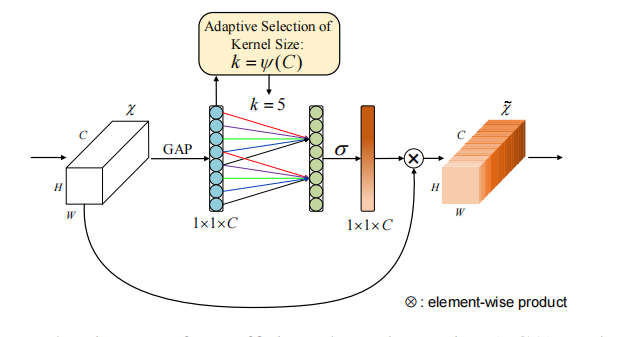
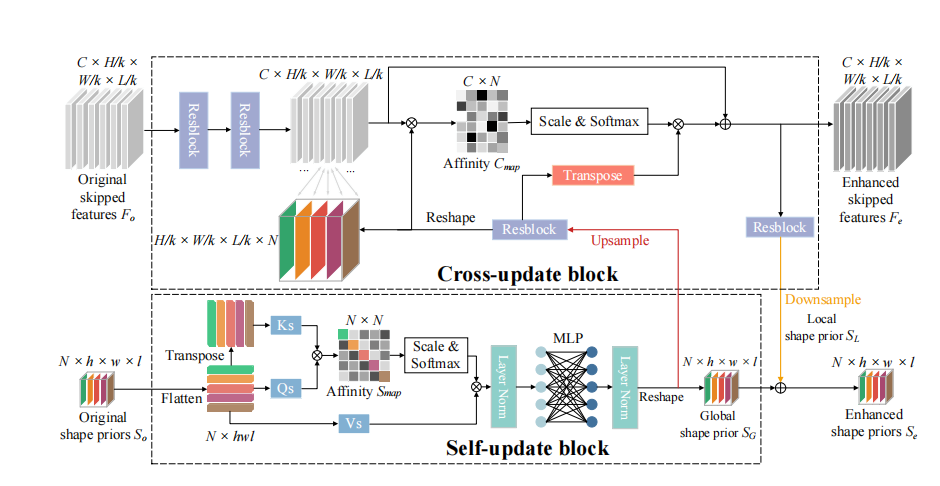
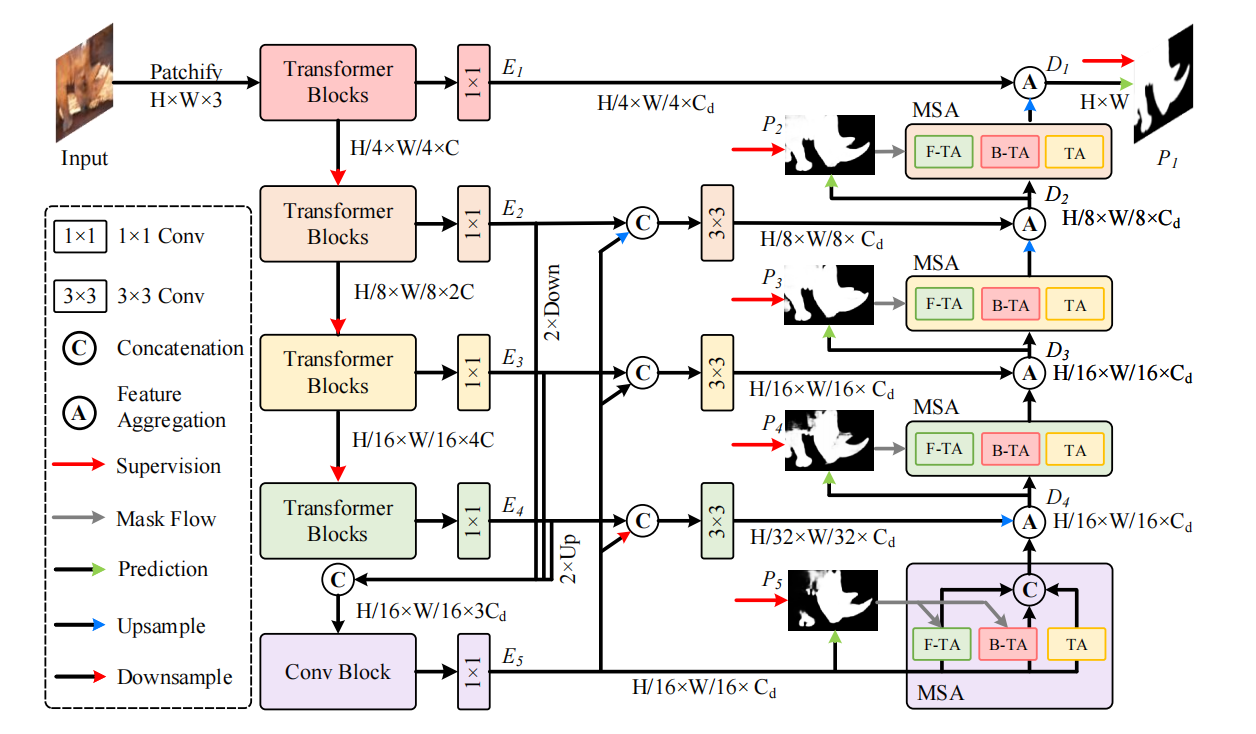
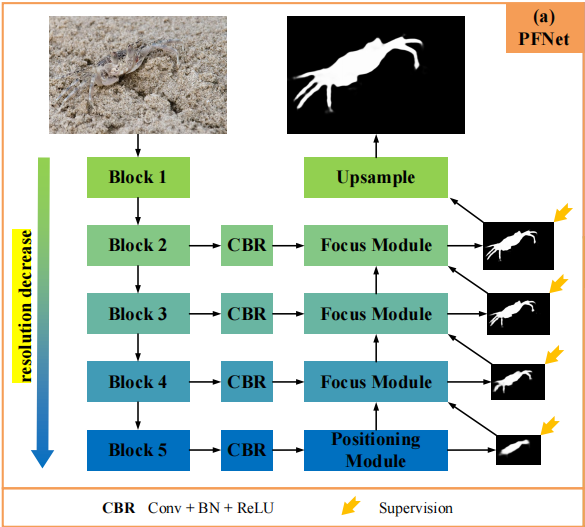
论文地址:Learning with Explicit Shape Priors for Medical Image Segmentation 1 Introduction 在医学图像中,不同的器官或病灶通常具有特定的形状和结构,这些形状和结构信息对于分割模型来说非常关键,因此先前的许多工作尝试利用形状先验来设计分割模型,以获得具有解剖形状信息的更…
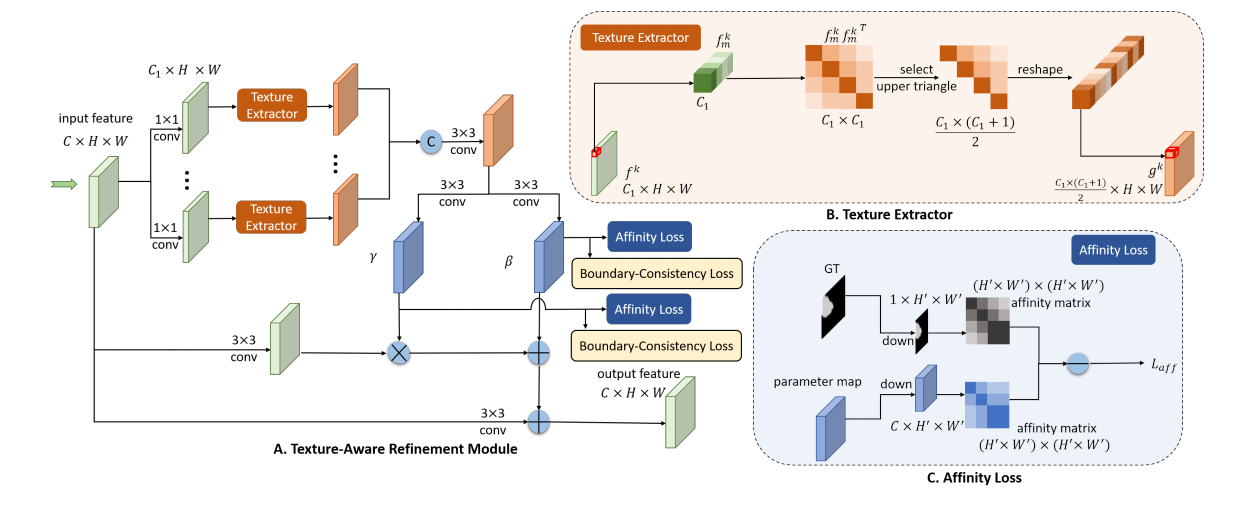
论文地址:Deep Texture-Aware Features for Camouflaged Object Detection 1 总览 通过学习纹理相关的特征,增大伪装目标和背景之间细微的差别,来更好的发现伪装目标。作者通过计算特征的协方差矩阵提取纹理特征,设计了相似度损失去学习参数图来放大背景和伪装目标之间的细微差异,用边缘一致性损失去完善…
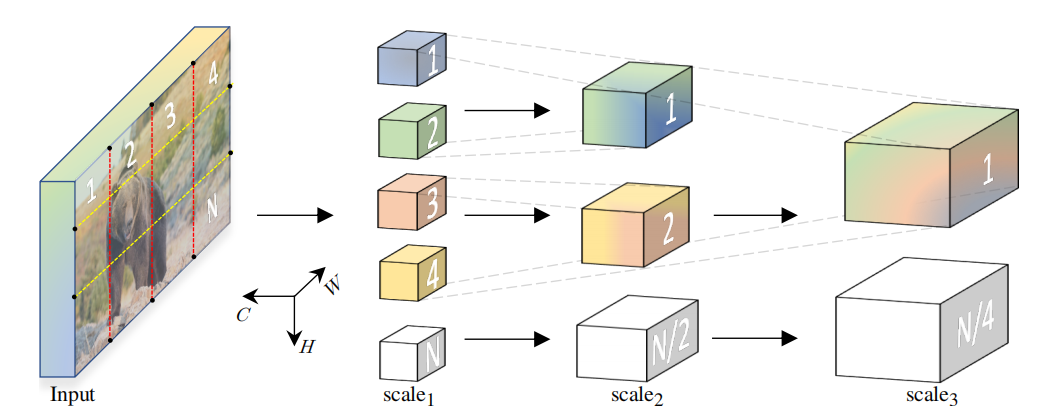
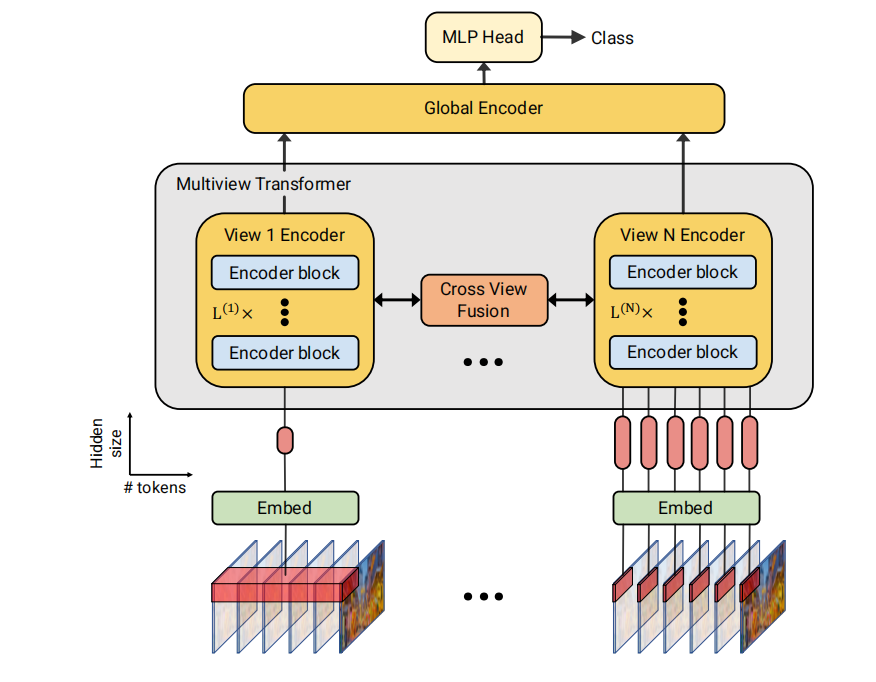
论文地址:Multiview Transformers for Video Recognition CVPR2022 文章是基于ViViT进行改造的 1 研究背景 在图像领域,多尺度处理通过金字塔结构实现。为了视频中的时间多尺度,以前SlowFast是有了2个分支。但是使用一个金字塔结构时,时间空间信息会因为下采样会有一部分信息的丢失。比如Slo…
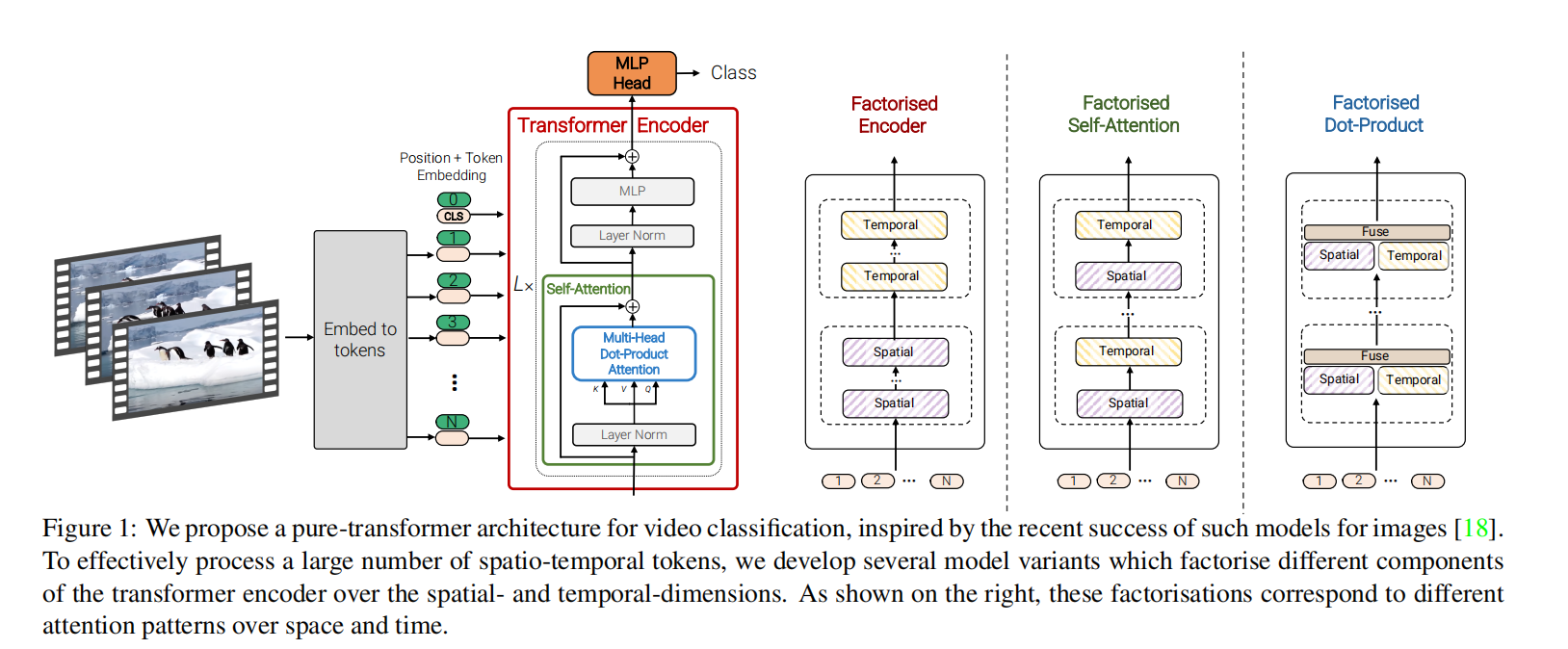
论文地址:ViViT: A Video Vision Transformer 0 divided attention divided attention是ViViT的先验知识,它在Is Space-Time Attention All You Need for Video Understanding?这篇文章中提出,我们知道,视频区别于图片,除了空…