1 Why BLIP?
- 现在的预训练模型要么在理解任务表现出色,要么在生成任务任务上表现出色,还没有统一这两个任务的模型。现在encoder-based模型,比如clip,不太能迁移到生成任务,然而encoder-decoder的模型不太能迁移到图文检索的任务。
- 现在的预训练模型都通过扩大数据集来实现好的性能,这些数据集上包含许多充满噪声的图文对。论文表明,充满噪声的文本对于视觉语言训练是次优的。
为了解决以上两个问题,作者提出两个解决方案:
- Multimodal mixture of Encoder-Decoder(MED):适应于多任务预训练,既可以当作单模态encoder,也可以作为视觉限制的文本编码器,也可以作为视觉限制的文本解码器,通过三个objective进行训练:image-text contrastive learning,image-text matching,image conditioned language modeling
- Captionning and Filtering(CapFilt):对于图像文本对的一种新bootstrapping的方法。captioner对于给定图片创建合成的caption,使用filter从原始文本和合成的文本中去除那些被认为有噪声的caption。
2 Method
2.1 Model Architecture
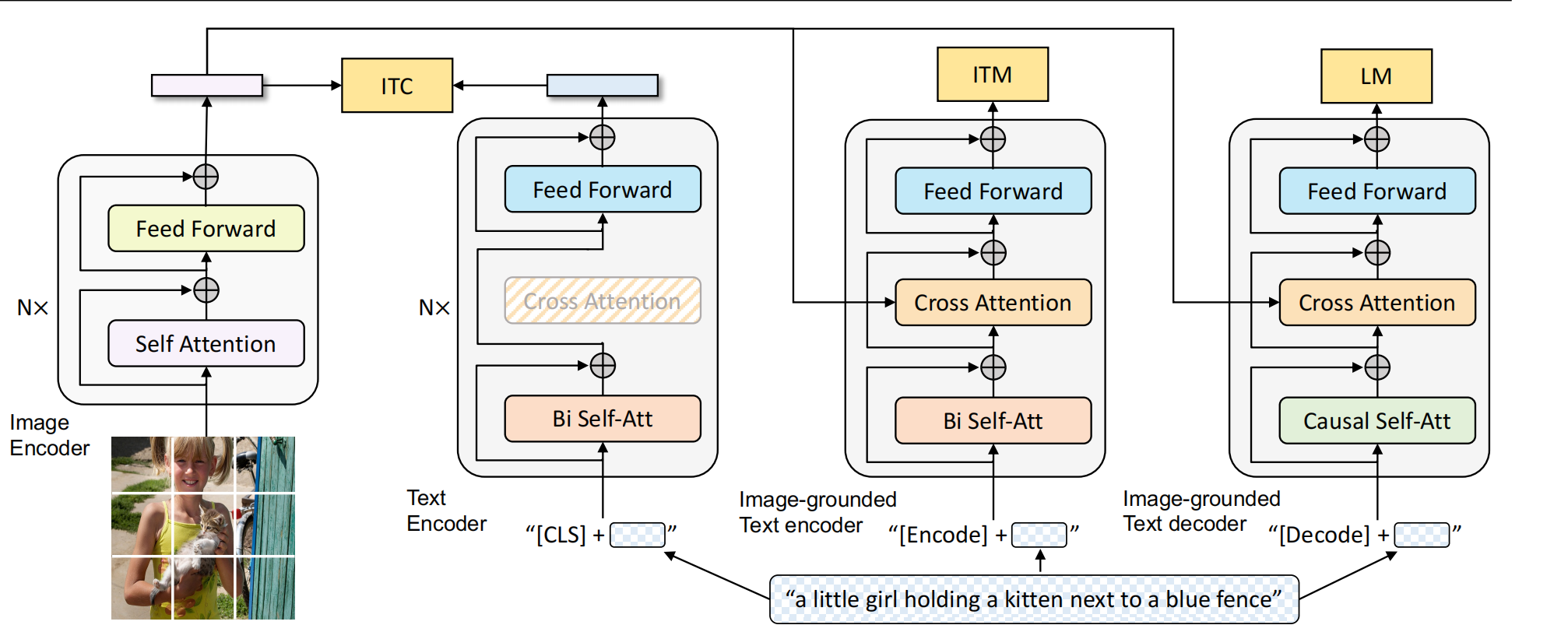
使用ViT作为image encoder,使用[CLS]作为图片的全局视觉特征。
为了统一理解和生成任务,提出了MED架构,内涵三种结构:
- Unimodal encoder:text encoder使用bert,使用[CLS]总结整个句子。
- Image-grounded text encoder:在text encoder中每个transformer block的self-attention和FFN中间加入cross attention。[ENCODE] token被加到最前面,输出embeddings的[ENCODE]作为image-text pair的多模态特征表示。
- Image-grounded text decoder:把bidirectional self attention换成causal self attention。使用[DECODE]标注一个序列的开始,一个end-of-sequence token标注一个序列的结束。
2.2 Pretraining Objectives
2.2.1 Image-Text Contrastive Loss(ITC)
他会激活unimodal encoder,旨在对齐视觉transformer和text transformer的特征空间。其采用了momentum encoder和momentum distillation,构建一个稳定的、更新更平滑的负样本队列。
什么是Momentum Encoder?
训练过程中,模型需要从 正样本(匹配的图文对) 和 负样本(不匹配的图文对) 中学习区分图像与文本的关联性。但如果负样本的特征更新过快,模型可能会受到梯度震荡的影响,导致学习不稳定。因此Momentum Encoder 通过 动量更新机制(Momentum Update),保持 历史特征信息,避免负样本特征更新过快,从而让对比学习的目标更加稳定;并Momentum Encoder 通过维护一个动态的负样本队列(Queue),存储过去的图像-文本特征,从而让模型可以利用更多样化的负样本进行对比学习,这样,模型在每次训练时不仅能使用当前 batch 的数据进行对比学习,还能使用 过去多个 batch 的数据,并且减少模型的计算开销,不需要重新计算所有负样本的特征。 Momentum Encoder 不会直接受到梯度更新的影响,而是用指数平均移动平滑地更新,因此它的特征变化不会像标准编码器那样剧烈。
ITC计算过程如下:
\(s=g_v(\boldsymbol{v}_\mathrm{cls})^\top g_w(\boldsymbol{w}_\mathrm{cls})\)计算相似度,v和w分别为视觉特征和文本特征。\(g_v,g_w\)分别为线性变换,他们把[CLS]映射为normalized lower-dimensional (256-d) representations。来自momentum encoder的特征表示为:\(g_v^\prime(\boldsymbol{v}_\mathrm{cls}^\prime),g_w^\prime(\boldsymbol{w}_\mathrm{cls}^\prime)\)。I,T分别为图像和文本。定义
\[s(I,T)=g_v(\boldsymbol{v}_\mathrm{cls})^\top g_w^\prime(\boldsymbol{w}_\mathrm{cls}^\prime),s(T,I)=g_w(\boldsymbol{w}_\mathrm{cls})^\top g_v^\prime(\boldsymbol{v}_\mathrm{cls}^\prime).\]。
对于任意给定的I,T,有:
\[p_m^{\mathrm{i}2\mathrm{t}}(I)=\frac{\exp(s(I,T_m)/\tau)}{\sum_{m=1}^M\exp(s(I,T_m)/\tau)},\quad p_m^{\mathrm{t}2\mathrm{i}}(T)=\frac{\exp(s(T,I_m)/\tau)}{\sum_{m=1}^M\exp(s(T,I_m)/\tau)}\]
注意,这里的\(I\)和\(T_m\)不一定是匹配的图文对。
\(\boldsymbol{y^\mathrm{i2t}}(I),\boldsymbol{y^\mathrm{t2i}}(T)\)为one-hot 0-1向量,表示样本中哪个text和该image匹配,哪个image和该text匹配。ITC loss定义为p,y之间的交叉熵损失:
\[\mathcal{L}_{\mathrm{itc}}=\frac{1}{2}\mathbb{E}_{(I,T)\thicksim D}\left[\mathrm{H}(\boldsymbol{y}^{\mathrm{i}2\mathrm{t}}(I),\boldsymbol{p}^{\mathrm{i}2\mathrm{t}}(I))+\mathrm{H}(\boldsymbol{y}^{\mathrm{t}2\mathrm{i}}(T),\boldsymbol{p}^{\mathrm{t}2\mathrm{i}}(T))\right]\]
\(\boldsymbol{p}^{\mathrm{i}2\mathrm{t}}(I)\)是一个[1, batch_size]的向量,它的第\(m\)个值代表该图片\(I\)和第\(m\)个文本计算的值\(p_m^{\mathrm{i}2\mathrm{t}}(I)\)。这个公式可能和普遍写法不太一样,解释一下。每个I要和每一个T计算一次p,每个T要和每个I计算一次p。下面是标准交叉熵损失:
\[\mathrm{H}(\mathbf{y},\mathbf{p})=-\sum_{m=1}^My_m\log p_m=-\log p_\mathrm{gt}\]
y为one-hot向量,假设\(y_i\)为1,其他全为0,代入进去,就变为:
\[\mathrm{H}(y,p)=-\log(p_i)=-\log\left(\frac{\exp(s(I,T_i)/\tau)}{\sum_{m=1}^M\exp(s(I,T_m)/\tau)}\right)\]
就变成了我们常见的样子了。
接下来讲一下Momentum Distillation的原理:
可以看到上面的ITC是用了one-hot的ground-truth label,是hard labels。但是因为训练数据集中存在大量noise image-text pair。对于ITC来说,有可能有些其他的text也可以作为该image的描述。伪标签由动量模型(Momentum Model)生成,动量模型是在原本模型(image encoder, text encoder, multimodal encoder)上做指数平均移动(exponential moving average)。目的是在原始模型训练的时候,不仅希望模型预测与ground-truth的one-hot label去尽可能的接近,还希望模型预测与动量模型出来的pseudo targets尽可能的匹配,这样就能达到一个比较好的折中点。因为当one hot label正确时,可以学习到很多信息,但当one hot label是错误的,或者是noisy的时候,作者希望稳定的momentum model能够提供一些改进。
新的相似度计算定义为:
\[s^{\prime}(I,T)=g_{v}^{\prime}(\boldsymbol{v}_{\mathrm{cls}}^{\prime})^{\top}g_{w}^{\prime}(\boldsymbol{w}_{\mathrm{cls}}^{\prime}),s^{\prime}(T,I)=g_{w}^{\prime}(\boldsymbol{w}_{\mathrm{cls}})^{\top}g_{v}^{\prime}(\boldsymbol{v}_{\mathrm{cls}}^{\prime}).\]
然后用计算\(p^{\mathrm{i}2\mathrm{t}},p^{\mathrm{t}2\mathrm{i}}\)的方式计算\(q^{\mathrm{i}2\mathrm{t}},q^{\mathrm{t}2\mathrm{i}}\),把\(s\)替换为\(s^{\prime}\)。最后loss的公式为:
\[\mathcal{L}_{\mathrm{itc}}^{\mathrm{mod}}=(1-\alpha)\mathcal{L}_{\mathrm{itc}}+\frac{\alpha}{2}\mathbb{E}_{(I,T)\sim D}\left[\mathrm{KL}(\boldsymbol{q}^{\mathrm{i}2\mathrm{t}}(I)\parallel\boldsymbol{p}^{\mathrm{i}2\mathrm{t}}(I))+\mathrm{KL}(\boldsymbol{q}^{\mathrm{t}2\mathrm{i}}(T)\parallel\boldsymbol{p}^{\mathrm{t}2\mathrm{i}}(T))\right]\]
KL为KL散度,是两个概率分布之间的距离指标:
\[\mathrm{KL}(q\parallel p)=\sum_iq_i\log\left(\frac{q_i}{p_i}\right)\]
其作用是让当前模型预测的图文匹配概率分布\(p\)逐渐向动量编码器给出的分布\(q\)靠拢。
2.2.2 Image Text Matching Loss
ITM激活Image Grounded text encoder,旨在学习图文多模态表达。其是一个二分类任务,模型使用一。linear head预测一对image-text是match还是unmatch的。
具体实现细节:[ENCODE]token作为多模态表示,被送到linear head,会输出一个two class probability \(p^{\mathrm{itm}}\), ground truth \(\boldsymbol{y^\mathrm{itm}}\)是一个二维度one-hot向量。Loss公式如下:
\[\mathcal{L}_{\mathrm{itm}}=\mathbb{E}_{(I,T)\thicksim D}\mathrm{H}(\boldsymbol{y}^{\mathrm{itm}},\boldsymbol{p}^{\mathrm{itm}}(I,T))\]
在image-text pair的选择上,作者采用了构造hard negatvie sample的方法。具体来说,对于batch内的某张图片,作者会根据该图片与其他text的contrastive similarity(就是前文中\(p_m^{\mathrm{i}2\mathrm{t}}\)的那个公式)的分布对text进行采样,contrastive similarity高的相对来说被选取的概率比较高。这样 ITM 就变成一个更挑战的任务,逼模型学到更细致的匹配特征。
2.2.3 Language Modeling Loss
它会激活Image grounded text decoder,旨在对余给定图片生成文本描述。它使用交叉熵损失以自回归的方式来最大化下一个token出现的概率。
结构上,text decoder和text encoder除了self attention都共享相同的参数。不同点是,text encoder使用双向attention去建模整个序列,text decoder使用causal attention去预测next token。
2.3 CapFilt
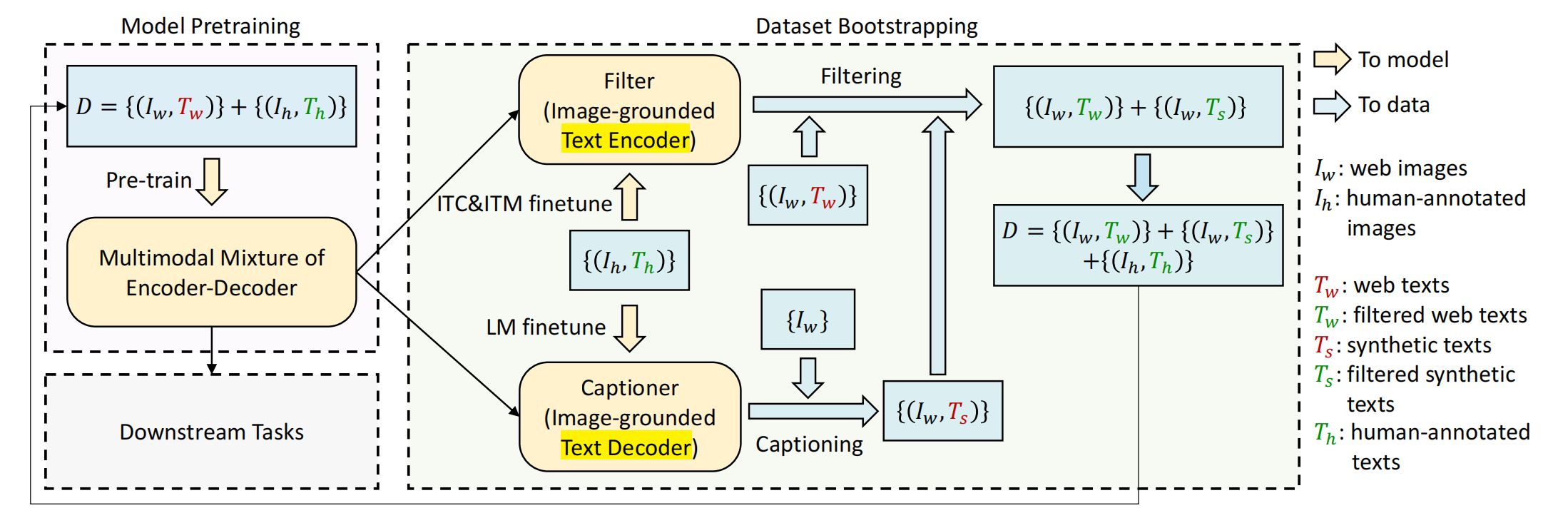
包含两部分:
- Capitoner:对网络图片生成captions
- filter:去除含噪声的image-text pairs
它们两个都是经过pretrained MED初始化得来,然后在COCO上fintue。就是先在raw image text上训练一遍,然后使用训练一遍的模型去生成caption,去除noise。
具体来说,Captioner是image grounded text decoder,使用LM在COCO上单独fintue。finetune之后,对于某个web image \(I_w\),captioner会产生一个合成的文本\(T_s\)。
filter是imager grounded text encoder,使用ITC和ITM单独进行finetune。finetune之后,对于某张图片,如果ITM linear head认为original web texts或者合成的texts与其不匹配,filter会移除它。然后,会把filtered image text pairs和human-annotated pairs合起来形成一个新的数据集,去预训练一个新的模型。
3 实验
3.1 数据集
pretraining使用224 ✖️ 224的图片,finetune的时候采用384 ✖️ 384的图片,使用的数据集一共14M,其中人工标注数据集有COCO和Visual Genome,web datasets有Conceptual Captions,Conceptual 12M,SBU captions。作者还在LAION上进行了实验,它包含了115M的图片。
3.2 参数共享策略
在pretraining阶段,text encoder和text decoder除了self att都共享参数,如果连self att都共享参数,作者发现效果会下降,因为encoding task和decoding task会起冲突。
在CapFilt阶段,filter(text encoder)和captioner(text decoder)是在COCO上单独finetune的,那他们参数也要共享吗?作者对此进行了实验,结果如下图所示:

可以看出,如果像pretrain一样共享参数,效果会下降,并且filter发现noisy的比例会明显下降。这是因为由于参数共享,由captioner产生的含有噪声的captions会不容易被filter发现,因此,在CapFilter阶段,不使用参数共享。
3.3 Comparison
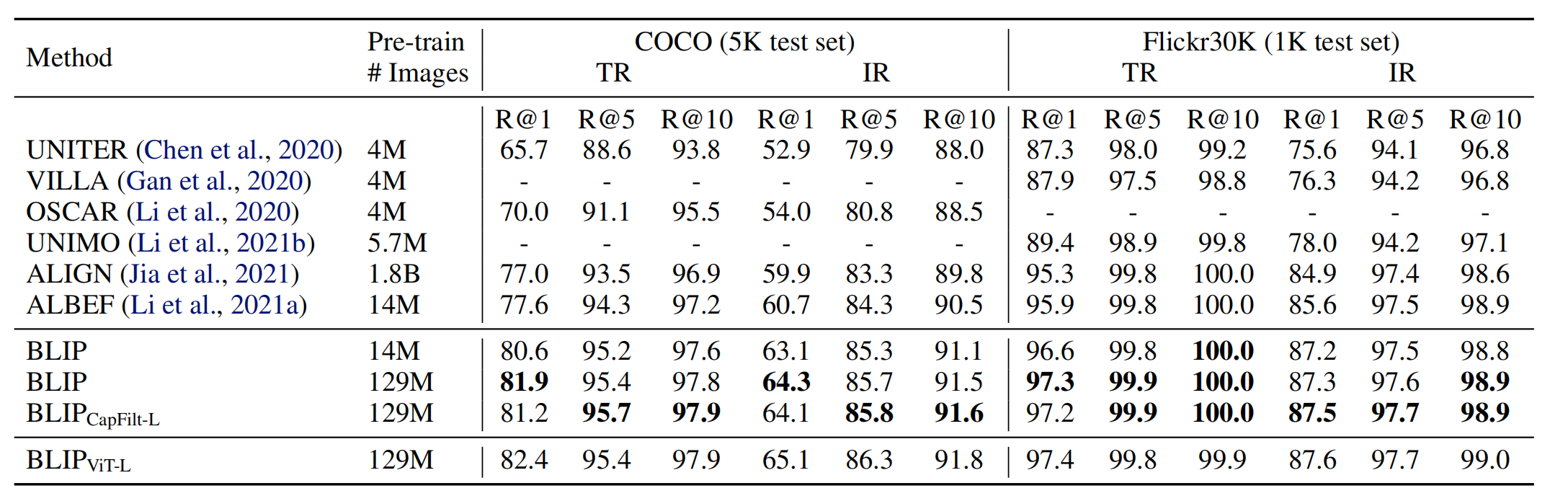
3.3.1 Image-Text Retrieval
分为Image to text(TR)和text to image(IR),在COCO和Flickr30K上测试。在进行测试之前,预训练模型现在COCO和Flickr30K上进行finetune。
R@5,R@1是什么?
R@1、R@5、R@10 这些指标在 图文检索(image-text retrieval)或 推荐系统、排序任务中超级常见。它们的全称是:Recall at K(在 Top-K 中命中的比例)。
R@1是正确答案是否在Top1里?R@5是正确答案是否在Top2里?
3.3.2 Image Captioning
在COCO和NoCaps进行测试,模型在COCO上使用LM Loss进行finetune,对于每个caption,加入prompt:“a picture of……”
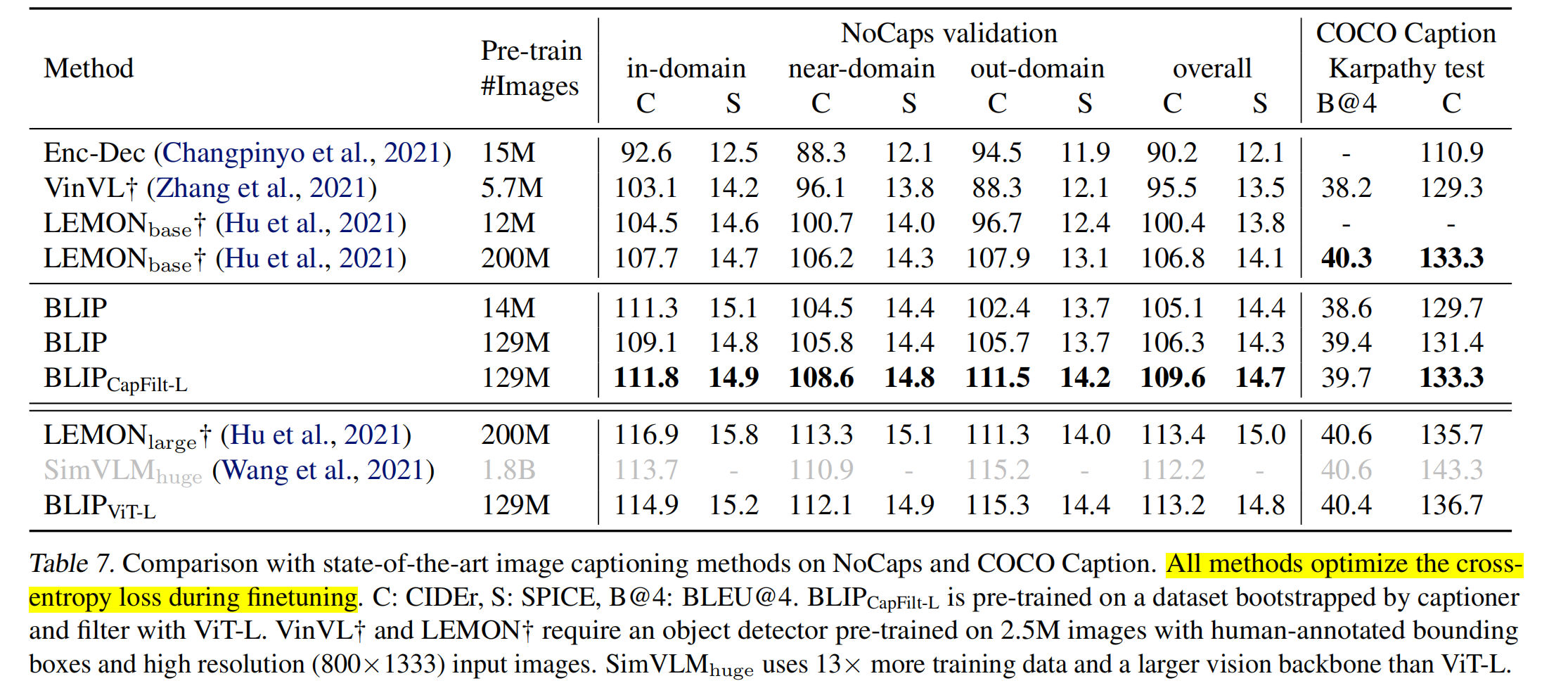
C: CIDEr, S: SPICE, B@4: BLEU@4是什么?
先从n-gram讲起。n-gram是连续的n个词组成的片段。比如有一句生成的话”a man is riding a horse”,1-gram就是”a”, “man”, “is”, “riding”, “a”, “horse”,2-gram就是”a man”, “man is”, “is riding”, “riding a”, “a horse”,以此类推。主要用于NLP任务,用于对比预测句子和参考答案是否相似。参考(label)句子:”a person is riding a horse”,如果使用2-gram匹配:
- 预测的2-gram:”a man”, “man is”, “is riding”, “riding a”, “a horse”
- label的2-gram:”a person”, “person is”, “is riding”, “riding a”, “a horse”
- 匹配的有:”is riding”, “riding a”, “a horse”
BLEU:目标是评估一个生成的句子和多个参考句子之间的 n-gram 精确匹配程度。BLEU-4就是最多统计4-gram的匹配,计算1~4-gram的匹配比例,综合一个分数。计算公式为:
\[BLEU=BP\times exp((1/4)\times(logp_1+logp_2+logp_3+logp_4))\]
\(p_n\)是n-gram命中数量,\(BP\)是Brevity Penalty,为了惩罚那些用“短小但精准”的句子骗分。比如reference是”a small cat is sleeping on the sofa”,模型生成candidate是”cat sleeping”,其1-gram和2-gram很高,但是其实这个candidate预测并不好。所以加入惩罚机制:
\[\mathrm{BP}=
\begin{cases}
1 & \mathrm{if~}c>r \\
\exp(1-\frac{r}{c}) & \mathrm{if~}c\leq r & & &
\end{cases}\]CIDEr:是改进版BLEU,是TF-IDF加权的n-gram匹配,BLEU是命中了就给分,CIDEr是命中稀有的词,给更多的分数。核心思想是用 TF-IDF 加权的 n-gram 向量 表示句子,计算生成句与参考句的余弦相似度。举个例子:candidate为:”the cat is sitting on the mat”,参考句子有三个”the cat sits on the mat”,”a cat is on a mat”,”there is a cat sitting quietly on the mat”
- 提取n-gram
- 计算TF(词频):对于每个n-gram,在该句的n-gram中出现了几次,占所有n-gram的比例。“the cat” 出现 1 次,句子有 6 个 2-gram → TF = 1 / 6
- 计算IDF(逆文档频率):\(\mathrm{IDF}(g)=\log\left(\frac{N}{n_g}\right)\),g是某个n-gram,N总参考句数量,\(n_g\)含有g的参考句个数。“the cat” 在 3 个参考中都出现 → IDF 较小。“sitting quietly” 只在 1 个参考中出现 → IDF 大
- 构造TF-IDF向量:每个句子(reference和candidate)都变成一个n-gram的向量。vector[“the cat”] = TF × IDF、vector[“cat sits”] = TF × IDF
- 计算余弦相似度:candidate和每个reference,各算一个余弦相似度\(\mathrm{sim}(c,r)=\frac{\vec{c}\cdot\vec{r}}{\|\vec{c}\|\|\vec{r}\|}\)
- 多个n合并,分别计算CIDEr_1 (1-gram 相似度)、CIDEr_2(2-gram 相似度)…………,然后平均。
SPICE:评估生成描述是否传达了和参考句一样的语义信息,核心方法:把句子解析成语义图(scene graph),然后比较这些图。举个例子,Candidate为:The red car is parked beside a tree。Reference为:”A red vehicle is next to the tree.”
- 首先提取三元组,Candidate提取为:G_c = {
object: car, tree
attribute: red(car)
relation: parked(car), beside(car, tree)
}。Reference提取为:G_r = {
object: vehicle, tree
attribute: red(vehicle)
relation: next_to(vehicle, tree)
}- 对齐和匹配。SPICE 支持 同义词匹配(比如用 WordNet)。
- 计算F1分数:匹配了的 object:✅ car/vehicle, tree。匹配了的 attribute:✅ red(car) ≈ red(vehicle)。匹配了的 relation:✅ beside(car, tree) ≈ next_to(vehicle, tree)。cadidate中语义单元数为5,reference中的语义单元数为5,相匹配的数量也为5。最后计算F1分数:\[\begin{cases}
\mathrm{Precision} & =\frac{\text{matched tuples}}{\text{candidate tuples}} \\
\mathrm{Recall} & =\frac{\text{matched tuples}}{\text{reference tuples}} \\
\mathrm{SPICE} & =\frac{2\cdot\mathrm{P}\cdot\mathrm{R}}{\mathrm{P}+\mathrm{R}}
\end{cases}\]
3.3.3 Visual Question Answering(VQA)
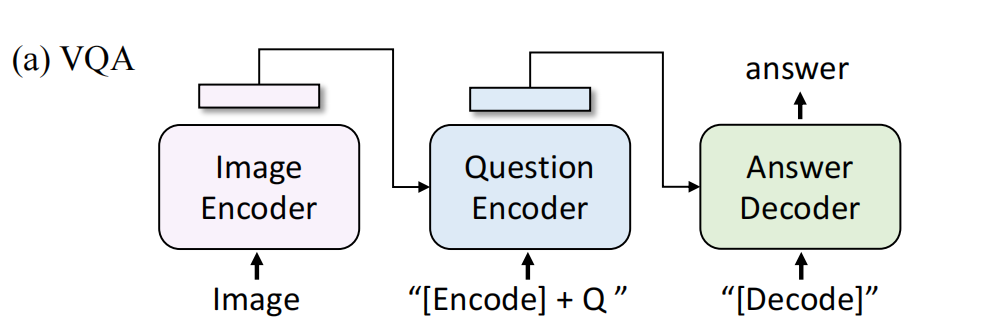
对于给定一个问题,要求预测一个答案,作者认为是一个答案生成任务,这样可以实现open ended VQA。在VQA上finetuning时,对模型结构进行了重新安排,图像和问题被encoder到多模态表征中(用image grounded text encoder)。然后把多模态表征送到image-grounded decoder里去。
3.3.4 Natural Language Visual Reasoning(NLVR)
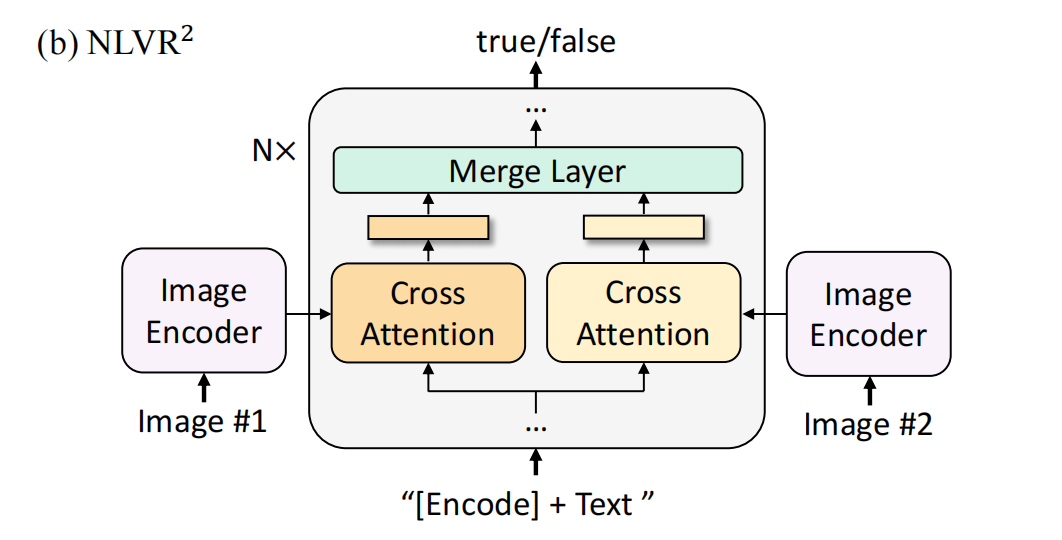
该任务会给定一段文字,让模型判断该文字是否描述一对图片,是一个二分类任务。这个任务难度更大,需要模型进行 跨图像推理(Cross-Image Reasoning),不仅要理解单个图像的内容,还要比较多个图像之间的关系,模型理解并推理文本描述是否准确地反映了图像所表达的内容,核心挑战在于,模型不仅要理解图像和文本的基本语义,还要能够进行逻辑推理,比如数目推理,空间关系,属性推理。
对模型做了修改,对于每个block,首先有两个cross attention layer,使用预训练模型的cross attention layer进行初始化,参数初始化处理两个输入图片,他们的输出被merge,然后送进FFN。在前6层,merge就是简单的average pooling,在6-12层,先concat然后进行linear projection。最后,使用MLP作用于[ENCODE]
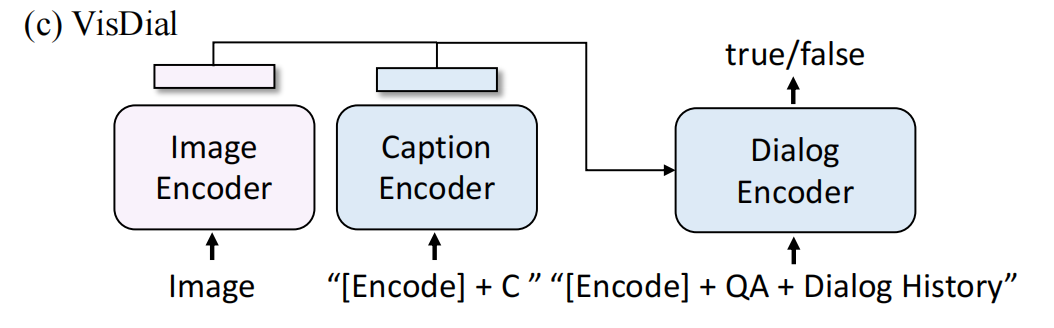
3.3.5 Visual Dialog
是VQA的扩展,不仅需要根据image-question预测answer,还要考虑对话历史和图片的caption,但是作者在这里没有把它当作生成问题,而是一个分类问题。对于VisDial,作者也对模型结构进行修改,caption encoder是unimodal text encoder,dialog encoder是image grounded text encoder。把图片embedding和caption embedding进行concat,送到dialog encoder和QA、history一起进行cross-attention。Dialog encoder使用ITM loss进行训练,给定caption、image和history,让它学会分辨某个该答案是否是该问题的答案。