
论文地址:Weakly-Supervised Camouflaged Object Detection with Scribble
1 Introduction
在这篇文章中,作者提出了第一个弱监督的COD模型,它仅使用简笔画(Scribble Annotations)作为监督。总体来说,作者设计了:
- LCC模块用来模拟人眼的视觉抑制,即抑制一些区域来增强图片的对比度,更容易发现伪装目标
- LSR模块来决定、发现最终的伪装目标所在的区域
- Feature-guided Loss,用来弥补弱监督缺少label的处境
- Consistency Loss,用来增强图像变换(crop、rotate)后预测图的一致性和每张预测图的像素见的一致性
2 Model Architecture
2.1 Local-Context Contrasted (LCC) Module
由于伪装后的物体通常与背景非常相近,在低级特征(纹理,颜色,强度)上肯能会很相近,因此不容易注意到不明显的差异。LCC模块的作用就是捕捉和增强低等级的差异。
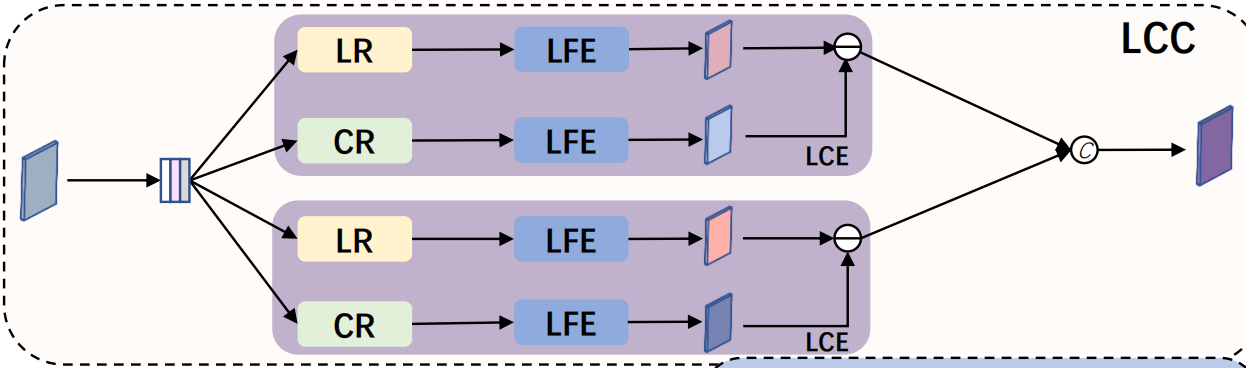
LCC由两个stacked的LCE组成,每个LCE由Local Receptor(LR)、Context Receptor(CR)、low-level feature extractor(LFE)组成,
其中LR是1膨胀率的3×3卷积,CR是\(d_{context}\)膨胀率的3×3卷积,特征通过LR、LFE会得到\(F_{local}\),是相对于比较local的特征通过CR、LFE会得到\(F_{context}\),是相对于比较global的特征,上下文更加丰富。\(F_{local}\)和\(F_{context}\)相减得到\(F_{contrast}\),是增强低等级特征差异后的特征。两个LCE的不同之处是\(d_{context}\)不同,一个是4一个是8。
2.2 Logical Semantic Relation (LSR) Module
scribble只能注释背景的一部分。当背景由许多低水平的对比部分组成时(例如,绿色的叶子和棕色的树枝,黄色的花瓣和绿色的茎) ,我们需要逻辑语义关系信息来识别真实的前景和背景。
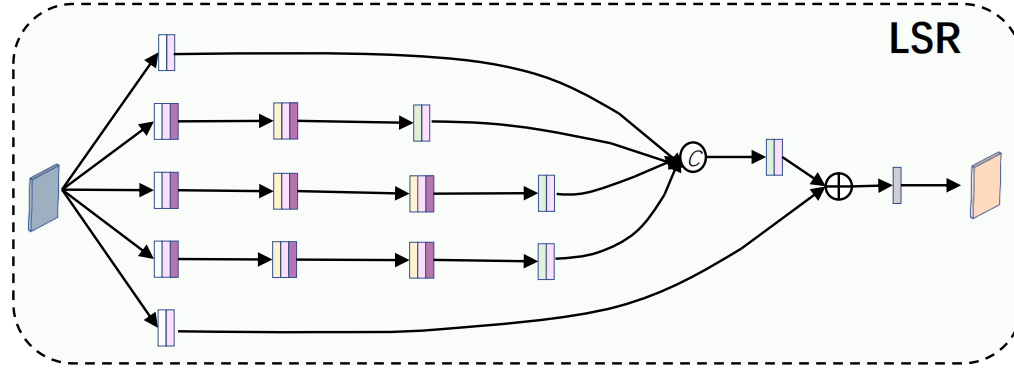
LSR从四个branches上提取特征,每个branch由一系列不同kernel size和膨胀率的卷积层,然后把他们融合起来,充分利用特征。
2.3 Overall Architecture
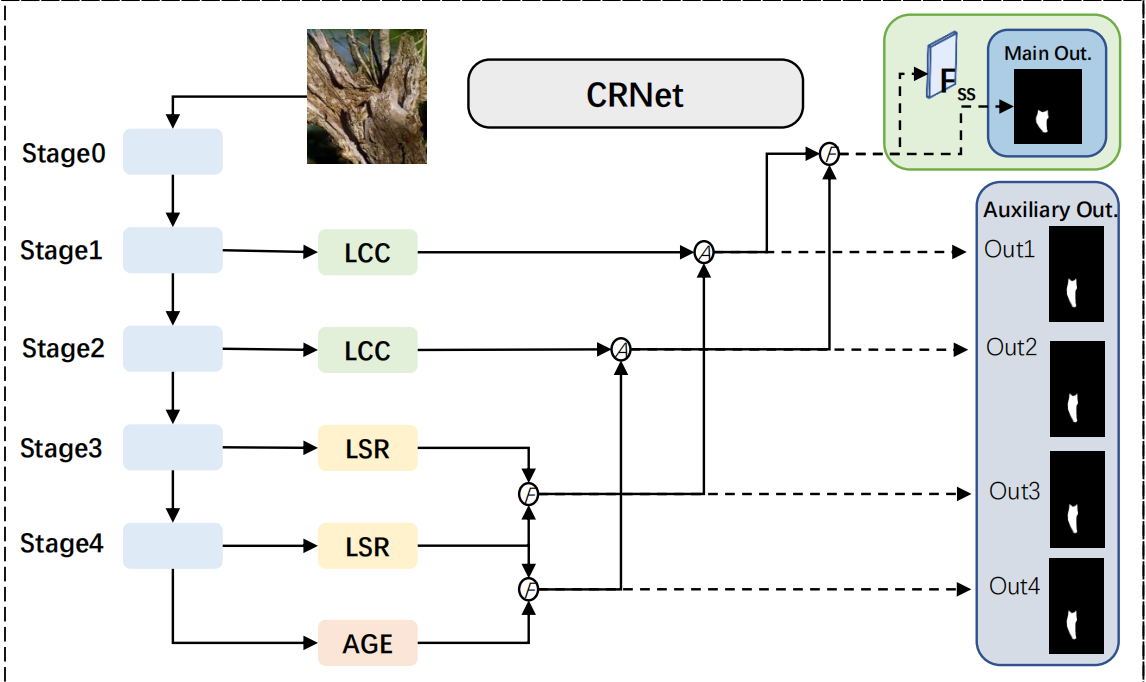
3 Loss Design
3.1 Feature-guided Loss
因为scribble-based方法是缺少物体信息的,所以需要依靠颜色、位置等来获取探索label提供不了的信息。但是在COD中,这些特征不再是一个很好的线索来找伪装目标,通常需要一些高级语义信息来帮助判断。
*Context Affinity Loss
邻近的、具有相似特征的像素倾向于有相同的类别。这里的相似特征都是直观的,比如颜色,位置,所以叫做visual feature similarity:
\[K_{vis}(i,j)=\exp(-\frac{||S(i)-S(j)||^2}{2\sigma_{S}^2}-\frac{||C(i)-C(j)||^2}{2\sigma_{C}^2}),\]
S是像素的位置,C是像素的RGB值。下述式子中,D(i,j)是i,j像素具有不同标签的概率,P是具有正预测的概率
\[D(i,j)=1-P_iP_j-(1-P_i)(1-P_j),\text{(2)}\\L_{ca}=\frac{1}{M}\sum_{i}\frac{1}{K_{d}(i)}\sum_{j\in K_{d}(i)}K_{vis}(i,j)D(i,j),\text{(3)}\]
*Semantic Significance Loss
在COD中,伪装目标的边缘通常伪装的很好,通过上文中的直观特征不好区分,因此需要一些高级语义信息来帮助判别,高级语义信息中那些帮助区分边缘的信息变得尤为关键,这个Loss就是用来找到这些“significant”的高级语义信息,来更好的帮助分割边缘。因此设计了SS Loss去refine边缘的预测。这个Loss被用来refine边缘预测,所以只作用于边缘区域,而且非边缘区域,Context Affinity Loss已经能很好地优化了。作者将图片分块,只有块中至少有30%的像素被自信地(概率超过0.8)预测为前景或背景才能称之为boundary-region。
首先计算的是Significance,“重要程度”,用来衡量feature map的的各个channel对分割边缘的重要程度:
\[Sig_i=cov'(F_{ss_i},P),i\in\{1,…,C\},\]
其中\(F_{ss}\)是最终预测层之前的那一层的特征,重要程度是由\(F_{ss}\)的每一个channel\(F_{ss_i}\)与prediction map的协方差决定的。prediction map中只有充分预测(预测值大于0.8)的像素参与计算。根据协方差得出的这种相关性,可以判断哪个channel对于boundary的判断更加有帮助一些。
通过\(Sig_i\)可以筛选出那些比较重要的channel,作者将channel按照\(Sig\)进行排序,选取前N=16个channel参与计算,计算方式类似于Context Affinity Loss:
\[\begin{aligned}
K_{sem}& \begin{aligned}=\exp(-\frac{||S(i)-S(j)||^2}{2\sigma_S^2}-\frac{||\hat{F_{ss}}(i)-\hat{F_{ss}}(j)||^2}{2\sigma_C^2}),\end{aligned} \\
&\text{(5)} \\
L_{ss}& =w_{ss}\frac{1}{M}\sum_{k}\frac{1}{|R_{k}|}\sum_{i,j\in R_{k}}K_{sem}(i,j)D(i,j),\quad(6)
\end{aligned}\]
和Context Affinity Loss不同的是,\(K_{sem}\)是在高级语义空间中判断的相似度,而不是直观的颜色间的相似度。
这两个loss的和构成feature guided loss
\[L_{ft}=L_{ca}+L_{ss}.\]
3.2 Consistency Loss
弱监督的方法通常有不一致的预测的问题,比如说,一张图片与它的transform(裁剪,翻转)等可能会有不同的输出,所以采用Cross-View Consistency Loss来减少这种不一致性。此外,由于COD中背景和前景之间的视觉相似性,预测往往具有不确定性,作者设计了inside-view consistency loss来提高预测的稳定性。
*Cross-View Consistency Loss
这个loss的作用就是让图片及它的transform的输出朝互相发展,原文中说的是“push them towards each other”。
\[Sm(p_1,p_2)=\frac{1-SSIM(p_1,p_2)}{2},\\L_{cv’}(P_1,P_2)=\frac{1}{M}\sum_{i}(1-\alpha)\cdot Sm(P_{1_i},P_{2_i})+\alpha|P_{1_i}-P_{2_i}|,\]
SSIM是衡量两个图片的相似度,\(p_1,p_2\)是两个像素,\(i\)是pixel index,M是像素总数。作者在这里做了特殊处理,想让transformed图片\(\hat{P}\)比没被transformed图片\(P\)被“push”地多一些,作者将反向传播的梯度加了不同的权重来解决这一问题。
\[L_{cv}=(1+\gamma)L_{cv^{\prime}}(P^d,\hat{P})+(1-\gamma)L_{cv^{\prime}}(P,\hat{P}^d)\]
\(P^d,\hat{P}^d\)和\(P,\hat{P}\)有相同的值,但是没有梯度,当\(\gamma\)>0的时候,\(\hat{P}\)就会比\(P\)被push的多一些。
*Inside-View Consistency Loss
这个loss就是鼓励那些被confidently predicted的像素更加地被自信地预测。作者通过降低它们的熵来提高他们的预测自信度。
\[L_{iv}=w_{iv}\cdot\frac{1}{|I-\mathcal{B}|}\sum_{(i)\in I-\mathcal{B}}-P_i\log P_i-(1-P_i)\log(1-P_i),\]
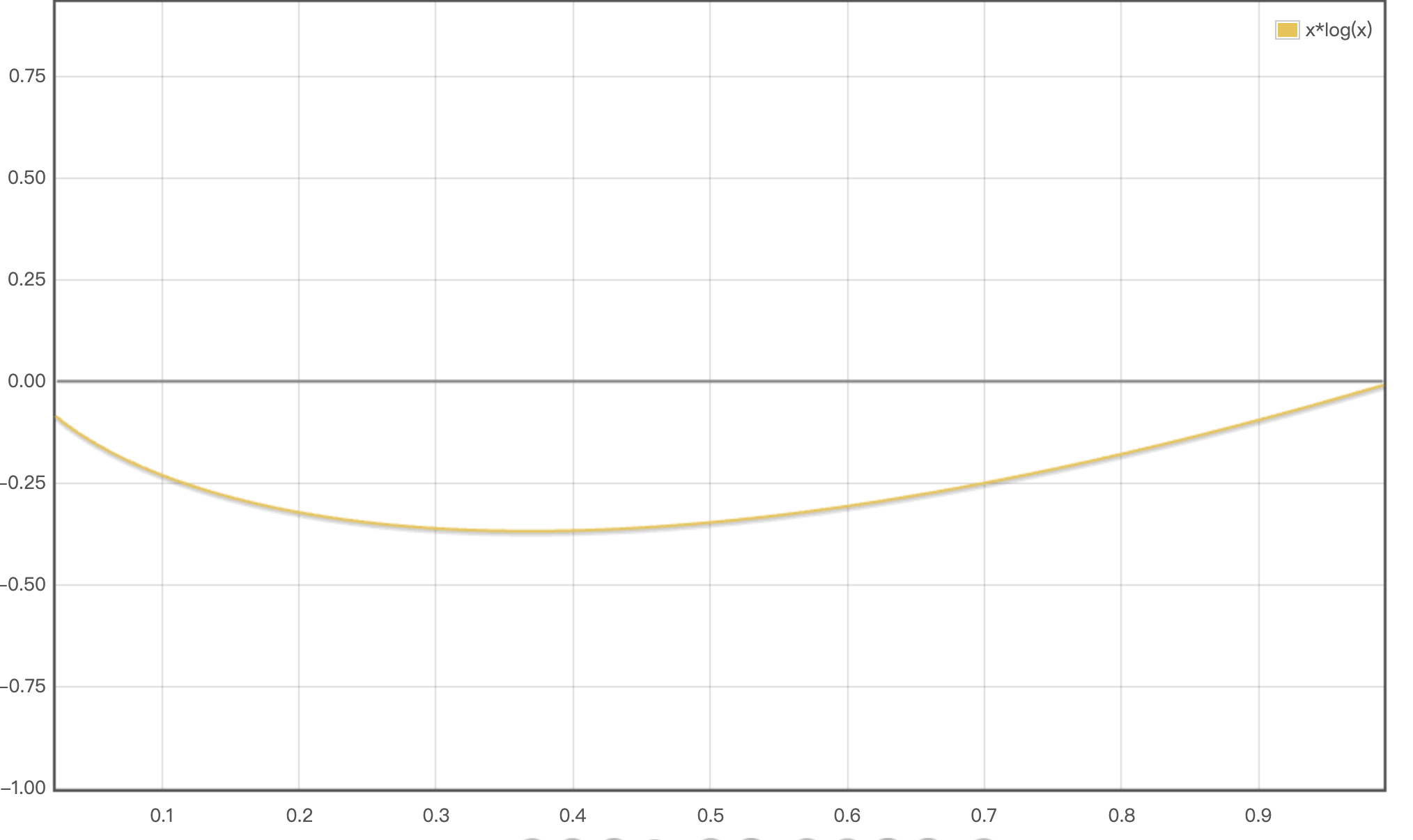
这个是xlog(x)的函数图像,可以看出两头的绝对值(熵)低,中间的绝对值(熵)高
作者设置了一个阈值,那些熵非常高的像素是预测非常不自信的像素,降低它们的熵值对模型的预测效果是有损害的。
这两个loss的和构成Consistency loss:
\[L_{cst}=L_{cv}+L_{iv}\]
3.3 PCE Loss
这个就是传统的全监督方法中的label和prediction之间的loss。
\[L_{pce}=\frac1N\sum_{i\in\tilde{P}}-y_i\log\hat{y}_i-(1-y_i)\log(1-\hat{y}_i),\]
\(y_i\)是真实标签,只不过很少,因为是scribble标注的。
3.4 Loss Allocation
对于output P,适用所有的损失函数,对于auxiliary outputs \(P_{1…4}\),只计算PCE、inside-view,context affinity loss,整个model的loss function如下:
\[L=L_{cst}+L_{ft}+L_{pce}+\sum_{i=1}^{4}\beta_{i}L_{aux}^{i},\]
4 Thinkings
本论文的主要贡献是提出了COD第一个弱监督方法和多样的loss function。Scribble提供的label少之又少,大部分像素的label是未知的,如何利用这些仅有的少数的labeled pixel去预测那些未知的pixel呢?作者设计了Feature-guided loss,这个loss不是计算label和predcition之间的,而是计算prediction内部的像素之间的,相当于一种扩散,认为具有相似特征(无论是低级的还是高级的)的像素应该具有相同的class,根据这一原理进行扩散,用已知的像素去预测未知的像素。同时inside-view consistency loss让那些被自信预测的像素更加地自信。提高了模型的稳定性。