论文地址:Frequency Perception Network for Camouflaged Object Detection
1 Introduction
现在的方法大多在RGB域内进行伪装目标识别,通过纹理不一致性来初步发现伪装目标。在图像频率域里,高频通常描绘图片的细节,低频通常描绘图片的轮廓特征。作者在文章中提出了两阶段识别网络——FPNet:先用FPM module来挖掘频域特征,用频率域特征发现定位伪装目标的突破点;第二阶段是发现细节,精细定位,这一阶段在先验的指导下,利用跨层特征逐渐生成camoufalged masks。
2 Methods
2.1 Overall Architecture
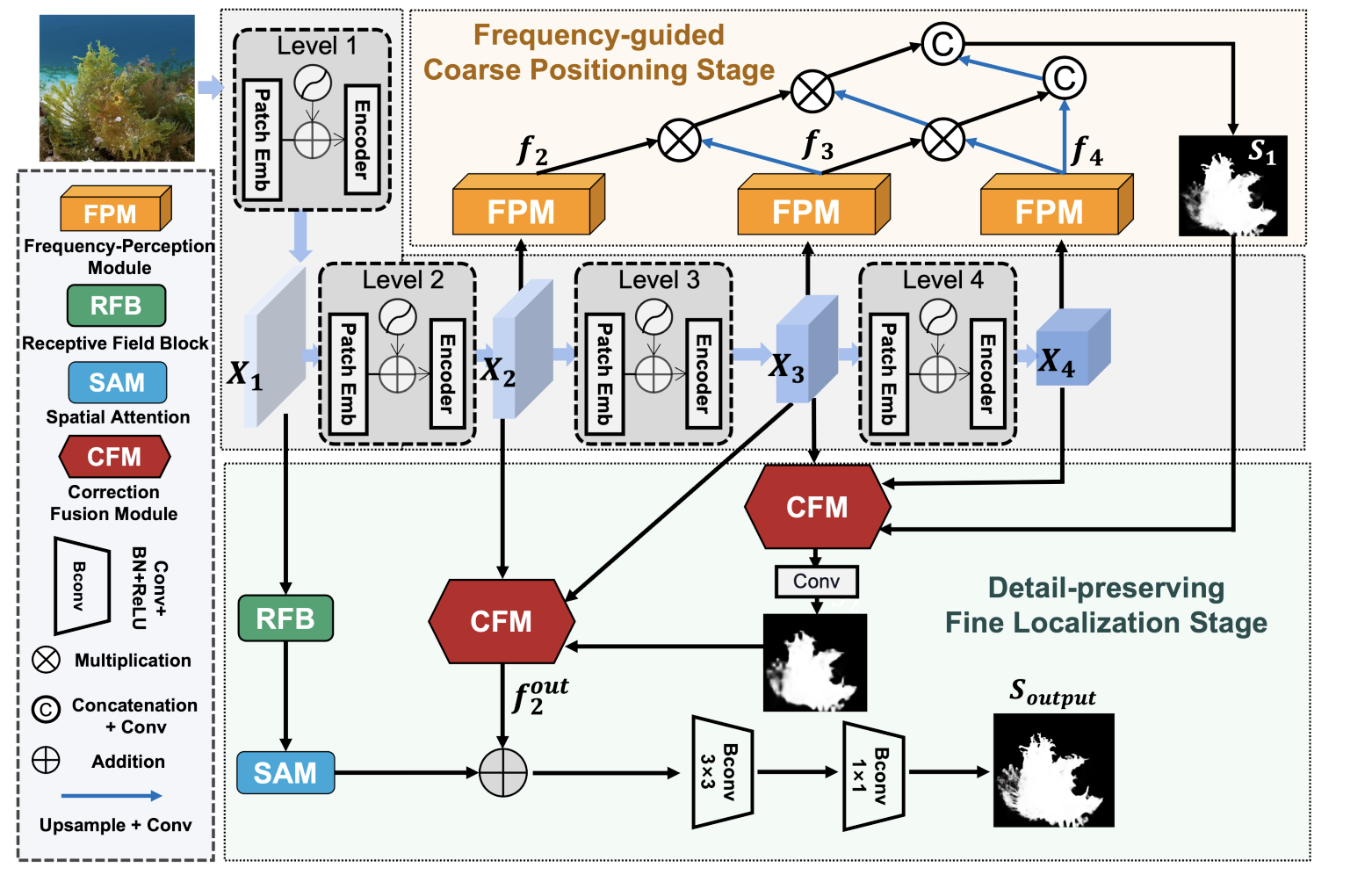
首先使用FPM module在backbone输出的特征上提取频域特征,并采用neighborhood connection获得了一个初步的、粗略的伪装目标图\(S_1\)。然后在\(S_1\)作为先验进行指导,把backbone输出的特征送入correction fusion module进行精细化处理。最后把高分辨率的特征送进recetive field block,其得到的输出域CFM的输出相结合,弥补一些细节信息,得到最终的camouflaged mask。
2.2 Frequency-guided Coarse Positioning stage
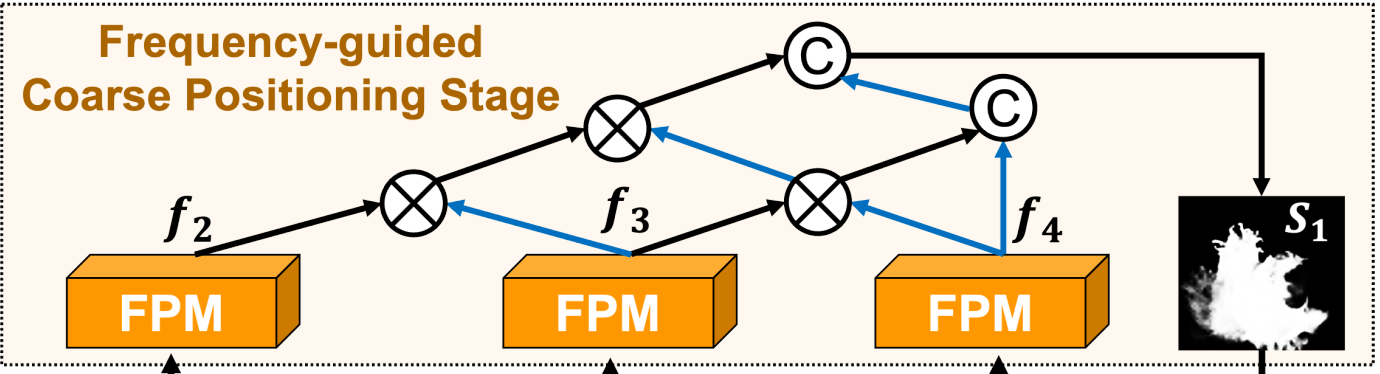
低频通常含有缓慢变化的区域,如大块的色块;高频区域通常包含剧烈的亮度变化,比如边缘等。作者以这个准则为灵感,将特征分为高频特征和低频特征。
首先,作者采用Octave Conv来提取低频和高频特征,这是一种端到端的方式。
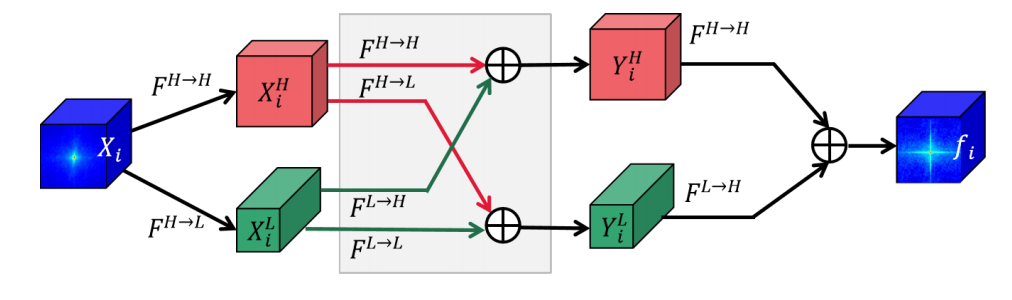
FPM的计算方式如下:
\[f_i=\text{Resize}(Y_i^H)\oplus\text{Resize}(Y_i^L),\]
其次,作者采用neighborhood connection的方式把multi-level的FPM的输出进行融合
\[\left.\left\{\begin{array}{l}f’_4=\mathscr{g}\uparrow(f_4),\\f’_3=f_3\otimes\mathscr{g}\uparrow(f_4)\\f’_2=cat(f_2\otimes\mathscr{g}\uparrow(f’_3),cat(f’_3,f’_4)),\end{array}\right.\right.\]
\(\mathscr{g}\)是upsampling,\(\otimes\)是element-wise multiplication。
2.3 Detail-Preserving Fine Localization stage
2.2中的阶段主要是通过频域去发现、定位一些突破点,但是整体性、准确性还是不够,这一阶段就是为了发现细节、精细定位。作者在这一阶段使用了CFM和RFB模块。
2.3.1 Correction Fuison Module
总体来说,这一模块就是用先验mask图提纯特征,即选取那些和camouflaged objects关联度最高的特征,然后用这个特征去和其他层的特征做cross-layer interaction。
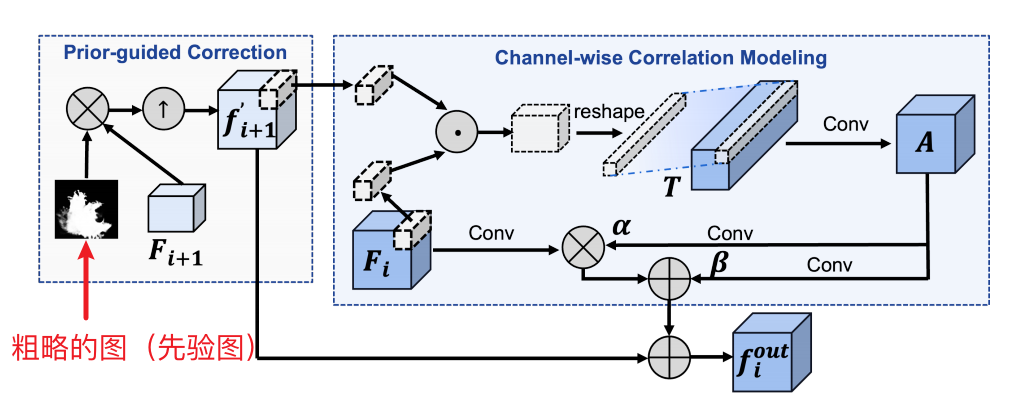
首先,进行purify,选取那些和camouflaged objects关联度最高的特征:
\[f_{i+1}^{^{\prime}}=\text{Upsample}(F_{i+1}\odot S_g),\]
然后是cross-layer interaction,作者使用attention的方式进行交互,计算\(F_i\)和\(f_{i+1}^{^{\prime}}\)在每一个像素位置处的inner product。这么说可能有点抽象,具体来说,假如\(F_i\)和\(f_{i+1}^{^{\prime}}\)的shape是(C, H, W)=(64, 22, 22),\(F_i\)和\(f_{i+1}^{^{\prime}}\)在每一个像素位置处由64个值,\(F_i\)中64的每个值和\(f_{i+1}^{^{\prime}}\)中的64个值相乘,最后得到64✖️64个值,一共有22✖️22个位置,因此得到的输出是(64✖️64, 22, 22),这个输出就代表了\(F_i\)和\(f_{i+1}^{^{\prime}}\)之间的通道共性或者关联度或共同信息,然后用这个共同信息去修正(modulation)\(F_i\):
\[f_i^{out}=f_{i+1}^{‘}+\operatorname{conv}(F_i)*\alpha+\beta.\]
然后对于高分辨率的特征\(X_1\),使用RFB和SAM扩大感受野和高亮空间特征信息。在于CFM的输出结合,得到最终输出识别图\(S_{out}\):
\[S_{output}=Bconv(Bconv(SAM(RFB(X_1))\oplus f_2^{out})),\]
3 Experiments

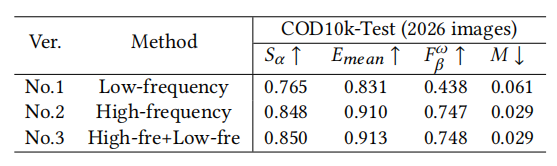
上图是FPM的消融实验,只用高频是比低频效果好的,说明高频对于识别更有帮助,这也符合人眼,人们通常利用高频信息来把伪装目标从区域中剥离出来。从结果图中可以看出,高频可以预测出来物体的关键区域,低频可以预测出来整体轮廓,尽管有一些背景区域的干扰。

从上图可以看出来,低频(c)更加关注整体组成,而高频(d)描绘了边缘细节信息。将这两者结合,模型就可以聚焦于关键区域(e),将物体从背景中剥离出来