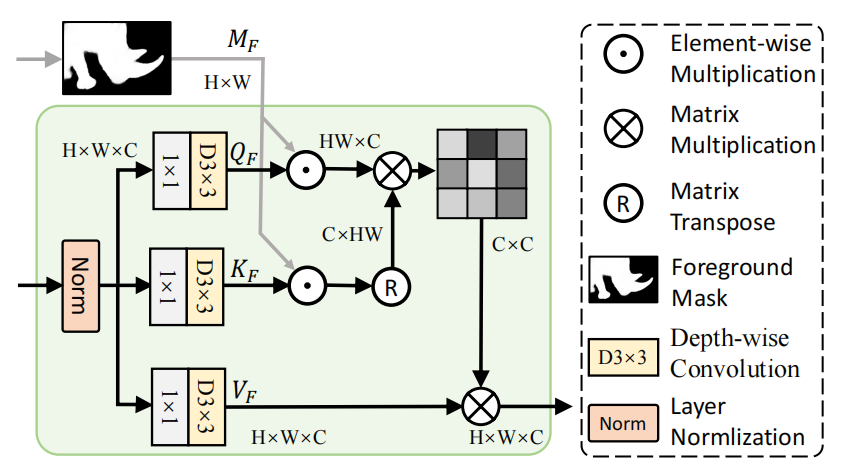
作者将attention heads分为3组,T-BA,F-TA(Foreground head),B-TA(Background head)。
对于F-TA:
\[\text{F-TA}(\mathbf{Q}_F,\mathbf{K}_F,\mathbf{V}_F)=\mathbf{V}_F\cdot\mathrm{Softmax}(\frac{\mathbf{Q}_F^\top\mathbf{K}_F}{\alpha_F}),\]
其中\(\mathbf{Q}_F\)和\(\mathbf{K}_F\)就是经过mask之后的query和key,它们是通过query,key与mask(prediction map,就是上一层aggregated feature预测得到的)相乘得到的,Value没有经过mask处理,这样以来,F-TA可以只关注前景区域,避免了背景区域的一些污染性信息,同样的,在B-TA里同样的操作,用\(\begin{aligned}M_{B}&=1-M_{F}\end{aligned}\)作为mask:
\[\text{B-TA}(\mathbf{Q}_B,\mathbf{K}_B,\mathbf{V}_B)=\mathbf{V}_B\cdot\text{Softmax}(\frac{\mathbf{Q}_B^\top\mathbf{K}_B}{\alpha_B}).\]
第三组head是TA,它就是普通的attention,可以建模前景和背景之间的信息交流。
\[\mathrm{TA}(\mathbf{Q},\mathbf{K},\mathbf{V})=\mathbf{V}\cdot\mathrm{Softmax}(\frac{\mathbf{Q}^{\top}\mathbf{K}}{\alpha}),\]
3 Experiments

上图是不同stage的decoder的attention的热力图,从热力图可以看出,F-TA关注前景,B-TA关注背景,TA实现背景前景的融合。此外,\(D_2\)相较于\(D_5\),热力图的颜色更加鲜艳明显,轮廓更加明朗,说明progressive refinement起到了作用。