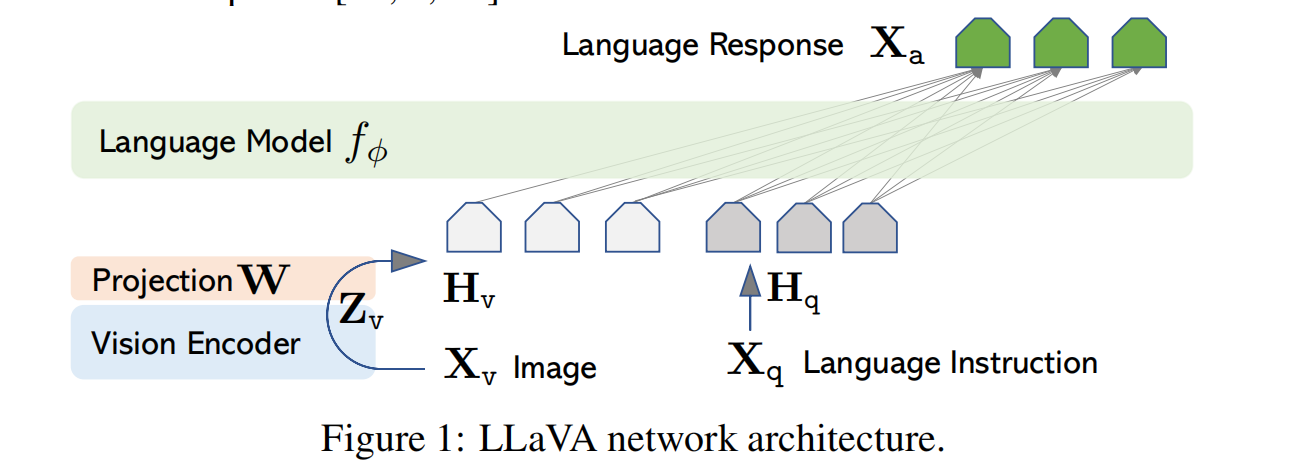
1 Why LLaVa? 现在的大语言模型取得了非凡的成果,比如GPT、LLaMA等,然后他们还都在machine-generated high-quality instruction-following data训练,提升模型的的对齐和指令跟随能力。但是他们都是text-only。 作者提出的LLaVa,是第一个把instruction tuni…
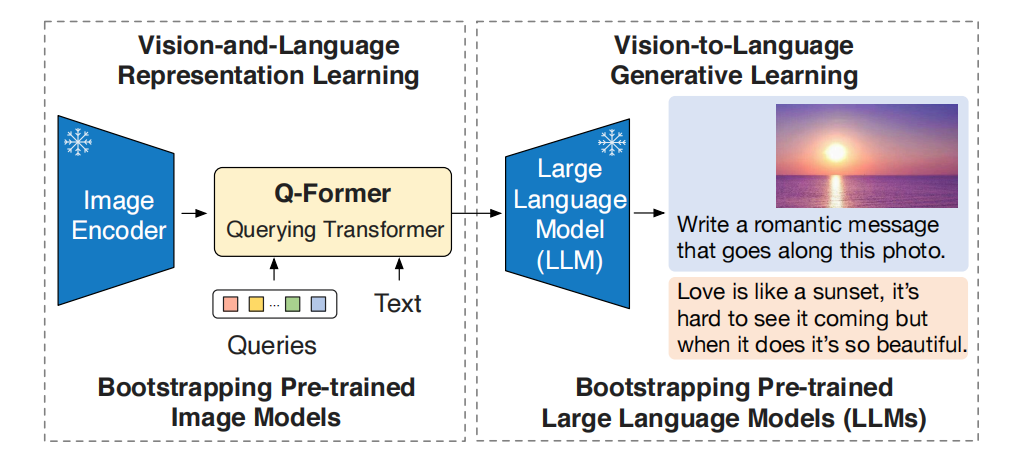
1 Why BLIP2? 如果VLMs能现有的最先进的单模态模型中获取知识,那样可以极大的提高VLMs的能力。因此作者提出了BLIP2,从off-the-shelf(现有的)的视觉或者语言模型中训练VLMs。视觉模型提供高质量视觉表征,语言模型,或者大语言模型,提供强的语言生成和zero-shot transfer。然后训练一个Querying T…
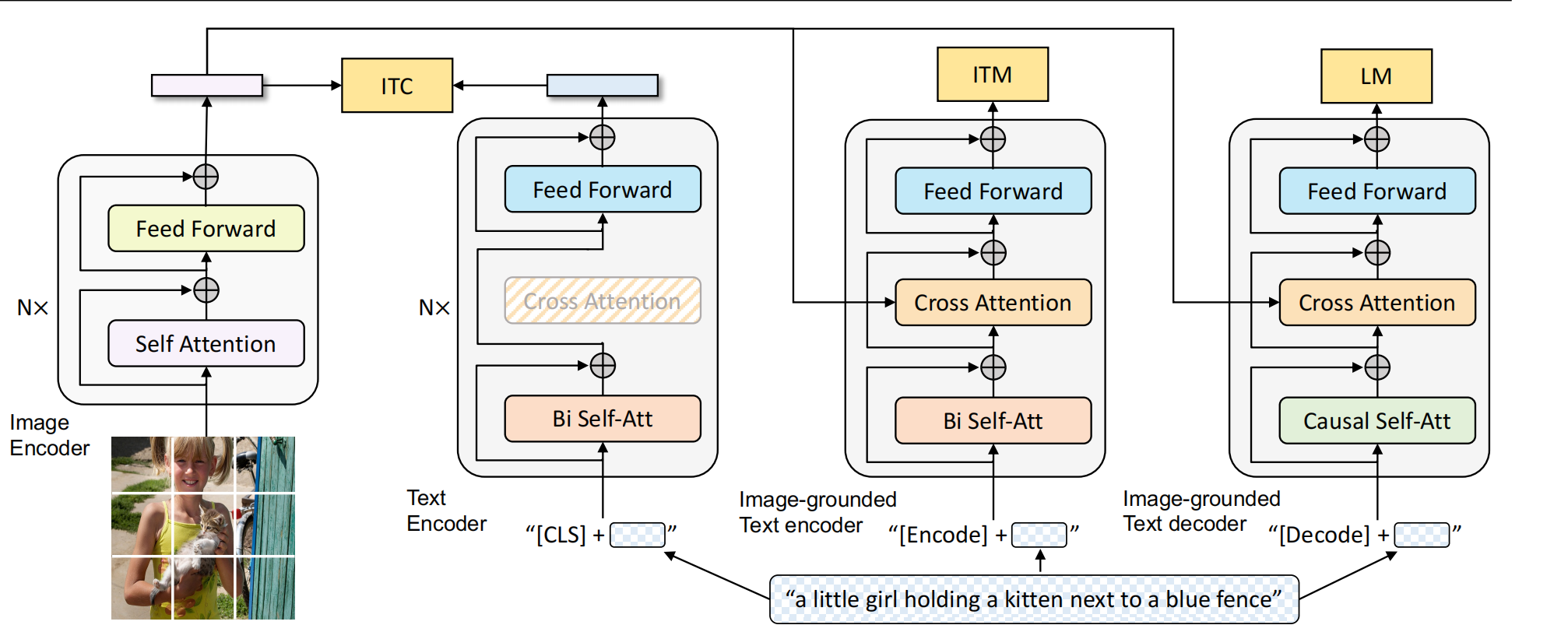
1 Why BLIP? 现在的预训练模型要么在理解任务表现出色,要么在生成任务任务上表现出色,还没有统一这两个任务的模型。现在encoder-based模型,比如clip,不太能迁移到生成任务,然而encoder-decoder的模型不太能迁移到图文检索的任务。 现在的预训练模型都通过扩大数据集来实现好的性能,这些数据集上包含许多充满噪声的图文对。…
1 什么是RAG 1.1 初识RAG RAG(Retrieval Augmented Generation)为生成式模型提供了与外部世界互动的很有前景的解决方案 RAG主要作用类似于搜索引擎,找到和用户提问最相关的知识或者对话历史,结合原始提问(查询),创造信息丰富的prompt,指导模型生成准确输出。 本质上是In-Context learnin…
1 什么是大模型幻觉? 大模型不遵循原文(一致性,Faithfulness,是否遵循input content)或者不符合事实(事实性,Factualness,是否遵循世界知识),可以认为模型产生了幻觉问题 传统任务里,幻觉大多都是一致性问题,即LMs在生成回复的时候和输入信息产生了冲突,比如信息冲突、无中生有 在LLMs里,幻觉大多是Factua…
1. 什么是大语言模型? 大模型:一般指1亿参数以上的模型,大语言模型(LLMs)是针对语言的大模型 大模型有以下特点: 大规模参数 多任务处理能力:其在多种语言任务上有很好的性能。比如说文本摘要、情感分析、机器翻译等,因其已经在大规模数据集上学习到了语言模式和规律。 上下文推理:LLMs可以根据上下文生成有逻辑和连贯的回应,可以对话或者创作。可以…
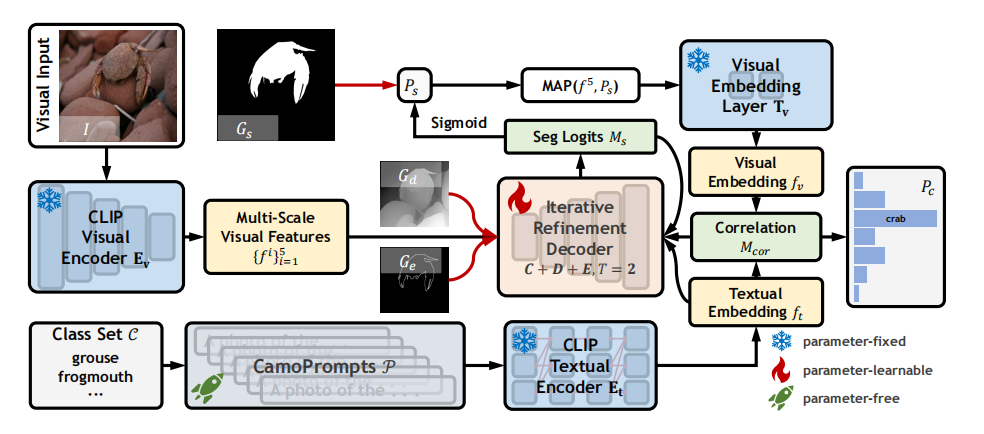
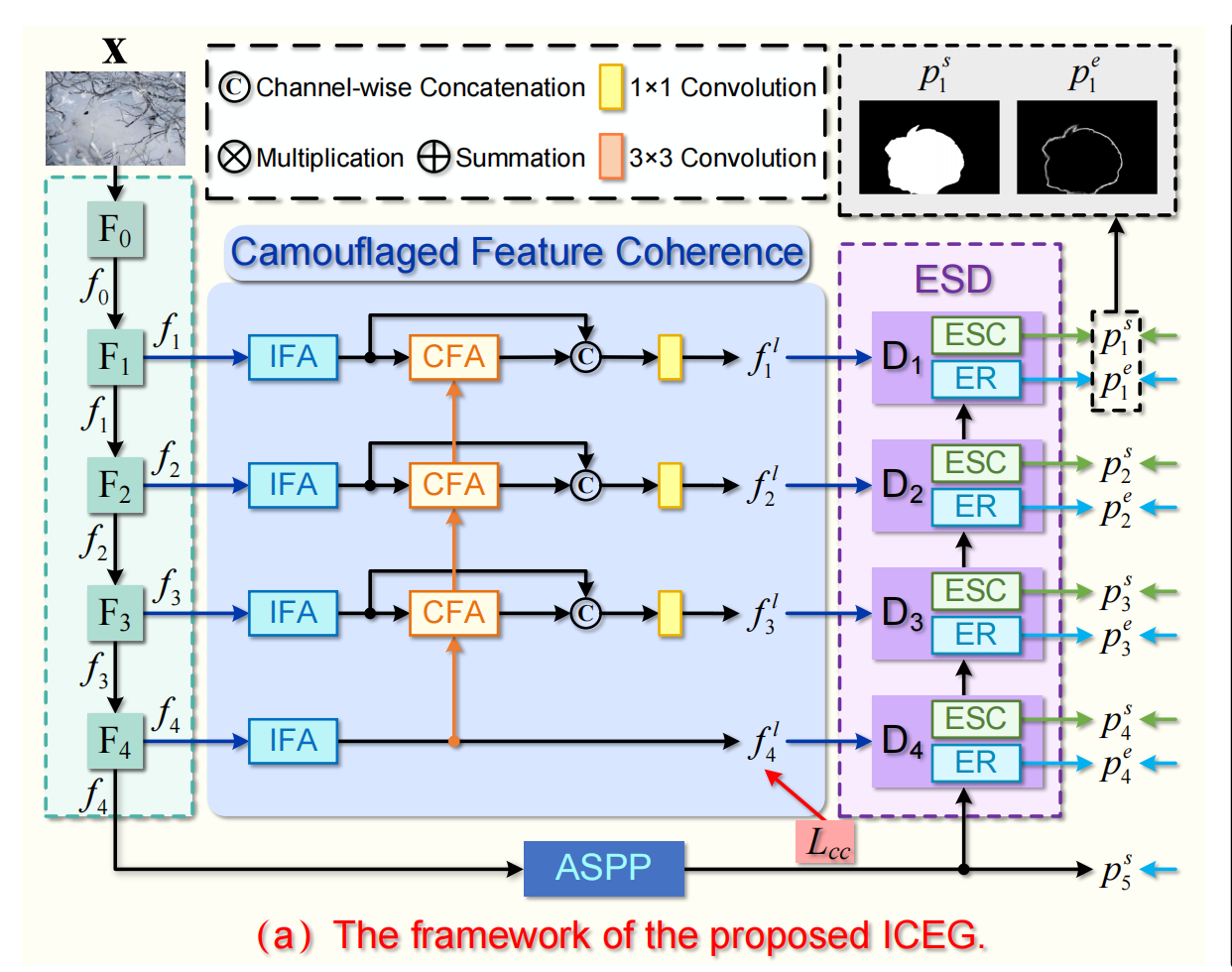
论文链接:Open-Vocabulary Camouflaged Object Segmentation 1 introduction 现在的伪装目标检测主要集中在预定义的封闭集场景上,其中所有的语义概念都在推理和训练阶段被看到,但是这过度简化了真实世界的复杂性,因此,作者提出了一个新的方向,开放词汇环境下的伪装目标检测,Open-Vocabula…
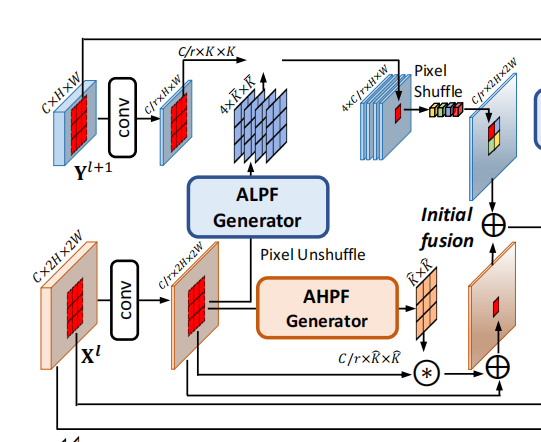
论文地址:Frequency-aware Feature Fusion for Dense Image Prediction 1 introduction 先说论文中几个名词: intra-category & inter-category similarity:会计算给定图片每个类的一个category center,就是某个类所有fea…
论文链接:Strategic Preys Make Acute Predators: Enhancing Camouflaged Object Detectors by Generating Camouflaged Objects 1 Introduction 本文以捕食者和被捕食者相互竞争的角度去提升COD任务的检测效果。首先在被捕食者方,使用了…
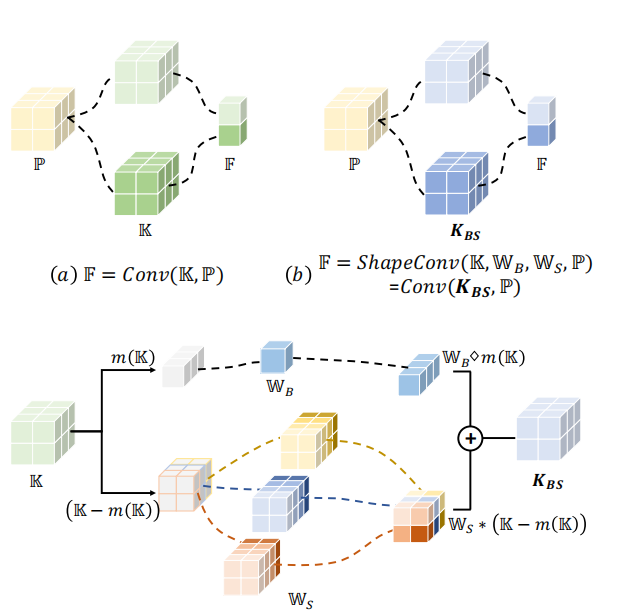
论文链接:ShapeConv: Shape-aware Convolutional Layer for Indoor RGB-D Semantic Segmentation 1 Why ShapeConv for RGB-D tasks 深度图包含物体的基础形状(局部信息,local geometry)和物体的位置(全局信息,在更大的contex…