1 SegFormer
SegFormer两个特点:
- 和其他基于transformer的分割模型不一样,Segformer是一种分层结构,能够输出多尺度的特征,并且不需要位置编码。
- SegFormer不需要复杂的编码器,直接使用MLP来聚合多尺度的特征。
架构图:
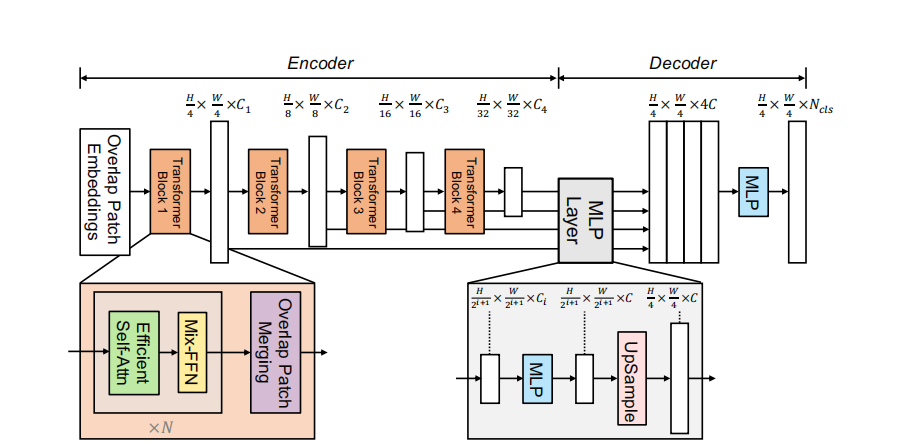
SegFormer会把图像分割成4×4的patch,用比较小的patch会对密集型预测任务比较友好。
Overlapped Patch Merging
在patchify的时候,有一个特色,在ViT里,是把大小为\(N\times N\times3\)(N为patch的大小)patch转换为\(1\times1\times C\)。同样SegFormer为了实现这种多层级的特征,也可以按照这样的操作,把\(2\times2\times C_i\)和为\(1\times1\times C_{i+1}\)。但是这样的方法破坏了patch之间的连续性,因此作者使用overlapped patch merging的方式进行patch之间的融合,具体来说作者采用\(K=7,S=4,P=3\)(K为patchsize,S为步长,P为padding),通过这样的设置,可以生成和nonoverlapping一样大小的特征。
Efficient Self-Attention
将key的数量削减,对于序列\(K\),维度为\(N\times C\),首先做一个reshape,调整为\(\frac{N}{R}\times({C\cdot R})\),然后经过一个linear,调整为\(\frac{N}{R}\times C\),保持query的数量不变,这样计算复杂度变为\(O(\frac{N^{2}}{R}).\)
Mix_FFN
ViT会用位置编码来编码不同位置的patch,但是如果对于别的分辨率的图片,使用位置编码会导致性能退化。作者认为PE是没用的。作者使用的是zero padding,然后在FFN里使用Conv,从来获取位置信息。
\[\mathbf{x}_{out}=\mathrm{MLP}(\mathrm{GELU}(\mathrm{Conv}_{3\times3}(\mathrm{MLP}(\mathbf{x}_{in}))))+\mathbf{x}_{in},\]
Lightweight All-MLP Decoder
把计算之后的每个多级特征,都经过一个MLP,投影为通道\(C\),然后上采样至尺寸为\(\frac{W}{4}\times\frac{W}{4}\),然后将得到的4个特征Concat,然后投影至通道数为\(C\),在经过MLP,投影到通道数为\(N_{cls}\).
2 SETR
创新点:
传统的分割模型都是类似于FCN一样的Encoder-Decoder架构,在Encoder阶段,都是像金字塔一样逐层削减空间分辨率(可以控制计算量、扩大单个像素感受野),作者把分割任务转换成一个sequence to sequence的任务,在encoder结构中,并没有对空间分辨率逐层下采样。
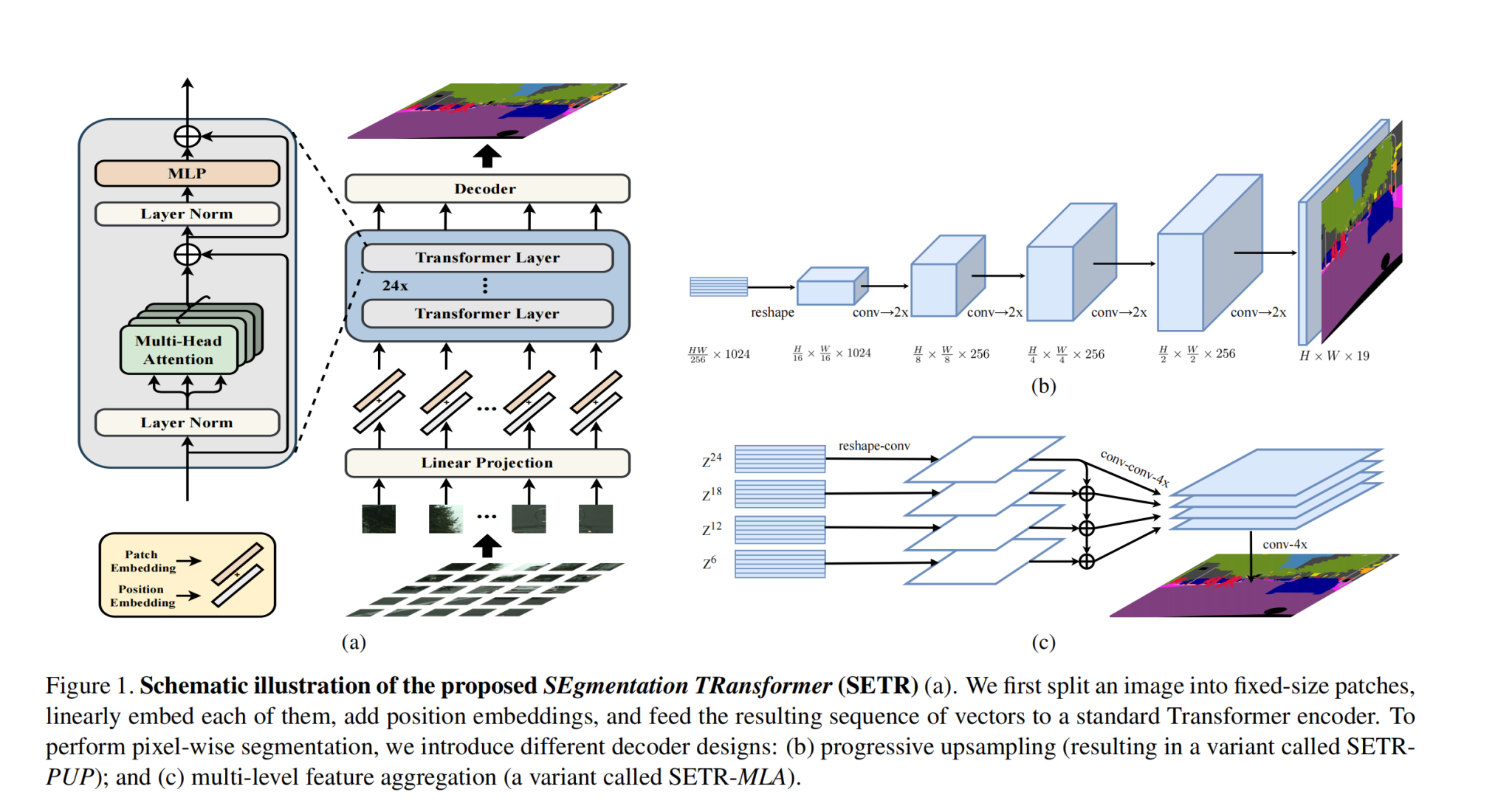
Methods:
- Encoder:H✖️W✖️C的图片变为H/16✖️W/16✖️C,从而序列化为(HW/256)✖️C的二维矩阵,然后送进Transformer,期间保持空间分辨率不变
- Decoder:
- Naive Upsampling:把(HW/256)✖️C向量,先投影到和分类类别一致(比如CityScapes就投影到19),然后通过通过conv+ReLU+conv,然后最后直接upsample到和原图大小一致
- Progressive Upsampling:刚刚那种方法,直接upsample太粗糙了,这次是采用每次上采样2x,共上采样四次。
- Multi-level Feature Aggregation:Encoder有4个Stage,每个stage都有一个输出,对于每一个stage:都先经过1×1,3×3,3×3的conv(第一个和第三个conv会减半通道),然后上采样4倍。最后,从上至下逐元素相加,在最后一层得到最后结果,然后继续上采样4x
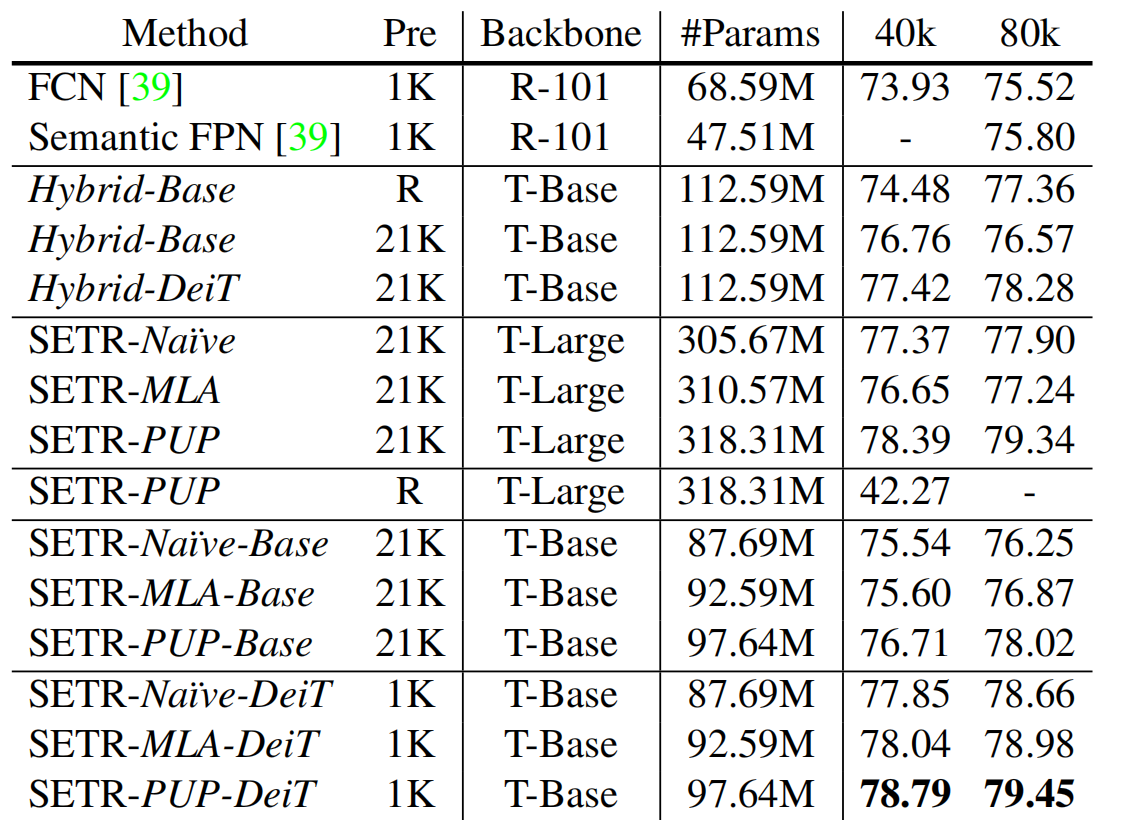
MaskFormer
之前的语义分割模型都是逐像素分类,对每一个像素都施加一个loss。但是在实例分割上,由于逐像素分割的类别是固定的,所以对于实例分割任务,具有架构上的隔离。在maskformer之前,做实例分割的Mask RCNN,其实是一种检测模型,它是经过检测之后,生成“thing”类别的检测框,送进mask head去生成0-1mask,因此这种方式做不了语义分割,因为语义分割还要求分类出背景(Stuff类别),而且mask rcnn是双阶段的的
maskformer就是一个能统一语义、实例、全景分割的模型,并且是端到端的。
Mask Classification
类似于DETR,使用N个(远多于GT数量)query,产生N个prediction,然后和GT使用匈牙利算法寻找最优偶匹配,让下列匹配损失最小的就是最优匹配:
\[-p_i(c_j^{\mathrm{gt}})+\mathcal{L}_\mathrm{mask}(m_i,m_j^{\mathrm{gt}})\]
找到最优匹配\(\sigma\)之后,对于这个最优匹配计算损失,然后反向传播
\[\mathcal{L}_{\mathrm{mask-cls}}(z,z^{\mathrm{gt}})=\sum_{j=1}^N\left[-\log p_{\sigma(j)}(c_j^{\mathrm{gt}})+1_{c_j^{\mathrm{gt}}\neq\varnothing}\mathcal{L}_{\mathrm{mask}}(m_{\sigma(j)},m_j^{\mathrm{gt}})\right].\]
MaskFormer
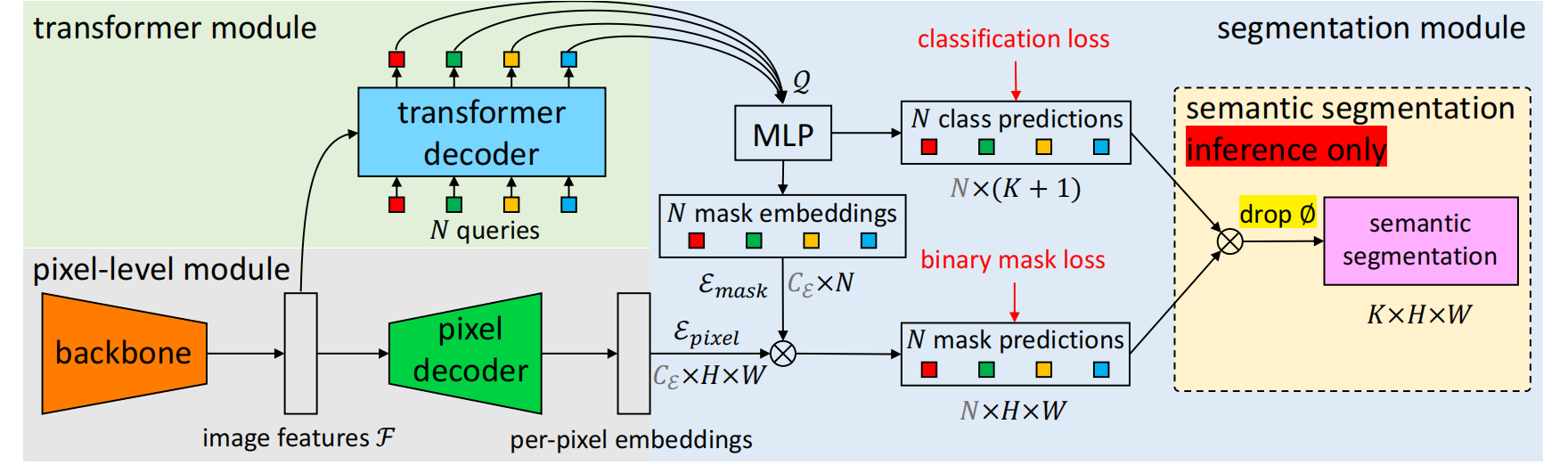
Pixel-Level Module
先经过backbone(ResNet/Swin-Transformer),编码为\(\mathcal{F}\in\mathbb{R}^{C_{\mathcal{F}}\times\frac{H}{S}\times\frac{W}{S}}\),然后经过一个pixel decoder,这里是一个FPN结构,逐层上采样为\(\mathcal{E}_{\mathrm{pixel}}\in\mathbb{R}^{C\varepsilon\times{H\times W}}\)的per-pixel embedding,值得注意的是,所有基于像素分类的分割模型都符合像素级模块设计,包括近期基于Transformer的模型。MaskFormer可无缝将此类模型转换为掩码分类模型。
Transformer Module
使用N个learnable posional embedding作为query,使用类似于DETR Decoder的结构,解码出N个per-segment embedding,里面内含maskformer预测的每个segment的全局信息、语义信息。
Segmentation Module
K个类别,K+1个类别是多了一个“无物体”类别,因为预测的query数量要大于图片中真实物体的数量。
首先,per-segment-embedding经过一个mlp,会输出N个K+1维度的向量,表示各个segment的预测class的类别概率分布,同时,per-segment embedding也会经过一个mlp,这个会输出\({\mathcal{E}_\mathrm{mask}}\in\mathbb{R}^{C_{\mathcal{E}}\times N}\),因为要做分割任务,所以要结合丰富细节信息的pixel-level module输出的per-pixel embedding相乘,\(m_i[h,w]=\operatorname{sigmoid}(\mathcal{E}_\mathrm{mask}{[:,i]^\mathrm{T}}\cdot\mathcal{E}_\mathrm{pixel}{[:,h,w]}).\),产生N个mask。这样一来,mask的产生和分类是分开进行的,区别于传统的per pixel model
DETR
模型结构
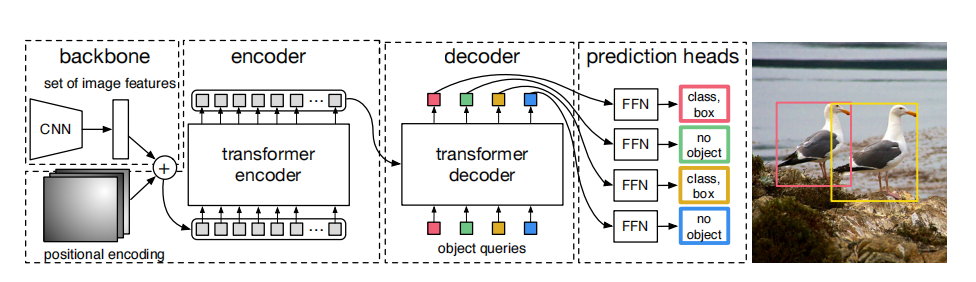
- Backbone:输出一个2048×H0/32×W0/32大小的特征图
- Encoder:首先把C=2048投影到d,H=H0/32,W=W0/32,得到(H×W)×d的矩阵,送到标准encoder里
- Decoder:区别于普通的标准transformer,DETR的decoder是并行解码N个query,并且这几个query是一个可学习的参数,并且无需加入位置编码
Loss
首先使用匈牙利算法找到pred和gt之间的最优偶匹配
\[\hat{\sigma}=\arg\min_{\sigma\in\mathfrak{S}_N}\sum_i^N\mathcal{L}_{\mathrm{match}}(y_i,\hat{y}_{\sigma(i)}),\]
\(\hat{\sigma}\)是找到的最优匹配,就是一个最优映射,让上述式子最小,对于第i个gt的框,其在所有预测框中,匹配最优的是第\(\hat{\sigma}(i)\)个预测框。\(\mathcal{L}_{\mathrm{match}}(y_i,\hat{y}_{\sigma(i)})\)的计算公式是:
\[\mathcal{L}_{\mathrm{match}}(y_i,\hat{y}_{\sigma(i)})=-\mathbb{1}_{\{c_{i}\neq\varnothing\}}\hat{p}_{\sigma(i)}(c_{i})+\mathbb{1}_{\{c_{i}\neq\varnothing\}}\mathcal{L}_{\mathrm{box}}(b_{i},\hat{b}_{\sigma(i)})\]
\({\hat{p}}_{\sigma(i)}(c_{i})\)就是对于第i个gt框,其第\(\sigma(i)\)个预测框是类别\(c_{i}\)的概率,\(c_{i}\)是GT。
匈牙利损失
我们在找到最优映射\(\hat{\sigma}\)之后,可以计算匈牙利损失,让一一匹配上的框的位置、和预测类别损失最小
\[\mathcal{L}_{\mathrm{Hungarian}}(y,\hat{y})=\sum_{i=1}^{N}\left[-\log\hat{p}_{\hat{\sigma}(i)}(c_{i})+\mathbb{1}_{\{c_{i}\neq\emptyset\}}\mathcal{L}_{\mathrm{box}}(b_{i},\hat{b}_{\hat{\sigma}}(i))\right]\]
其中Bounding Box的Loss为L1 loss和IoU Loss加权平均,防止仅仅使用l1 loss在小尺寸框和大尺寸框上的loss的scale不一致
\[\lambda_{\mathrm{iou}}\mathcal{L}_{\mathrm{iou}}(b_{i},\hat{b}_{\sigma(i)})+\lambda_{\mathrm{L}1}||b_{i}-\hat{b}_{\sigma(i)}||_{1}\]
Overall Loss
最终整体的loss由两部分组成,一部分是之前的匈牙利损失,也就是匹配上的目标损失,但是object query往往远大于真是目标数量,所以会有很多没匹配上的,因此需要让这些没匹配上的框,让其类别和“无目标”这一类别趋近,如果没有这一限制,没有机制鼓励模型把“不存在目标的位置”预测为背景,模型可能会输出一堆“低置信度但非背景”的预测,导致误检。
\[\mathcal{L}_{\mathrm{DETR}}\left(y,\hat{y}\right)=\underbrace{\sum_{i=1}^{N}\left[-\log\hat{p}_{\sigma(i)}\left(c_{i}\right)+\mathbf{1}_{\{c_{i}\neq\mathbb{Z}\}}\mathcal{L}_{\mathrm{box}}\left(b_{i},\hat{b}_{\sigma(i)}\right)\right]}_{\text{匹配目标损失}}+\underbrace{\lambda_{\mathrm{noobj}}\sum_{j\not\in\mathrm{matched}}\left(-\log\hat{p}_{j}\left(\varnothing\right)\right)}_{\text{未匹配预测根的背景损失}}\]
DAB-DETR
DETR有两个问题,query含义并不清楚,不可解释,二是模型收敛慢。本来这应该是两个独立问题,不过后来我们发现,DETR收敛慢很大程度上来自于query含义的不明。
在原始的DETR文章中的object query画的比较简单,可能会让人觉得query就是一组向量:
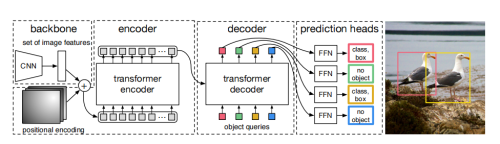
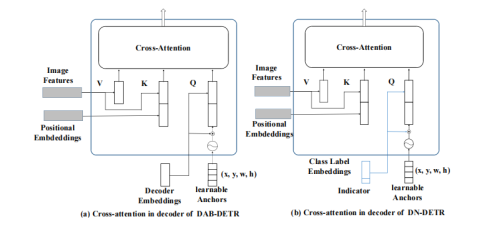
但是实际上是由两组向量组成,我们称之为content query和positional query(这两个名字由conditional detr提出。)这里画出来了encoder和decoder中的attention的组成部分。
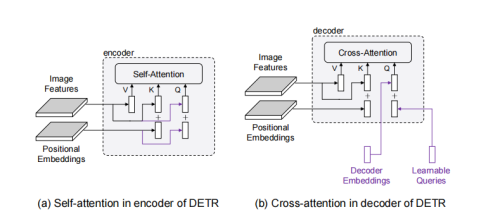
可以看到,encoder和decoder里attention和query和key都是由两部分组成的,比如encoder里的query分别来自于图像特征(包含语义信息)和位置编码(包含位置信息),因此这两部分分别称为content query(对应图像特征)和positional query(对应位置编码)。key和query完全相同。value只有图像特征这一语义部分。
再看decoder,decoder的key和value与encoder的组成完全相同,但是query则不同。query的语义部分来自于decoder embeddings,对应上层的输入,是由图像特征组合来的。而位置部分则来自于learnable queries,这是与我们看DETR的框架图后的第一反应不同的。因此decoder的learnable query实际指代的是位置信息。
但是DETR里的object query根本就没有先验知识,模型要学出来object query里的位置信息,需要很大的训练量,并且可能收敛不到最优解,因此DAB-DETR显示的将object query用anchor boxes的信息表示。
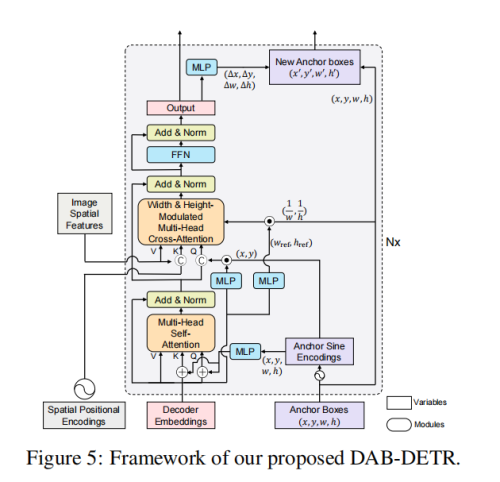
- 在self attn里,xywh通过正弦编码,正弦编码会输出D/2维向量,因此xywh concat之后会产生2D向量,然后通过MLP将其投影回D维,和Decoder Embedding相加
- 在cross attn里,Q来自于xy的正弦编码和content query的乘积,作者说使用content query可以“rescale the positional embeddings”
- 每一个layer的输出,会产生xywh的四个偏移量,用于更新xywh,从而一层层的refine
DN-DETR
在DAB-DETR的基础上实现DN-DETR,因为DAB-DETR是DN之前最强的模型之一,而且它显示的把decoder query表示为四维坐标很适合添加denoising training。
沿着Conditional DETR,之后的工作如DAB-DETR都把decoder query设计成了content query和position query。为了更大限度利用denoising training,我们把content query输入为label embedding,对label也添加噪声进行reconstruct。因为denoising只是一种training方式,不会改变模型结构,只是在输入的时候做了一些改变,如下图所示,我们把decoder embedding(content query)表示为加了noise的label, anchor(position query)表示为加了noise的bbox。对于DETR原始的匹配部分,我们可以添加一个 [Unknown] label来进行区分,anchor部分保持DETR的方式不变
denoising
- Label Denoising:我们以一定概率随机把真实label翻转为其余的任何一个label。如COCO中有80个类别,我们以一定概率将其翻转为80个中的其他label。加入label的方法类似NLP中的word embedding,把80个类别进行embedding即可。
- box noise:box的noise可以分为两类,即中心点漂移(center shifting)和框缩放(box scaling)。对于中心点漂移,我们可以保证中心点仍然在真实框内部并进行漂移。对于框缩放,可以随机缩放框的长和宽。漂移的强度和缩放的大小控制都由超参数进行控制。
- attention mask:除了加noise之外,在decoder的self attention我们需要加一个额外的attention mask防止信息泄露。因为denoising部分包含真实框和真实标签的信息,直接让matching part看到denoising part会导致信息泄漏。因此,训练的时候matching part不能看到denoising part,像原始模型一样训练。额外增加的denoising part看或者不看到matching part对结果影响不大,因为denosing部分含有最多的真实框和标签。
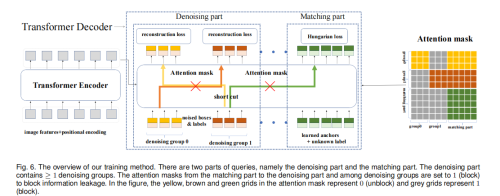
这样一来,query就由两部分明确含义的组成,一部分是class,一部分是bbox
DINO
DINO融合了DAB-DETR和DN-DETR,
- DAB让我们意识到query的重要性,那么如何学到更好的或者初始化更好的query?
- DN引入了去噪训练来稳定标签分配,如何进一步优化标签分配?
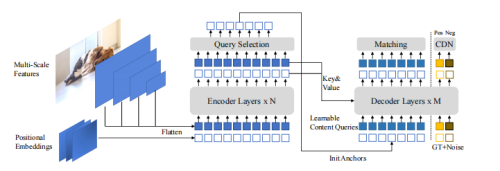
为了解决上面提到的问题,DINO进一步提出了3个改进来进行优化,模型架构如上图所示。
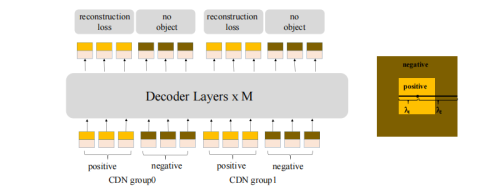
Contrastive Denoising
DN的去噪训练里面引入的噪声样本都是正样本来进行学习,然而模型不仅需要学习到如何回归出正样本,还需要意识到如何区分负样本。例如,DINO的decoder中用了900个query,而一张图中一般只会有几个物体,因此绝大部分都负样本。
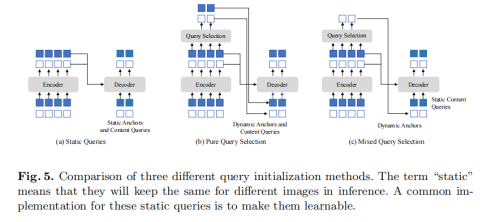
Mixed Query Selection
然而,这种方式并没有在后来的工作中得到广泛运用,我们对这种方式进行了一些改进并重新强调其重要性。在query中,我们实际更关心position query,也就是框。同时,从encoder feature中选取的feature作为content query对于检测来说并不是最好的,因为这些feature都是很粗糙的没有经过优化,可能有歧义性。例如对“人”这个类别,选出的feature可能只包含人的一部分或者人周围的物体,并不准确,因为它是grid feature。
因此,我们对此进行了改进,让position query从encoder feature中初始化得来,保持content query是可学习的。。