1 Why LLaVa?
现在的大语言模型取得了非凡的成果,比如GPT、LLaMA等,然后他们还都在machine-generated high-quality instruction-following data训练,提升模型的的对齐和指令跟随能力。但是他们都是text-only。
作者提出的LLaVa,是第一个把instruction tuning带到多模态领域。作者使用GPT4,把图片文本对变成合适的指令跟随的格式,让模型在上面训练,在Science QA达到SOTA。
2 GPT-assisted Visual Instruction Data Generation
作者在这个使用text-only GPT4去生成instruction-following data。因为使用的是单模态GPT,因此看不见图片,需要把图片(来自COCO)转换为符号化模式送给GPT4:
- Captions:从不同角度描述图片场景
- Bouding Boxes:定位场景中的物体,每个box有其空间位置和物体概念。
如果只是产生简单的视觉问答,生成的数据集会缺少多样性和深度推理。因此作何使用三种Prompt去提示GPT4去生成三种类型的问答:
- Multi-turn Conversation:让GPT4根据图片产生一些列问题,并模仿一个助手的语气去回答它。
- Detailed description:作者会创建一些列问题列表,这些问题带有明显的意图:让其总结、描述图片。对于每张图片,会从问题列表里面随机选取一个去问GPT4关于这张图片的内容。
- Complex Reasoning:以上两种类型侧重于视觉内容本身,基于此我们进一步创建深入的推理问题。
最终,在COCO数据集上,总共有158K个样本,其中包含58k对话,23k描述,77k推理。以下展示作者创建multi-turn conversation对GPT4使用的prompt。

这段代码定义了一个 messages 列表,是用于构造 GPT对话输入 的(用于 GPT-4 API 的调用格式)。它的作用是让 GPT-4 扮演一个视觉助手,根据图像的描述,生成一段和人“对话”的样本(问答对),从而构建 instruction-following 数据。后面的fewshot_sample的作用是,LLaVA在调用GPT生成新的问答对之前,先喂给GPT一些“样本”问答对,告诉它什么风格的问题和答案是“好的”,这样GPT会照着模仿生成。接下来append query,其包含query[‘context’],就是“what you see are provided with five sentences”,是图像的描述。然后GPT4会产生response,从query[‘response’]收集他们。
可以看到,产生prompt的conversation里面会包含一些complex的问题,甚至会牵扯到一些推理,但这些复杂问题只是 conversation 的一部分,并非作为单独类别生成,所以它属于 conversation 内嵌复杂推理的问题,但不等于专门生成 Complex Reasoning 类型。
以下是各个类型的instruction data的例子:
(Multi-turn) Conversation:
{
"id": "000000033471",
"image": "000000033471.jpg",
"conversations": [
{
"from": "human",
"value": "What are the colors of the bus in the image?\n<image>"
},
{
"from": "gpt",
"value": "The bus in the image is white and red."
},
{
"from": "human",
"value": "What feature can be seen on the back of the bus?"
},
{
"from": "gpt",
"value": "The back of the bus features an advertisement."
},
{
"from": "human",
"value": "Is the bus driving down the street or pulled off to the side?"
},
{
"from": "gpt",
"value": "The bus is driving down the street, which is crowded with people and other vehicles."
}
]
}
detailed description:
{
"id": "000000442786",
"image": "000000442786.jpg",
"conversations": [
{
"from": "human",
"value": "What do you see happening in this image?\n<image>"
},
{
"from": "gpt",
"value": "The scene depicts a lively plaza area with several people walking and enjoying their time. A man is standing in the plaza with his legs crossed, holding a kite in his hand. The kite has multiple sections attached to it, spread out in various directions as if ready for flight.\n\nNumerous people are scattered throughout the plaza, walking and interacting with others. Some of these individuals are carrying handbags, and others have backpacks. The image captures the casual, social atmosphere of a bustling plaza on a nice day."
}
]
}
complex reasoning:
{
"id": "000000215677",
"image": "000000215677.jpg",
"conversations": [
{
"from": "human",
"value": "<image>\nWhat skill set might someone need to perform such a frisbee trick?"
},
{
"from": "gpt",
"value": "To perform the frisbee trick shown in the image, where the man is passing a frisbee between or underneath his legs, a person would need a combination of skills. These skills include good hand-eye coordination, agility, balance, flexibility, and dexterity. Additionally, the ability to throw and catch the frisbee accurately while maintaining control of bodily movements would also be essential. To perfect the trick, practicing these skills and building up muscle memory through repetition would be beneficial."
}
]
}
3 Visual Instruction Tuning
3.1 Model Architecture
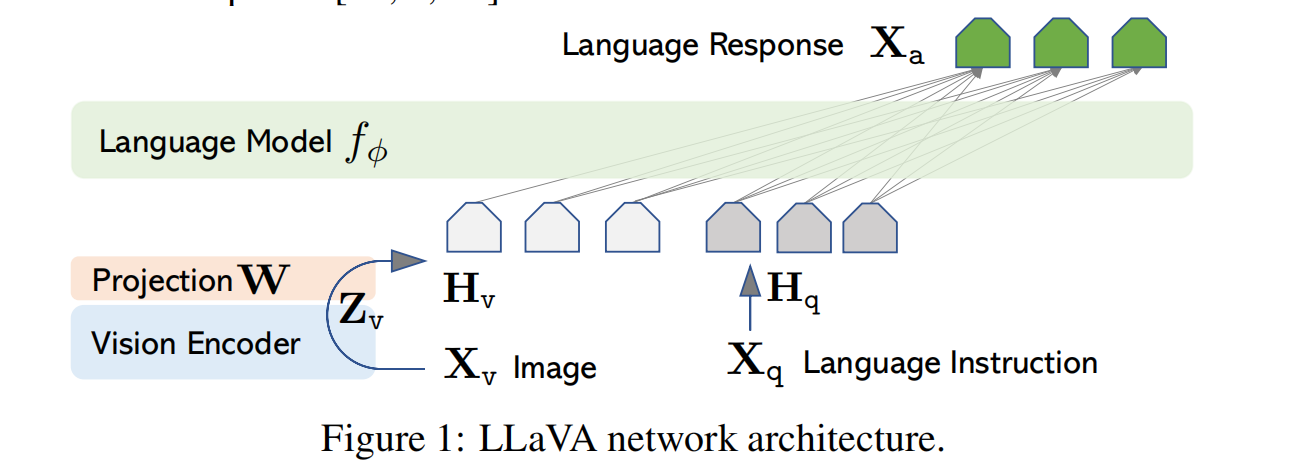
Vision encoder使用CLIP的ViT-L/14,产生视觉特征\(\mathbf{Z_v}=g(\mathbf{X_v})\),然后使用projection layer把\(\mathbf{Z_v}\)变成language embeddings tokens\(\mathbf{H_v}\),其和word embeddings有相同的维度。将instruction \(\mathbf{H_q}\)和\(\mathbf{H_v}\)送到LLM里去生成answer。
3.2 Training details
3.2.1 训练数据格式
对于某张图片\(\mathbf{X_v}\),对于multi-turn conversation data,\((\mathbf{X_q^1},\mathbf{X_a^1},\cdots,\mathbf{X_q^T},\mathbf{X_a^T})\),会将其组织成一个序列送给模型。在t时刻的instruction为:
\[\left.\mathbf{X}_{\mathrm{instruct}}^t=
\begin{cases}
& \text{Randomly choose }\left[\mathbf{X}_\mathrm{q}^1,\mathbf{X}_\mathrm{v}\right] & \mathrm{or~}\left[\mathbf{X}_\mathrm{v},\mathbf{X}_\mathrm{q}^1\right], & \text{the first turn }t=1 \\
& \mathbf{X}_\mathrm{q}^t, & \text{the remaining turns }t>1 & &
\end{cases}\right.\]
按照上述内容,一次性把整个多轮对话(包括所有问题和回答)全部拼接成一个长序列(下图),作为输入,然后模型通过自回归(auto-regressive)方式学习生成这个完整序列中的目标部分。

模型在绿色的的位置上计算loss。计算过程如下:
\[p(\mathbf{X_a}|\mathbf{X_v},\mathbf{X_{instruct}})=\prod_{i=1}^Lp_{\boldsymbol{\theta}}(x_i|\mathbf{X_v},\mathbf{X_{instruct,<i}},\mathbf{X_{a,<i}}),\]
表示在token \(x_i\)之前的instruct和所有turn的answer(在token \(x_i\)之前)的condition下计算token \(x_i\)的概率,并将其最大化。公式里省略了system message和stop
对于description和reason这两种数据,是single turn的,只有一轮对话,直接把问题和回答弄成一个序列即可。
3.2.2 Two Stage:pretraining and finetuning
1. pretraining for feature alignment
把CC3M过滤到595k图文对,用这些对生成instruction data,并把它们视为single turn conversation,使用的问题是来自Detailed description的问题列表里的随机一种,answer是GT里的original caption。在这个阶段,visual encoder和LLM都冻结,只训练projection,训练其对齐能力。通过这种方式,图像特征\(\mathbf{H_v}\)可以与预训练的LLM词嵌入对齐。这个阶段可以理解为为冻结的LLM训练一个兼容的visual tokenizer。
2.finetuning end-to-end
冻结ViT,训练projection和LLM,来实现多模态的视觉指令跟随。在这个阶段,有两个任务:
- multimodal chatbot:在158K数据集上finetune。
- Science QA:第一个大规模的多模态科学问题数据集,用详细的讲座和解释来注释答案。每个问题都会配一个context,要么是语言,要么是图片。LLaVa需要以自然语言的形式给出推理过程,然后在多个选项中选出答案。作者将其视为single-turn data。question和context视为\(\mathbf{X_{instruct}}\),reasoning和answer视为\(\mathbf{X_{a}}\)。
4 Experiment
这里讲一下作者的在multimodal chatbot实验中的评估方法。
作者使用text-only GPT4(也就是评判官judge)去评估生成的结果。作者从数据中创建出一个三元组,包含图像、GT textual descriptions和问题。LLaVa根据问题和图片生成回答。为了创建一些近似的理论上限,作者使用GPT4,让它根据GT textual descriptions和问题去写一个reference prediction。然后把问题,visual information(text-format)和两者生成的回答,都送进GPT4,让它从多方面对这两个答案进行评分。
在multimodal chatbot,提出了两个bench,分别为
- LLaVa-Bench (COCO):从coco中选出30张图片,然后只用之前所说的数据生成方法生成出90个问题,包含三种问答类型。
- LLaVA-Bench (In-the-Wild):作者选出24个图片,包含了室内和室外场景、表情包、绘画、素描等,每一个图片都配备了一段高详细度、人工整理的描述,还有一些问题的集合。