1 Why instructBLIP?
视觉语言任务通常更加多样,更加复杂,因为他有视觉模态的输入,而视觉模态的输入可能来自不同的域。所以说,一个统一的模型能泛化到不同的任务,泛化到一些没见过的数据,是很重要的。之前的工作大致分为两类,一类是多任务学习,把不同的视觉语言任务变成相同的输入输出格式,进行训练,但是发现它们在没见过的任务和数据集上表现比较差。另一类是基于大语言模型,附加一个视觉组件,基于image captions数据集训练,也就是BLIP2,它的预训练数据集是十分受限的,让其不能很好的泛化到除了描述以外的任务。
因此作者使用instruction tuning训练一个通用模型,解决一系列视觉语言任务。通过使用instruction tuning,极大增强了模型泛化性,在各种数据集上的zero-shot性能得到提升,并且在下游任务fintune上也达到SOTA。
简单来说,就是在BLIP2的基础上又加入了一些instruction format的训练集继续预训练。改进Q-Former,支持instruction tuning。使用数据集平衡策略提升instruction tuning数据集的稳定性。
2 Method
2.1 Dataset
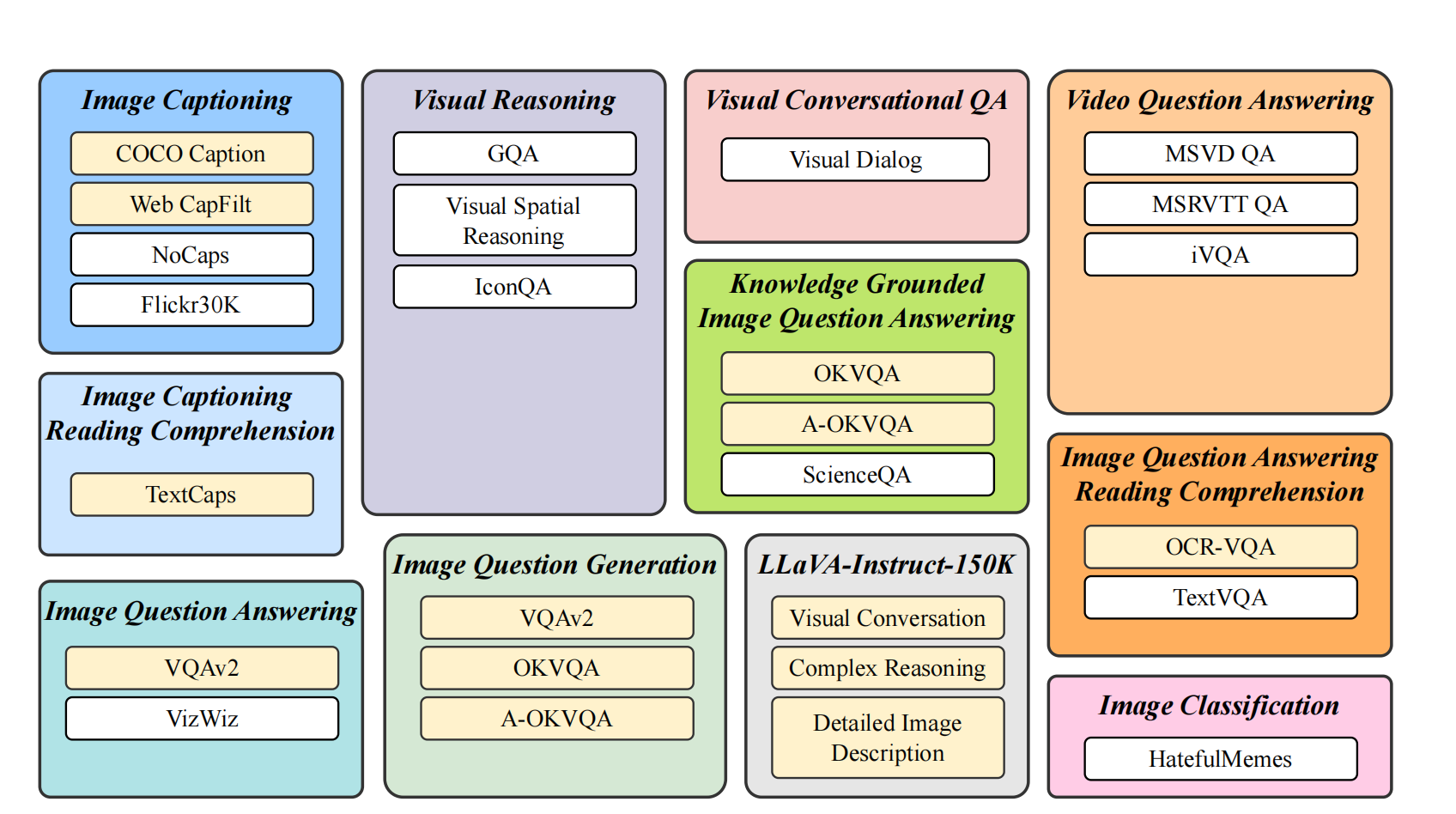
上图是instructBLIP额外使用的数据集,即使用BLIP2的checkpoint初始化,然后在上图数据集中进行训练。数据集一共包括11个任务,26个数据集,对于每个任务,都手工创建了10~15个独特的instruction模版,对于LLaVA150k没有创建模版,因其本身就是instruction的形式。上图中,模型在黄色数据集(held-in)上训练,在白色数据集(held-out)上测试其zero-shot性能。
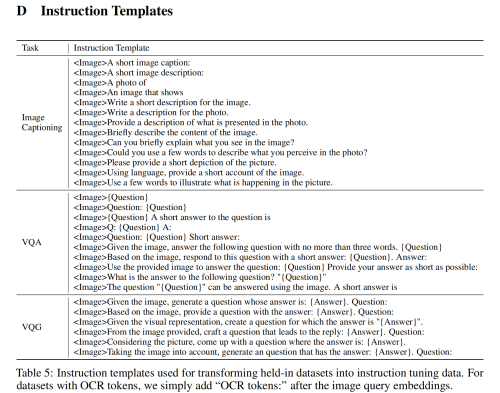
下图是instruction templates:
2.2 Model Architecture
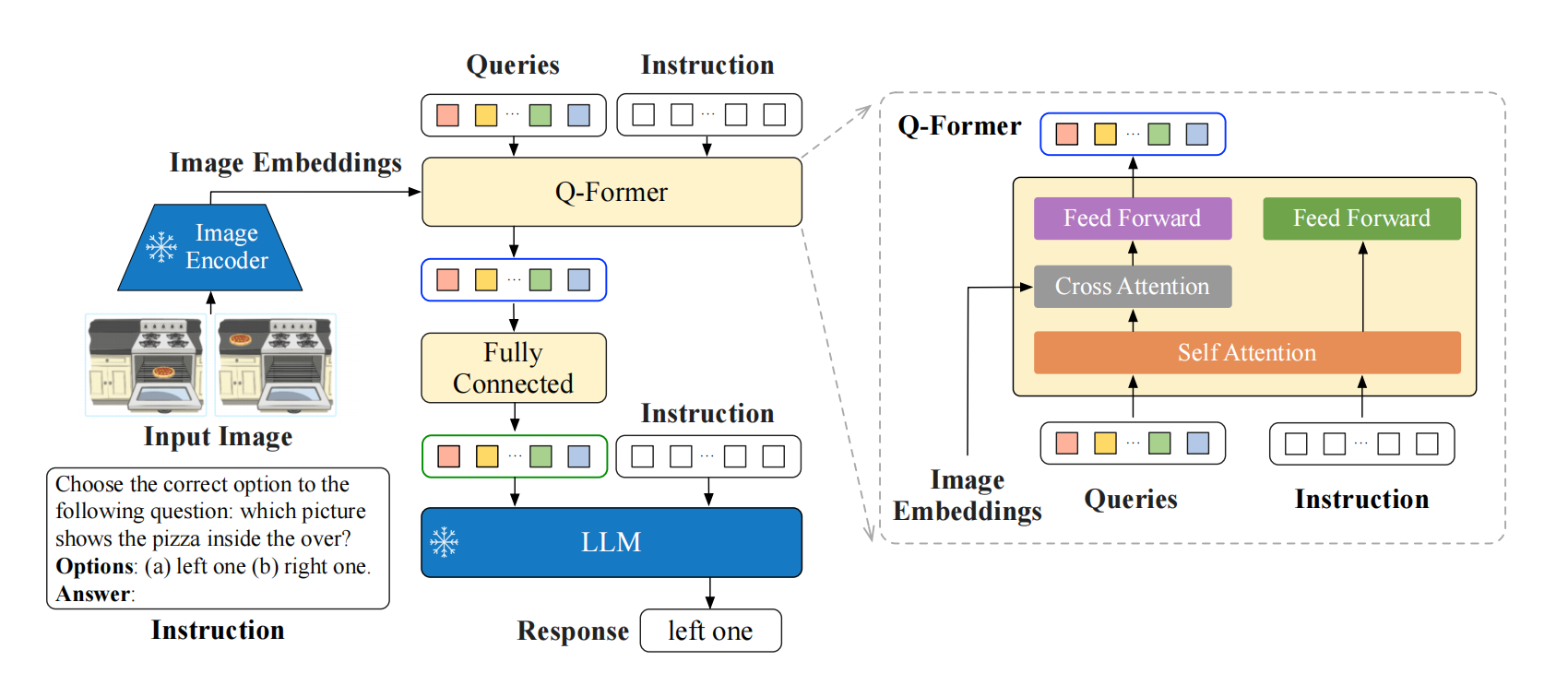
模型结构如上图所示,和BLIP2一样,都会经过two stage pretraining。然后,使用instruction tuning在之前所说的数据集上训练Q-former。instruction的text会经过text encoder,其通过bidirectional self attention和query进行交互,让query内含instruction信息,更能抓取instruction相关的视觉特征。
2.3 Datasets Balancing
不同数据集之间尺寸差异比较大,因此作者提出平衡策略,对于\(D\)个数据集:\(\{S_{1},S_{2},\ldots,{S_{D}}\}\),一个样本从数据集\(d\)中被选中的概率为:
\[p_d=\frac{\sqrt{S_d}}{\sum_{i=1}^D\sqrt{S_i}}\]
除此之外,作者还对特定的数据集添加权重,因为不同的任务、数据集可能需要不同的训练密度。