论文地址:Mutual Graph Learning for Camouflaged Object Detection
1 研究动机
现在的伪装目标检测一般分为两块,一是伪装目标的识别,二是伪装目标轮廓的检测,前者通常是主任务,后者通常是辅助任务,下图中,左图是轮廓检测,右图是伪装目标识别(区域检测)

- 现在的大多数模型中,伪装目标识别(COD)与轮廓检测(COEE)这两个任务之间信息的交互往往被忽略,即使有信息的交互,往往是从辅助任务中提取额外信息来帮助主任务学习,忽视了两者之间合作的共同关系,因为辅助任务往往也可以从主任务中获益。两者可以相辅相成,大多数模型忽视了这一点
- 并且跨任务的信息交流通常只在原始坐标空间或者低维空间建模,这样的信息所包含的语义特征是不充分的
生物学上,捕获一个物体的轮廓是进行伪装目标检测的关键,一个理想的模型应该非常有效的提取轮廓,并把他们与伪装目标识别纳入到一个统一的框架,如此,伪装目标识别和轮廓检测这两个任务可以相辅相成,互相受益。而不是将轮廓检测任务剥离开来,单独为伪装目标识别任务提供帮助。在本篇文章中,作者提出一个统一的模型,让COD和COEE任务两者互相学习,互相帮助
2 模型结构
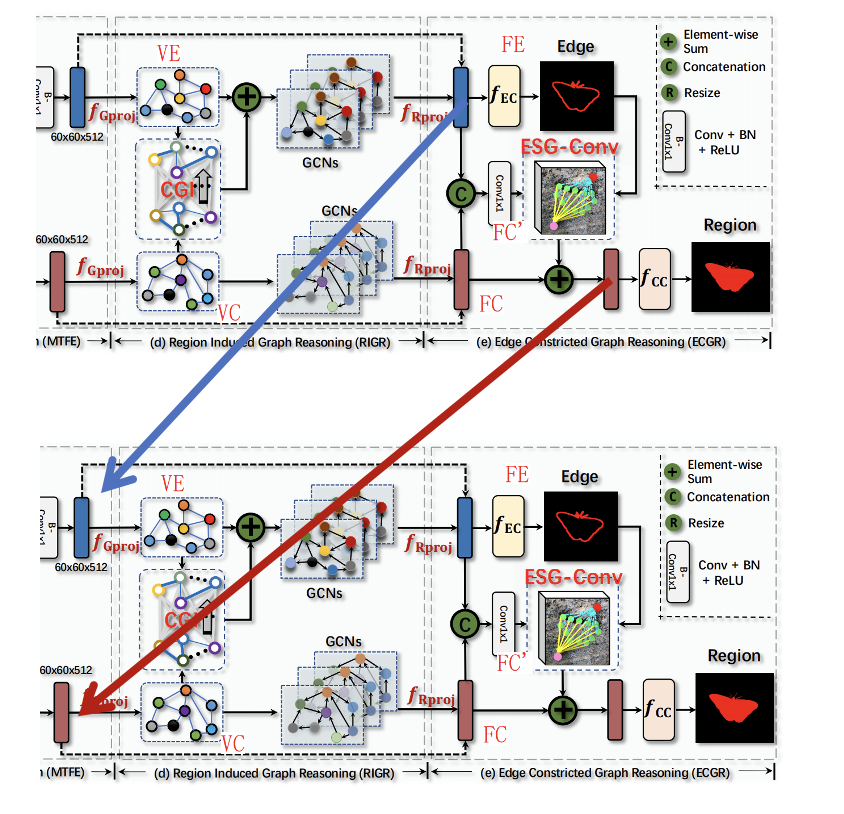
下图是模型的整体结构,从左到右三个模块,分别是MTFE、RIGR、ECGR模块。其中MTFE就是一个ResNet,这里就不再阐述,主要讲一下RIGR模块和ECGR模块
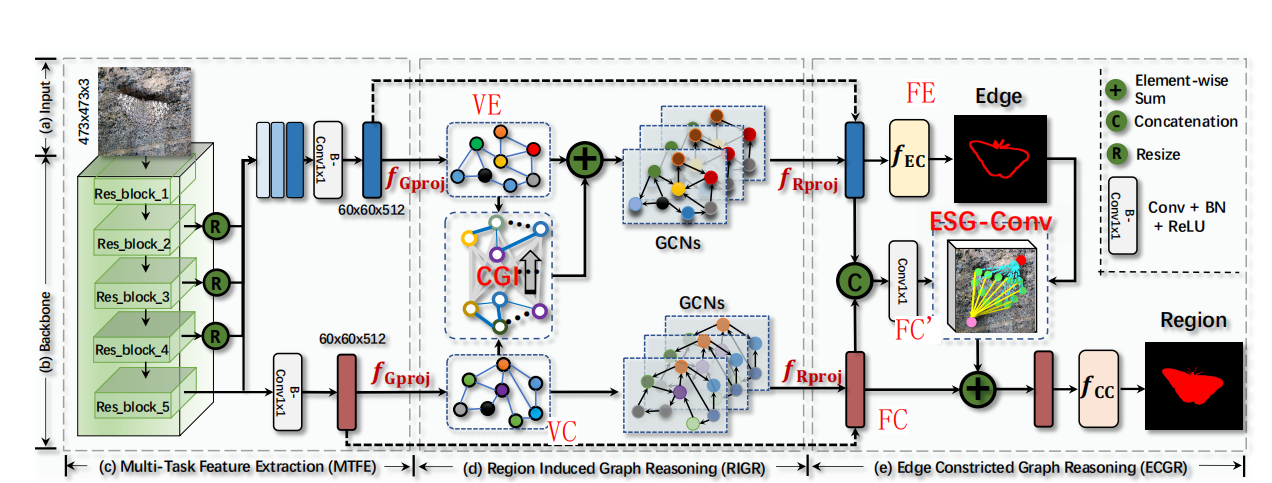
2.1 RIGR:Region Induced Graph Reasoning
用一句话总结这个模块,就是把COD任务中的高阶语义信息信息向COEE中融合,得到带有区域特征的增强地边缘特征。
2.1.1 图映射
首先网络由backbone提取到的三维特征使用图投影,投影到2维上,投影方式如下:
\(\mathbf{F}_{E}\in\mathbb{R}^{\tilde{h\times w\times c}}\)和\(\mathbf{F}_{C}\in\mathbb{R}^{\tilde{h\times w\times c}}\)首先通过一个1×1卷积层先降低一下通道数变为\(\mathbf{F}_{C}^{l}\in\mathbb{R}^{(h\times w)\times C}\mathrm{or}\mathbf{F}_{E}^{l}\in\mathbb{R}^{(h\times w)\times C}.\)
然后作者new了两个矩阵\(W\in\mathbb{R}^{K\times C}\mathrm{~and~}\Sigma\in\mathbb{R}^{K\times C}\),其中\(W\)的每一行\(w_{k}\)代表第k个可以学习的聚类中心。
我们通过下式计算图的每个节点的特征
\[v_{k}=\frac{v’_{k}}{\|v’_{k}\|_{2}},v’_{k}=\frac{1}{\sum_{i}q_{k}^{i}}\sum_{i}q_{k}^{i}(f_{i}-w_{k})/\sigma_{k},\]
\[q_k^i=\frac{\exp(-||(f_i-w_k)/\sigma_k||_2^2/2)}{\sum_j\exp(-||(f_i-w_j)/\sigma_j||_2^2/2)},\]
上式中,\(\sigma_{k}\)就是\(\Sigma\)的每一列,\(v_{k}\)就是\(f_i\)和\(w_k\)之间残差的加权平均,\(v_k\)就是第k个节点的向量表示,所有的\(v_k\)构成图矩阵\(\mathcal{V}\)
通过上面的操作,我们就可以把一个三维空间的特征映射到一个具有K个节点的图上,每个节点的特征长度是C。
除了得到节点之外,我们还要得到图的边,在原论文里,使用如下公式计算邻接矩阵\(\mathcal{A}^\text{intra }=f_{\mathtt{norm}}(\mathcal{V}^\mathrm{T}\times \mathcal{V})\),从这个式子可以看出来,通过计算每个节点和其它节点之间的内积来计算的邻接矩阵(内积可以具有衡量两个向量相似度的意义)。
2.1.2 Cross-Graph Interaction
作者在将COD的高阶语义信息向传输到COEE中时,采用的是注意力机制
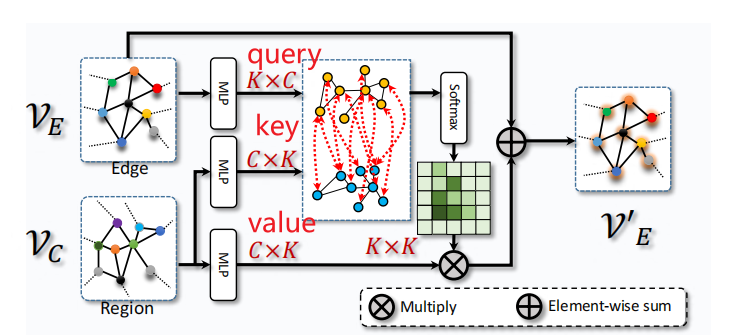
通过MLP层,图的节点特征VE用于生成查询向量,VC特征用于生成Key value对,我们知道,注意力机制的输出是value的加权相加,也就是Vc的加权相加,最后和Ve相加,得到v’e,就是融合了区域特征的边缘特征图,最后把v’e Vc送到GCNs里去推理,再把二维的图结构投影回三维,得到输出,分别是增强后的边缘特征还有经过图卷积的区域特征图
2.2 ECGR:Edge Constricted Graph Reasoning
ECGR模块,用一句话总结,就是利用上一模块得到的增强后的边缘信息特征图,来指导区域特征图的学习
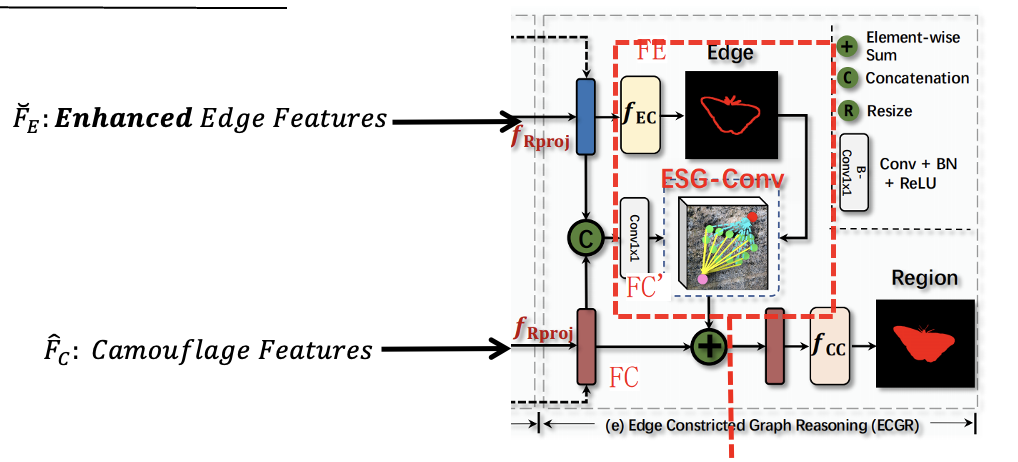
这个模块的输入有两个,就是RIGR模块的输出,分别是增强过后的边缘特征图,还有一个是区域特征图。作者通过ESG-Conv来把边缘信息编码/整合进区域特征图上的。
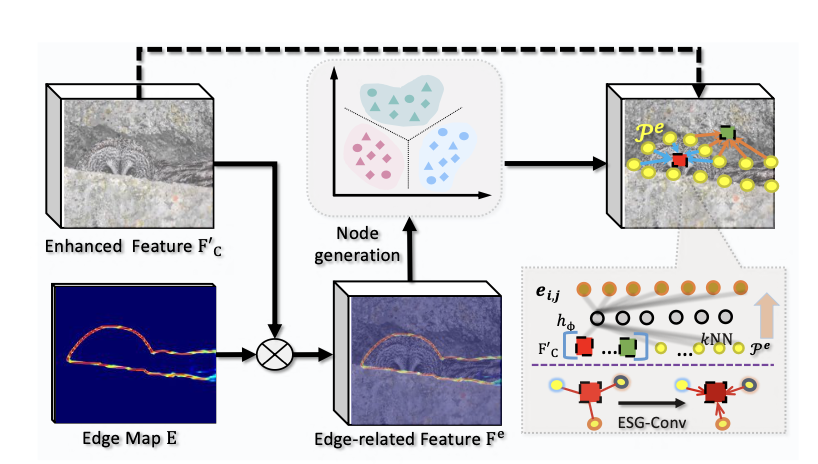
ESG-Conv有两个输入,第一个是边缘图,它是由\(F_E\) 经过一个分类器得到的,第二个是\(\mathbf{F}_{C}^{\prime}\),它是通过\(F_E\)和\(F_C\)做concat然后经过1×1卷积得到的,知道了ESG-Conv的两个输入,我们来看它的内部结构。 首先将两个输入做通道维度上的相乘:\(\mathbf{F}^e=\mathbf{E}\otimes\mathbf{F}_C^{\prime}\),得到\(F^{e}\),然后将\(F^{e}\)投影到图上,得到若干个图的节点。然后利用K近邻算法,我们为\(\mathbf{F}_{C}^{\prime}\)上每一列特征分配k个刚刚计算出的图节点
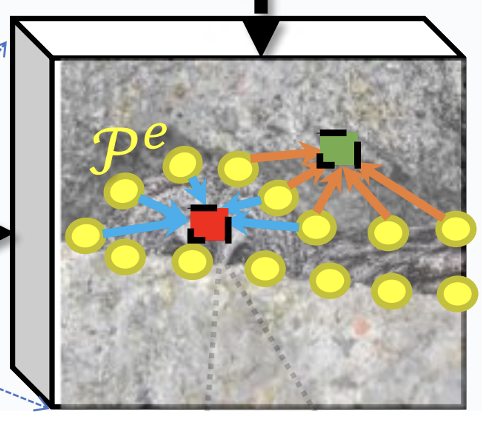
我们放大来看,如图所示,作者取的k为5,也就是说,每个feature都会和5个node相匹配。
\[\mathbf{e}_{i,j}=h_\phi(f_i^{\prime c},p_j^c)=f_{\mathsf{Conv}}(f_i^{\prime c}-p_j^c)\]
\[\check{\mathbf{f}}_i=\max_{j:(i,j)\in\mathcal{E}^e}h_\Phi(f_i^{\prime c},\mathbf{e}_{i,j})\]
对于每个feature,我们通过一维卷积计算feature和他们五个node之间的距离,然后根据刚刚计算出来的距离,还有这个feature它本身,计算得到,该feature的输出,借此,就完成把边缘信息的特征嵌入到区域特征图中去。通过这两个模块,我们就可以实现将区域信息整合到边缘特征图中,帮助边缘特征更好的学习,然后边缘特征图反过来还能指导区域特征的学习。
2.3 Recurrent Manner
\[\left.\left\{\begin{array}{ll}&&\breve{\mathbf{F}}_E^{(t+1)}=f_{\mathtt{RIGR}}(\breve{\mathbf{F}}_C^{(t)},\breve{\mathbf{F}}_E^{(t)}),\\&&\breve{\mathbf{F}}_C^{(t+1)}=f_{\mathtt{ECGR}}(\breve{\mathbf{F}}_C^{(t)},\breve{\mathbf{F}}_E^{(t+1)},\mathbf{E}^{(t+1)}),\end{array}\right.\right.\]
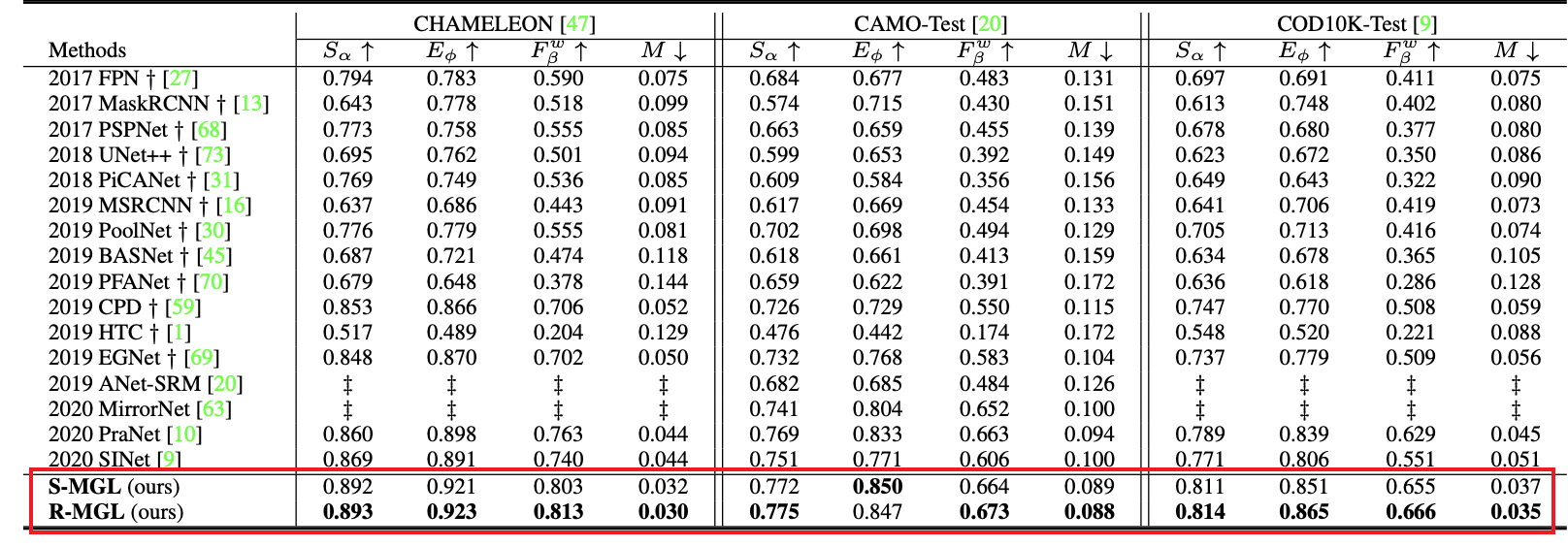
3 实验结果
作者分别做了对比实验和消融实验
对比实验:
消融实验:

4 展望和不足
4.1 展望
这种mutual learning的思路是值得借鉴的,多任务之间不区分明显主次关系,而是互帮互助,相互学习。这种思路可以应用在其他任务上,比如说,全景分割
全景分割(panoptic segmentation)就是同时进行语义分割和实例分割,既要对像素进行语义标记,还要对不同实例的像素进行区分
这两个任务或许也可以应用本论文的思想,可能会达到更好的效果

4.2 不足
- 论文里在递归的内容上并没有过多探讨,只是默认设置递归层数为2,没有探讨递归层数不同对模型的影响
- 其次,论文里的递归只是简单的堆叠,或许在层与层之间加上残差连接会达到更好的效果
- 论文里采用了图学习,但是并没有体现图学习的特点,图学习善于处理的是非欧几里得数据,但是论文在进行将特征投影到图上时,每个节点与每个节点均有关联,也就是说每个节点的邻居节点数量都相同,那么就没有必要使用图学习了,最终实现效果可能不如传统卷积好。
5 思考
1 RIGR模块中,为什么能将COD中的高阶语义信息传输给COEE的呢?
边缘特征生成查询向量(Query),区域特征生成值向量(Value),注意力机制中,会根据每个Query感兴趣的Value向量,把Value以一定的加权组合返回给它,也就是说,对于边缘图上的每一个点,查询其周围有没有区域,借助区域去诱导Edge的修正。
2 ECGR模块中,为什么COEE任务能指导COD任务?
ECGR的全程是Edge Constricted Graph Reasoning,其中,Constricted这个单词非常关键,也就是说,边缘在ECGR模块中,起的是一个限制作用,而不是决定性作用,最终的决定权还是在COD任务手中,COD自身具有判断能力,由COD判断该像素是否为区域。
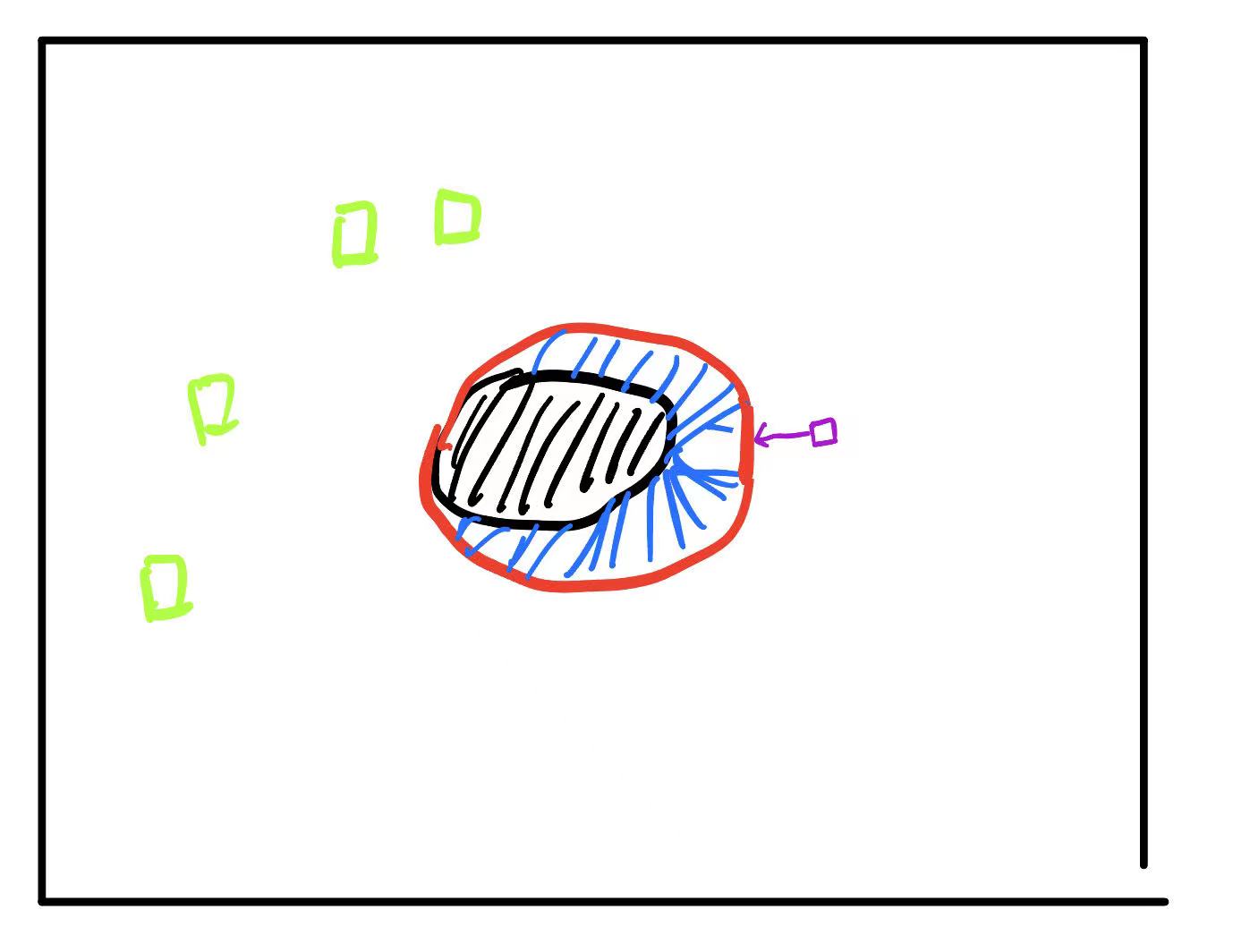
我们从计算公式可以看出,ESG-Conv层学习的是每一个feature和其最近的五个边缘特征对应的node的差值。
打一个比方,在ECGR中,COD就是大法官,COEE就是目击证人,每一个feature就是潜在的嫌疑人,COEE的作用就是提供证据协助COD这位大法官判别feature是否为“犯罪人员”。在下图中,黑色阴影区域就是COD识别出来的Region,红色是COEE得到的Edge。对于COD这位大法官来说,绿色的feature已经有充足的证据证明他们为“好人”,不需要COEE的干预。对于蓝色阴影部分,由于COD证据不充分,不能充分的判断他们是“好人”还是“坏人”,需要COEE这位目击证人来告诉COD,他们是好是坏,Constricted就体现在这里。我们从计算公式可以看出,ESG-Conv层学习的是每一个feature和其最近的五个边缘特征对应的node的差值。蓝色阴影区域他们和Edge的差值非常小,这就为COD提供了充足的“在场证明”,再加上COD自己的判断,就能对蓝色阴影区域“判刑”——认为他们也是Region。
有人可能会问:为什么紫色的这个feature和Edge的差值也很小,但他没有被判别为region?我们再来看一下每一个feature是如何计算输出的
\[\check{\mathbf{f}}_i=\max_{j:(i,j)\in\mathcal{E}^e}h_\Phi(f_i^{\prime c},\mathbf{e}_{i,j})\]
从上式可以看出,在计算输出时,不仅输入了差值\(\mathbf{e}_{i,j}\),还输入了\(f_{i}^{\prime c}\),\(f_{i}^{\prime c}\)也就代表了COD法官自身的判断(法官在断案的时候不能完全听从目击证人,肯定要加入自身对案件的判断),紫色的\(f_{i}^{\prime c}\)周围都是非Region,COD也就有充足的证据判断其“无罪”