论文地址:Learning with Explicit Shape Priors for Medical Image Segmentation
1 Introduction
在医学图像中,不同的器官或病灶通常具有特定的形状和结构,这些形状和结构信息对于分割模型来说非常关键,因此先前的许多工作尝试利用形状先验来设计分割模型,以获得具有解剖形状信息的更好掩模(mask)。就是引入形状先验可以帮助分割模型在分割过程中更好地考虑和利用目标物体的形状信息,从而提高分割性能。
再introduction里,作者介绍了Implicit shape models(隐式形状)和Explicit shape models(显式形状)。
- 其中implicit shape主要是通过attention module注入到整体模型中,来增强encoder得到的features,让他们聚焦到具有特定形状的前景区域。将implicit shape再细分,可以分为Convolution-based attention和self-attention。Convolution-based attention的例子有BB-UNet(带有先验框的UNet)、Attention UNet、CBAM等。但是这些Convolution-based不能增大感受野,并且不能建模长距离关系。另一种是self-attention。通过query、key、value进行计算。可以建模长距离依赖,但是由于缺少归纳偏置,需要很大的数据集进行训练。
- Explicit shape分为atlas-based models、Gaussian Mixture Model还有作者提出的UNet with SPM,其示意图如下。
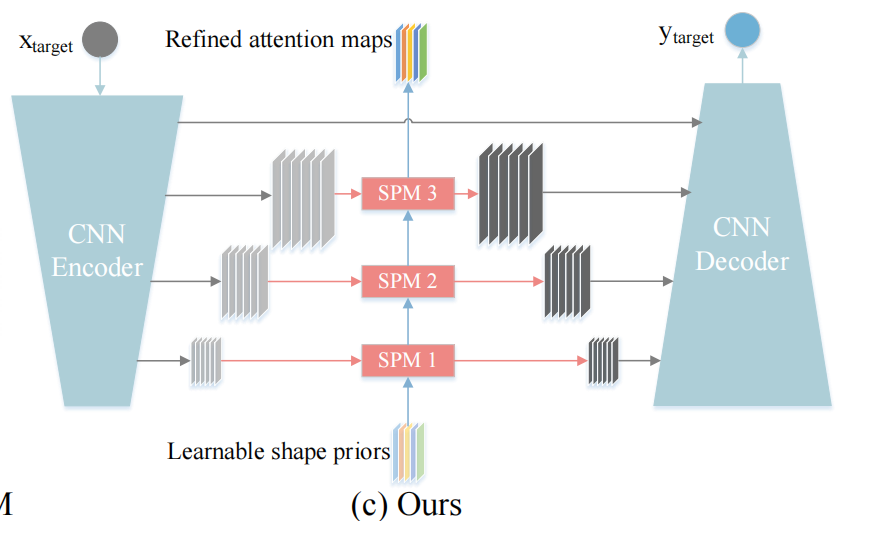
2 Shape Prior Module(SPM)
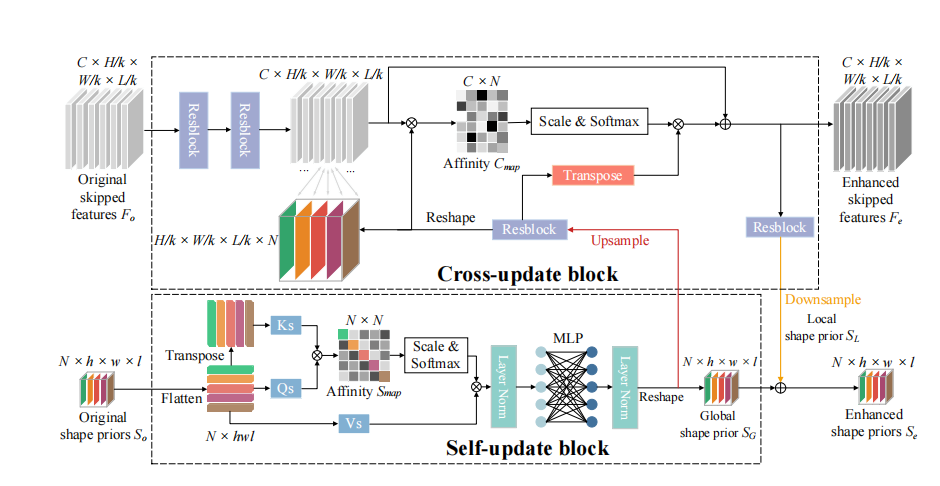
SPM输入是原始跳跃特征\(F_o\),原始形状先验\(S_o\),输出是增强过后的跳跃特征\(F_e\),增强过后的形状先验\(S_e\).SPM由两部分组成,分别是Self-update block、Cross-update block。
- Self-update block: 通过attention module提取全局形状先验,以帮助定位区域
- Cross-update block: 以全局形状先验为指导,通过卷积特征获得局部形状先验,可以获得具有细节特征的、精细化的skipped features
在源码中,可以看出,learnable shape priors是一组可学习的参数
self.learnable_shape_prior = nn.Parameter(torch.randn(1, out_channel, config.n_patches))
这组参数可以随着训练不断更新,当训练完成后,是具有泛化性的参数,代表了整个数据集的形状先验。在推理阶段,对于每个不同的输入,会根据SPM动态地生成最优地shape prior。
SPM示意图如下:
2.1 Self-update block
旨在引入能够定位目标区域的显式形状先验的基础上,形状先验的大小So是N×空间维度。N表示类的数量,空间维度与补丁大小有关。为了缓解感受野有限的缺点,本工作考虑了形状先验内的长程依赖性。具体而言,提出了自更新块(SUB)来对类之间的关系进行建模,并生成具有N个通道之间相互作用的全局形状先验。受自注意机制的启发,构建了N类之间的自注意Smap的亲和图,以描述形状先验的每个通道之间的相似性和依赖性关系。再采用Smap加权Vs,随后经过多层感知机MLP和层归一化处理,得到全局形状先验\(\mathcal{S}_\mathcal{G}\)
\[S_{map}=Softmax(\frac{Q_s(\mathcal{S}_o)\times K_s(\mathcal{S}_o)^T}{\sqrt{N}})\]
\[\begin{aligned}\mathcal{S}’&=LN(S_{map}\times V_s(\mathcal{S}_o))+\mathcal{S}_o\\\mathcal{S}_\mathcal{G}&=LN(MLP(\mathcal{S}’))+\mathcal{S}’\end{aligned}\]
2.2 Cross-update block
引入显式形状先验給SUB带来了全局上下文信息,但不具有精确的形状和轮廓信息。因为SUB缺乏归纳偏置,无法建模局部视觉结构和定位各种不同尺度的对象。
为了解决这个限制,论文提出交叉更新块CUB。受到卷积核固有的局部性和尺度不变性的归纳偏置的启发,基于卷积的 CUB 为 SPM 注入归纳偏置,以获得更精确的局部形状信息。此外,基于编码器中卷积特征具有定位区分性区域的显著潜力的事实,论文在原始跳跃特征Fo和形状先验So之间进行交互。
Cross-update有两个作用:
- shape prior中包含global的信息,可以帮助\(F_o\)更好的定位。
- \(F_o\)是卷积特征,内含许多细节信息,通过cross-update,可以让shape prior具有更多的细节、边缘信息。
Cross-update计算过程:
- 计算C channels的\(F_o\)和N channels的\(S_o\)的关系矩阵\(C_{map}\),但是\(F_o\)和\(S_o\)大小不同,首先要对\(S_o\)进行upsample,然后再计算\(C_{map}\),它是一个\(C \times N\)的矩阵
\[C_{map}=Softmax(\frac{Q_c(F_o)\times K_c(Upsample(\mathcal{SG}))^T}{\sqrt{N}})\]
- 然后\(C_{map}\)作用在\(\mathcal{S}_\mathcal{G}\)去refine\(F_o\)。以上两步可以这样理解:\(F_o\)作为query去查询\(S_o\)中能帮助它的信息,加到\(F_o\)上得到\(F_e\)
\[F_e=C_{map}\times V_c(Upsample(\mathcal{S}_{\mathcal{G}}))+F_o\]
- 局部形状先验(local shape prior)可以由\(F_e\)downsample得到,这里面包含里细节信息,比如边缘、拐角等。最后,增强的shape prior由local和global相加得到。
\[\begin{aligned}\mathcal{S}_{\mathcal{L}}&=Downsample(Conv(F_e))\\\mathcal{S}_e&=\mathcal{S}_{\mathcal{L}}+\mathcal{S}_{\mathcal{G}}\end{aligned}\]