论文链接:Open-Vocabulary Camouflaged Object Segmentation
1 introduction
现在的伪装目标检测主要集中在预定义的封闭集场景上,其中所有的语义概念都在推理和训练阶段被看到,但是这过度简化了真实世界的复杂性,因此,作者提出了一个新的方向,开放词汇环境下的伪装目标检测,Open-Vocabulary Camouflaged Object Segmentation(OVCOS)。
open-vocabulary就是让模型能够识别训练集中没有的全新类别,其关键就是对其图像和语言特征(注意,不是完全开放,不是让模型模型没有任何信息的情况下预测一个新的类,在测试的时候,测试集可能的类别都已经限定死了,模型在测试时要根据测试图片从中选出最可能的类别,但是这些类别在训练时没遇到过)。由网上具有丰富概念、带有噪声的、多样的数据训练的CLIP,表现出惊人的open-vocabulary的能力,作者因此以CLIP为基石,专门为OVCOS任务开发了OVCoser,利用其强大的图片文字匹配和解读能力创造了一个强大的OVCOS的基线。
2 Methodology
2.1 overall framework
首先把RGB图片输入进CLIP的Visual Encoder,得到multi-scale visual features。类别集class set会经过camopromts处理得到为伪装场景专门生成的类别描述,送进textual encoder里得到类别的文本特征(类别文本嵌入);multi-scale visual features会和depth map、edge map一起送进iterative Refinement Decoder里去,伴随着correlation matrix的校准,逐步产生最终的分割图;最后,来自multi-scale visual features的最高级特征和最终分割图做MAP,送进visual embedding layer,生成图像嵌入,然后类别文本嵌入和图像嵌入做similarity计算,得到cls_logtis,得到图片在每个类别上的得分。
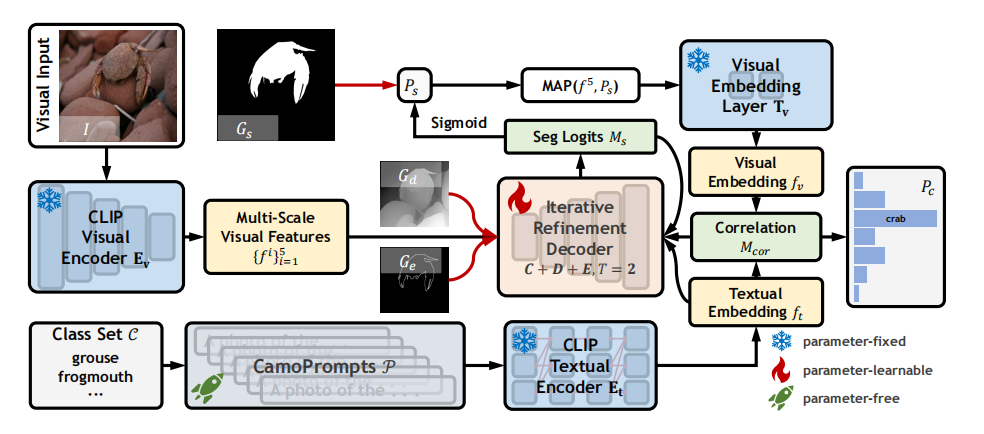
2.2 Semantic Guidance
在分割中,充分利用类别先验是非常有利于复杂环境下的物体检测的。因此,作者设计了Semantic Guidance Attention在图像特征中注入概念线索(concept cues)。
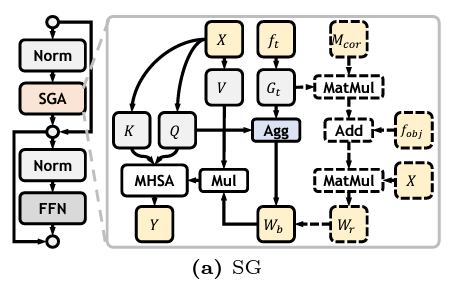
首先,作者把图像特征\(X\)投影到\(Q, K, V\),同时将类别文本嵌入信息\(f_t\)转换到class guidance vector\(G_t\),\(Q\)和\(G_t\)之间的相似度反映了不同空间位置在不同类别上的激活程度。然后做Agg操作,是对刚刚的相似度做softmax操作,可以得到每个位置最相关的类别,然后用softmax的结果对agg的结果加权平均(就是加权平均相似度值),可以得到每个位置“被类嵌入感知到的程度”或者说这个像素很有可能是前景(但是不知道属于哪个类)。和value相乘之后,那些被类嵌入感知程度高的像素就会在MHSA中多倍关注,提高检测卷效果;还可以这么理解,不引入文本嵌入,相当于让模型在分割阶段做开放题,引入文本嵌入之后,模型就相当于在众多答案中做单选题(这句话有点偏颇,看看就好)。\(V\)经过modulate(后面会讲)之后会和\(Q, K\)做MHSA。
2.3 Structure Enhancement
现有的方法表明,低级的结构信息,如边缘和深度,在伪装目标识别中起着重要的作用,这与人类视觉系统的机制密切相关。所以SE会附加到low-level的SG后面,来融入边缘和深度信息,以此增强结构细节。
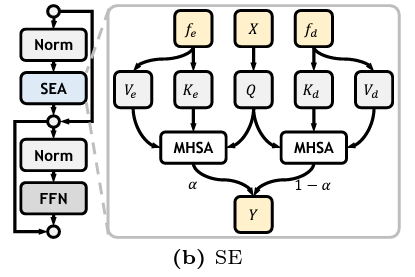
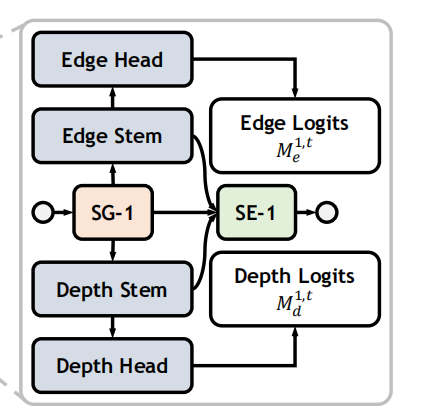
SG的输出会被送进两个分隔的数据流,包含convolutional stem和head用来edge和depth estimation,生成edge和depth logits,logits会受到edge、depth的真值监督。同时,convolutional stem的输出,也就是edge和depth的相关特征,会送进SE,使用MHSA去分别更新规则化之后的visual features
2.4 Iterative Refinement
在SG中,aggregation这个操作,会反应每个像素位置“被类嵌入感知到的程度”,可以理解为成为前景的概率。我们再引入Correlation Matrix,也就是cls_logits,上一阶段的分类结果,和\(G_t\)相乘,就是把\(G_t\),得到图片的类语义中心,再加上前一阶段的分割结果object-ware representation \(f_obj\)(使用上一次迭代产生的粗略分割图和image feature做MAP得到的),得到task-oriented object cues,让其和图像特征X相乘,得到一个相似度矩阵,每个位置的值代表它是上一阶段分割类别的概率,即\(W_r\),然后用\(W_r\)去调制(矫正)\(W_b\)。过程通俗理解为:
- \(W_b\):我大概觉得这些位置很有可能是潜在的前景
- \(W_r\):我看了看分类分数和分割掩码,其实这些地方才更可信
总结为:“调制”就是用辅助信息\(W_b\)(分类 & 分割)来调整原注意图\(W_r\)的信任度,保留语义感知的同时,结合真实图像内容做强化或抑制,从而让最终的注意力图更可靠、更语义相关。
在SG中,aggregation这个操作,反映了每个位置最相关的类别,但是image features和class semantic并没有对齐,通俗点、直白点来说,由于文本和图像的本身固有差距和距离,导致计算相似度向量或者矩阵的第n个位置的值可能并不是对应于图片特征的第n个位置,并且相似度向量的的部分值是我们不需要的,它可能会包含背景的相关信息,可能会干扰模型的判断。
因此作者引入modulate weight \(W_r\)。作者将correlation matrix和object-ware representation \(f_obj\)(使用上一次迭代产生的粗略分割图和image feature做MAP得到的)结合,得到task-oriented object cues,我这里认为是“经过图像分割特征筛选之后的文本类别语义信息”,然后和image feature结合,得到modulate weight \(W_r\),去modulate \(W_b\)。
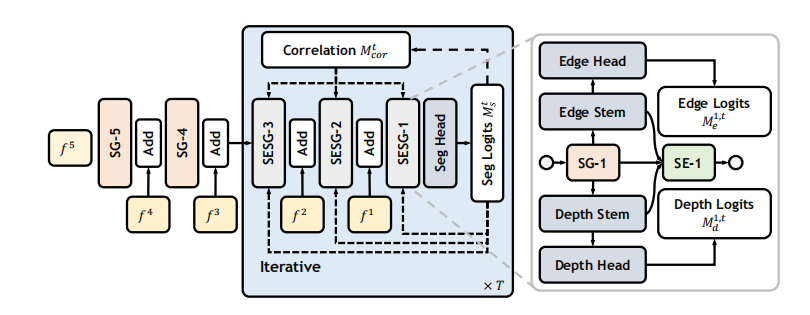
2.5 CamoPromts
prompts对于CLIP想要适应下游任务是至关重要的,因此作者专门为伪装检测设计了一套camoprompts,用来修饰类名,比如说原来类名是“frog”,经过修饰之后变为“A photo of the camouflaged frog”。CamoPrompts见下表:
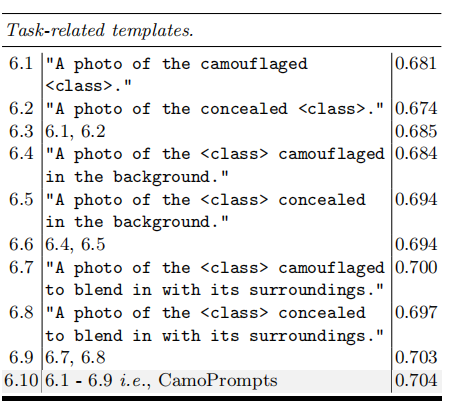
最终每个类的文本语义嵌入向量是表中prompts的平均值
3 Experiments
3.1 Implementation Details
- 数据集:
把数据集分为了两个类别不相交的集合,用于训练和测试,分别有14类和61类。原始数据集中只有RGB图和mask,作者使用了monocular depth estimation获得depth map,使用dilating and eroding operations获得edge map
- 训练设置:
使用AdamW优化器,学习率3e-6,weight decay为5e-4,batchsize是4,epoch为30,input和output尺寸为384✖️384.
- 评价指标
对传统COD的评价指标进行了改造,加入了类别作为评价指标。使用了\(\mathrm{cS}_m,\mathrm{~cF}_\beta^\omega,\mathrm{~cMAE,~cF}_\beta,\mathrm{~cE}_m,\mathrm{~cIoU}\)。就是如果预测的类别 (pre_cls) 和真实的类别 (gt_cls) 不一致,就把这个样本的评价指标设为 0。
3.2 CamoPrompts的讨论
Ablation、Comparison这里就不再讲了,可以查看原论文,值得注意的是,作者对CamoPrompts的重要性进行了分析。
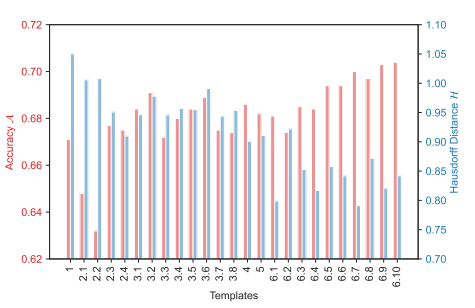
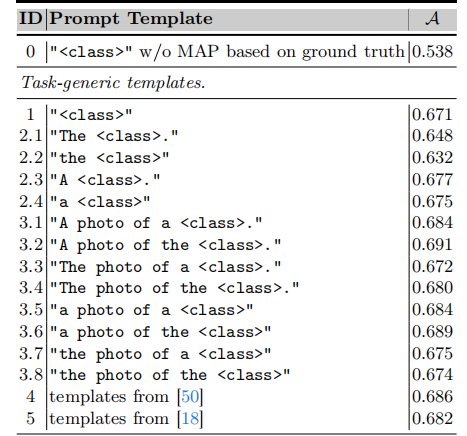
为了分析不同prompts template的影响,作者计算了来自training和testing的class labels在embedding space下的Hausdorff distance。上图可以看出,那些有良好分类准确率的templates通常能拉近training class和testing class之间的距离,这对之后OVCOS的prompts engineering起到了一个指导作用。
同时,作者还探讨了Edge和Depth对于OVCOS谁给更重要,作者通过实验得出了edge information flow更加重要的结论。
4 Future work
- 作者用最终的分割图和最高级特征\(f_5\)来和textual embedding计算相似度来判断类别,这是不充分的,因为最高级特征\(f_5\)并不包含许多细节信息,并且使用最终分割图做MAP会将分类的依据局限在物体区域这一块,但是伪装目标检测里,环境(背景)和前景的相互interaction在分类时作用也很大。
- 在论文中,作者一直在用cls_logtis也就是correlation matrix去指导分割,但是分割的过程也能指导分类,可以实现mutual learning
- 论文虽然是为了伪装目标检测设计的,但是整个网络的设计只有CamoPrompts是专门为OVCOS设计的,其他的网络模块更加general,用于OVSIS(open-vocabulary semantic image segmentation)也是行得通的,现在需要设计更加OVCOS Specific的Model。
- 做open-vocabulary segmentation最重要的是图像特征和文本特征的对齐,但是在伪装目标分割中,由于伪装物体和背景高度相似,导致提取到的特征充满环境噪音,如果不经处理直接和类别文本特征进行对齐,可能会产生错误的对齐,影响分割和最终分类效果。
- CLIP在训练时是进行的图像级监督,所以CLIP用于语义分割这种像素级任务可能会造成performance declination,尤其是COD这种对像素、细节要求更高的任务,所以说对CLIP做Per-Pixel的adapt是非常重要的。
- 本文是one-stage,可以设计two-stage的网络,首先是mask2former提取a bunch of masks,用shallow prompts “camouflaged objects”进行初始删选,筛掉那些基本不可能的mask,然后再使用CLIP将mask pooling之后的image进行分类,在CLIP内部可以加入Context信息,以弥补被mask掉的环境信息。