1. 什么是大语言模型?
大模型:一般指1亿参数以上的模型,大语言模型(LLMs)是针对语言的大模型
大模型有以下特点:
- 大规模参数
- 多任务处理能力:其在多种语言任务上有很好的性能。比如说文本摘要、情感分析、机器翻译等,因其已经在大规模数据集上学习到了语言模式和规律。
- 上下文推理:LLMs可以根据上下文生成有逻辑和连贯的回应,可以对话或者创作。可以记住一段对话中的重要细节,并在后续对话中保持一致性
- 自监督学习:LLMs主要适用未标注的数据进行训练,通过预测下一个词(自回归)、填补空白或匹配句子的方式来学习语言结构
- 通用型和可扩展性:LLMs可以迁移到多种任务和领域,经过少量微调,就能在下游特定任务中发挥性能。
2. 大模型(LMs)分类
根据输入内容分类:
- 语言大模型:GPT、Qwen、Bard
- 视觉大模型:ViT、文心UFO
- 多模态大模型:DALL-E、BLIP
根据预训练任务分类:
- 自回归语言模型:例如GPT,通过预测下一个词,适合生成任务
- 自编码语言模型:例如BERT,通过掩码(masked language modeling)预测被遮挡的词,适合理解和分类任务
- 序列到序列语言模型:如T5,BART,既可以生成也可以理解,机器翻译,文本生成应用广泛
根据模型规模分类
3. 目前主流LLMs开源模型体系
目前三种主要架构:Encoder-Decoder(T5),Decoder-only(GPT)和Encoder-only(BERT)
3.1 Encoder-Decoder
编码器利用堆叠的多头自注意力层对输入序列进行编码并生成潜在表示。解码器对这些表示进行交叉注意力并生成目标序列。例子:T5, BART。
- Encoder:没有掩码的self attention,每个位置都能看到整个输入序列
- Decoder:masked self-attention(只能看到自己和之前的)+cross attention(query来自msa的输出,k-v来自encoder的输出,没有mask)
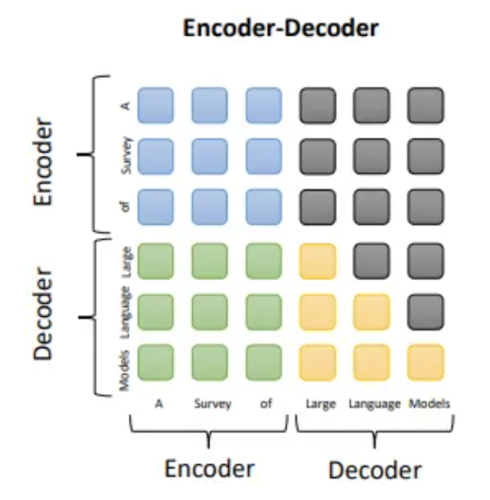
适用范围:翻译、摘要、问答,在偏理解的任务上效果好,在长文本生成任务效果差,训练效率低
代表模型:T5
3.2 Decoder-Only
主要包含causal decoder和Prefix Decoder(Prefix Decoder不能成为一种新的架构,更像是一种使用方法和训练策略)。一句话总结:prefix LM 的 prefix 部分的 token 互相能看到,causal LM 只有后面的 token 才能看到前面的 token。目前除了 T5 和 GLM 是 prefix LM,其他大模型基本上都是 Causal LM。
3.2.1 Causal Decoder
causal decoder 架构包含一个单向的 attention mask,允许每个输入令牌仅关注过去的令牌及其自身。
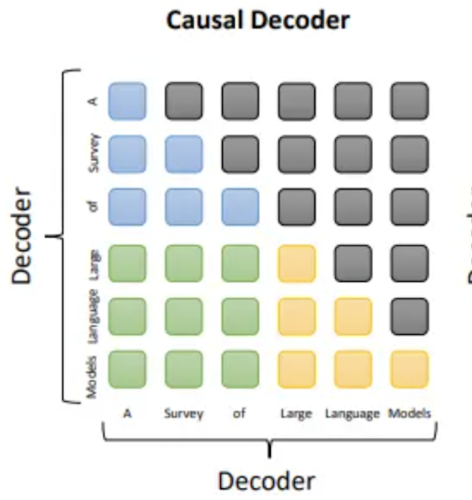
适用范围:语言建模、代码生成、对话生成,训练效率高,zero-shot性能好
3.2.2 Prefix Decoder
什么是Prefix Decoder?人为在输入token前加入一段虚拟的前缀token,不是真实输入,也不是输出目标,是可学习参数
[Prefix1, Prefix2, …, PrefixM, Token1, Token2, …, TokenN]
Prefix Decoder里,prefix token可以互相看到,输入token只能看到prefix token和该token之前的输入token。在计算损失的时候,值计算O1-O4部分的损失
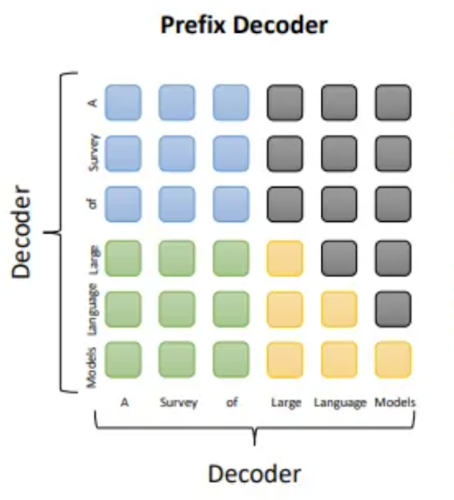
不同Prefix方式:
第一种是GLM,他的Prefix是一个残缺的句子,就是从一个句子中抽出若干部分,用[M]替代,然后需要模型自回归生成残缺的部分(就是output)
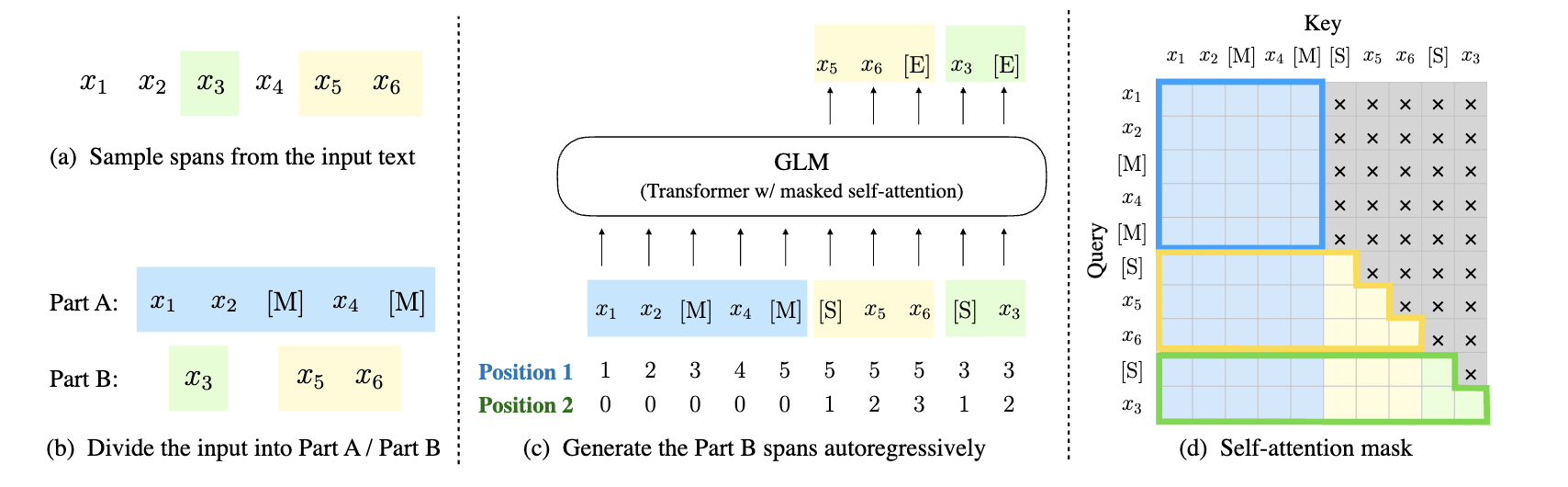
还有是一种偏向于Instruction tuning/SFT的
### Instruction:
Translate to French: I love you.### Response:
以上一整段就是prefix,模型的任务是生成response,也就是模型的输出:
Je t’aime.
无论是哪种方式,训练的时候只在 output 那一段计算 loss!
适用范围:PEFT,对话系统,Instruction tuning,低资源下快速适配新任务
3.3 Encoder-Only
只使用encoder,例子是BERT,没有mask,每个token都可以看到全部序列
适用范围:文本分类,句子对匹配,问答匹配(非生成式)
代表模型:BERT、RoBERTa、DeBERTa、ELECTRA
4 LLMs常用的预训练任务(训练目标)
常用预训练任务包括:语言建模、去噪自编码以及混合去噪器
4.1 语言建模(Language Modeling,LM,GPT、PaLM、LLaMA)
该任务的核心是预测下一个词元,对于给定token序列:\(\mathbf{x}=\{x_1,\ldots,x_n\}\),模型需要根据\(x_{<i}\)预测出\(x_i\),训练目标是最大化下述式子:
\[\mathcal{L}_{LM}(\mathbf{x})=\sum_{i=1}^n\log P(x_i|\mathbf{x}_{<i}).\]
此外,从本质上看,LM也是一种多任务学习的过程,例如:
- 在预测句子前缀“这部电影剧情饱满,演员表演的很棒,非常好看”中的“好看”时,模型实际上在进行情感分析任务的语义学习
- 在预测句子前缀“小明有三块糖,给了别人两块,自己还剩下一块”中的“一块糖”时,则是在进行数学算术的学习
因此,基于大规模语料的预训练任务能够潜在地学习到解决众多任务的相关知识和能力
训练效率:Prefix Decoder < Causal Decoder(因为causal decoder会在所有token上计算损失,而prefix只会在输出上计算损失,causal可以学习到更多东西)
4.2 去噪自编码(Denoising Autoencoding,DAE,BART,T5,GLM)
DAE的输入是一段损坏的文本\(\mathbf{x}_{\tilde{\mathbf{x}}}\),其中若干部分被替换成为[M],语言模型需要去以自回归的方式恢复\tilde{\mathbf{x}}(span),DAE的训练目标为:
\[\mathcal{L}_{DAE}(\mathbf{x})=\log P(\tilde{\mathbf{x}}|\mathbf{x}_{\setminus\tilde{\mathbf{x}}}).\]
和语言建模相比,这个任务更复杂,因为需要设定额外的优化策略,比如词元替换策略,替换片段长度,替换词元比例等
4.3 混合去噪器(Mixture-of-Denoisers,MoD,PaLM2)
它把LM和DAE都视为不同类型的去噪任务,S-Denoiser(LM)、R-Denoiser(short span and low corruption)、X-Denoiser(long span or high corruption),三种不同去噪器的输入使用了三种不同的特殊token,分别为[S],[R],[X]。
5 大模型的涌现能力
什么是涌现能力?
当一个复杂系统由很多微小个体构成,这些微小个体凑到一起,相互作用,当数量足够多时,在宏观层面上展现出微观个体无法解释的特殊现象,就可以称之为”涌现现象”。
大语言模型的涌现能力:之前的模型在某些指标上不好,但是大模型来了之后预测效果发生了质变,什么原因呢?
- 猜想1:任务的评价指标不够平滑

一种猜想是因为很多任务的评价指标不够平滑,导致我们现在看到的涌现现象。关于这一点,我们拿 Emoji_movie 任务来给出解释。Emoji_movie任务是说输入 Emoji图像,要求 LLM 给出完全正确的电影名称,只有一字不错才算正确,错一个单词都算错。 如上图所示,输入的Emoji是一个女孩的笑脸,后面跟着三张鱼类的图片,您可以猜猜这是什么电影。下面左侧的 2m代表 模型参数规模是 200 万参数,以及对应模型给出的回答。可以看出,随着模型规模不断增大至 128B 时,LLM才能完全猜对电影名称,但是在模型到了125m和4b的时候,其实模型已经慢慢开始接近正确答案了。
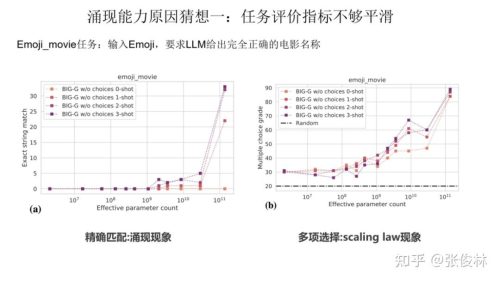
如果评价指标要求很严格,要求一字不错才算对,那么Emoji_movie任务我们就会看到涌现现象的出现,如上图图左所示。但是,如果我们把问题形式换成多选题,就是给出几个候选答案,让LLM选,那么随着模型不断增大,任务效果在持续稳定变好,但涌现现象消失,如上图图右所示。这说明评价指标不够平滑,起码是一部分任务看到涌现现象的原因。
- 猜想2:复杂任务vs子任务
开始的时候我们提到过,展现出涌现现象的任务有一个共性,就是任务往往是由多个子任务构成的复杂任务。也就是说,最终任务过于复杂,如果仔细分析,可以看出它由多个子任务构成,这时候,子任务效果往往随着模型增大,符合 Scaling Law,而最终任务则体现为涌现现象。这个其实好理解,比如我们假设某个任务 T 有 5 个子任务 Sub-T 构成,每个 sub-T 随着模型增长,指标从 40% 提升到 60%,但是最终任务的指标只从 1.1% 提升到了 7%,也就是说宏观上看到了涌现现象,但是子任务效果其实是平滑增长的。
6 Scaling law
6.1 什么是Scaling law
Scaling law目标:在训练之前了解模型的能力,以改善关于大模型的对齐、安全和部署(大模型训练很耗费时间,如果在训练之前就可以知道模型的边界在哪里,可能会节省很多时间)
Scaling law定义:用计算量、数据规模和模型规模来预测模型能力
6.2 OpenAI vs DeepMind
OpenAI:计算量、数据规模和模型规模三者中任何一个因素受到限制的时候,loss与其之间存在幂律关系
随着计算量、数据规模和模型规模的增加,语言建模性能平稳提升。为了获得最佳性能,必须将这三个因素同步扩大。当没有受到其他两个因素限制时,性能和每个单独因素呈幂律关系。三者的影响程度:计算量>参数>>数据集大小。
计算预算增加10倍,如果想保持效果,模型大小应该增加5.5倍,训练token数量增大1.8倍
DeepMind:
- 他们认为模型大小,和训练token的数量(数据集大小)都应该按相等比例进行扩展
- 在给定计算量下,模型大小和数据量之前的选择存在一个最优解
- 在计算成本达到最优的情况下,模型大小和训练数据(token)应该等比例缩放。对于给定参数量的模型,最佳训练数据集大小约为模型中参数量的20倍
- 大语言模型应该关注数据集的扩展,但是数据时高质量的时候,更大数据集的益处才能体现出来