什么是注意力机制?给定一篇很长的文章,然后就此文章进行提问,提出的问题只和段落中的一两个句子相关,其余部分都是无关的,为了减小神经网络的负担,只需要把相关的片段挑选出来让后续的神经网络来处理,而不需要把所有文章都输给神经网络
1.计算感兴趣的输入向量
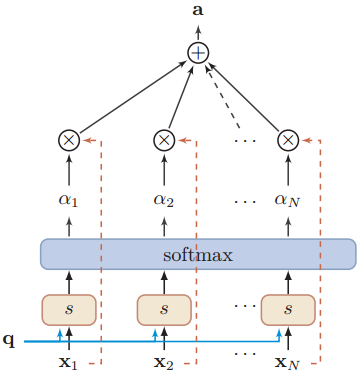
给定输入向量从\([x_{1},\cdots,x_{N}]\)中选出和某个特定任务相关的信息,需要引入一个和任务相关的表示,成为查询向量Query Vector,并通过打分函数计算查询向量和输入向量的相关性。计算在给定q,x情况下,选择第n个输入向量的概率
\[\begin{aligned}\text{an}& =p(z=n|\boldsymbol{X},\boldsymbol{q}) \\&=\mathrm{softmax}\left(s(x_n,\boldsymbol{q})\right) \\
&=\frac{\exp\left(s(x_n,q)\right)}{\sum_{j=1}^N\exp\left(s(x_j,q)\right)},\end{aligned}\]
其中s为打分函数,有加性模型、点积模型、缩放点积模型、双线性模型,这些模型都是对输入向量x和查询向量q做一些运算,这里挑点积模型说一下,因为transformer会用到这个打分函数,其他的这里就不具体阐述了。\[s(x,q)=x^{\intercal}q\],可以看出,点积就是内积运算,乘积越大,两者相似度越高,和\($q\)乘积最大的\(x_n\),打分最高,和查询向量最相似,也就是说其权重(注意力分布)最高,和查询向量匹配度最高。\(\alpha_n\)为注意力分布,可以理解为每个输入向量的权重。
2.软性注意力机制
注意力分布\(\alpha_n\)可以看成在给定任务相关的查询\($q\)时,第n个输入向量受关注的程度,可以采用一种软性的信息选择机制对输入信息进行汇总,即
\begin{aligned}\operatorname{att}(X,\boldsymbol{q})&=\sum_{n=1}^N\alpha_n\boldsymbol{x}_n,\\&=\mathbb{E}_{z\sim p(z|X,\boldsymbol{q})}[\boldsymbol{x}_z].\end{aligned}
上述式子称为软性注意力机制
3.硬性注意力机制
硬性注意力机制就是只关注某一个输入向量,即选取概率最高的向量作为输出\[\operatorname{att}(X,\boldsymbol{q})=\boldsymbol{x}_{\hat{n}}\] 其中\(\hat{n}=\underset{n=1}{\operatorname*{\arg\max}}\alpha_{n}\)
4.键值对注意力
可以用key-value pair来表示输入信息,其中key用来计算注意力分布\(\alpha_n\),value用来计算聚合信息,key-value pair表示为\((K,V)=[(k_{1},\boldsymbol{v}_{1}),\cdots,(\boldsymbol{k}_{N},\boldsymbol{v}_{N})]\),则注意力函数为
\[\begin{aligned}
\operatorname{att}{\Big(}(\boldsymbol{K},\boldsymbol{V}),\boldsymbol{q}\big)& =\sum_{n=1}^{N}\alpha_{n}\boldsymbol{v}_{n}, \\
&=\sum_{n=1}^N\frac{\exp\left(s(\boldsymbol{k}_n,\boldsymbol{q})\right)}{\sum_j\exp\left(s(\boldsymbol{k}_j,\boldsymbol{q})\right)}\boldsymbol{v}_n,
\end{aligned}\]
普通注意力机制里面的输入向量既充当key又充当value。
5.多头注意力模型
见transformer(attention is all you need)
6.自注意力模型
见transformer(attention is all you need)