论文地址:Spider: A Unified Framework for Context-dependent Concept Segmentation
1 Introduction
首先说一下Context Dependent(CD)和Context Independent(CI)
在自然语言处理中,上下文无关概念是指那些在不同上下文中其含义基本不变的概念或词语。这些概念具有稳定的语义,几乎不受周围单词或句子的影响,比如数学中的公式和定理,如勾股定理,无论在什么上下文中,其意义都是固定的。上下文相关概念是指那些其含义在不同上下文中可能会发生变化的概念或词语。这些概念的解释依赖于周围的词语、句子或段落,比如词语“light”:在某些上下文中可以指“光”,在其他上下文中可以指“轻”或“浅色”。、
在视觉分割中,指的是在不同的语境(context)下,同一个像素可能是不同的类别。比如下图,在Salient的语境下,小提琴为1,其他都为0;在Transparent语境下,没有像素类别是1,因为图中没有透明的物体;在Shadow的语境下,图中的阴影部分为1,其他为0。

目前存在的问题:
- 目前的CD模型都太specialist,孤立的进化导致了其有限的跨域泛化和重复的技术创新。由于在CD任务中,前景和背景环境之间存在着很强的耦合关系,现有的方法需要在其集中的领域中训练单独的模型。这限制了他们对现实世界的CD概念对Artificial Genera Intelligence(AGI)的理解
- 现在的一些AGI依靠一对image-foreground的prompt去理解CI的事物,这就会导致在CD任务上表现很差,因为CD任务中的目标没有固定的语义类,而且多个CD概念经常在语义空间中混合在一起,因此,单一前景的提示并不能为分割模型提供明确的指导,需要多对prompt。比如说,只给一对image-foreground:原图(image)还有一个图中Shadow物体的标注(foreground),让模型去识别一张新图片中的shadow,由于给的prompt实在有限,导致效果很差。
于是,作者根据目前存在的这些问题,提出了一个统一的模型,所有的任务都使用同一套共享的参数,这样就不用为某个领域单独训练一个模型。并且这个模型中,prompts是很多对的,可以为模型提供更多的信息。
2 Approach
2.1 Overall Pipeline

一共有三个流,分割流、image-group prompt流、mask prompt流。分割流就是我们要分割的那个图。根据mask和image这两个流的输出,产生一个weight和一个bias,构成一个filter(卷积),然后把这个卷积用在head上,不同的任务会有不同的weight、bias,产生针对于任务的输出。
下面讲一下weight和bias如何生成以及俩个流的计算方式。
2.2 weight和bias的生成
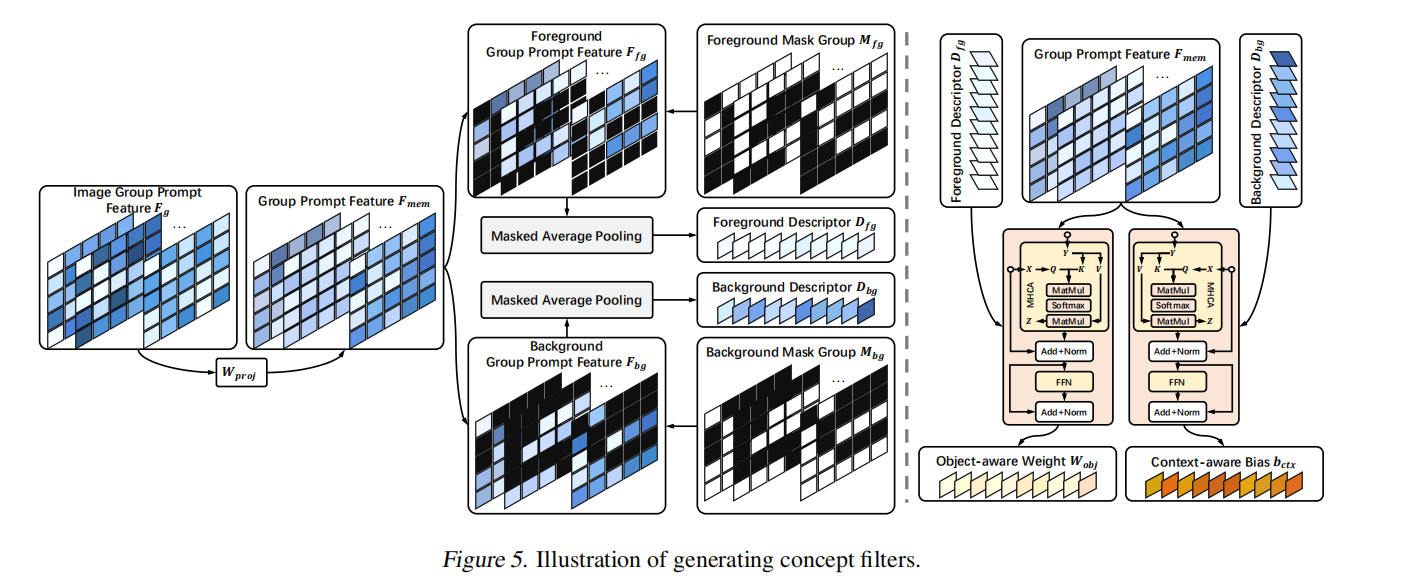
让一系列image经过预训练(frozen)的encoder,得到特征\(F_{g}\),经过proj,得到group prompt feature \(F_{mem}\),然后对它做masked average pooling,mask就是image对应的GT,GT当作mask,产生foreground descriptor,1-GT当作mask,产生background descriptor。这两个descriptor \(D_{fg},D_{bg}\)分别从\(F_{mem}\)提取到整个image group的前景和背景的context。但是这只是一个粗略的,为了精细化一些,从\(F_{mem}\)挖掘和foreground/background有关的cues(因为之前仅仅是孤立的mask,不涉及前景和背景的交互,这样信息肯定是不完善的),作者使用了,multi-head cross attention。 \(D_{fg},D_{bg}\)分别当作\(\text{X}\),会被投影为\(\text{Q}\),\(F_{mem}\)会被当作\(\text{Y}\),mapping到(\text{K}\)和(\text{V}\),计算activation map:
\[M=\text{softmax}(\frac{QK^\top}{d}),\]
\[Z=X+MVW_Z,\\X=Z+\mathrm{FFN}(Z),\]
经过精细化后的\(D_{fg}\)会当作object-aware weight,精细化过后的\(D_{bg}\)会当作context-aware bias。
注意,cross-attention的主角是\(\text{X}\),也就是\(D_{fg},D_{bg}\),而不是\(F_{mem}\),cross-attention的目的是精细化\(D_{fg},D_{bg}\),具体图示见下图:
2.3 image-group在训练和推理时的选取策略
在训练时,在每一次迭代,会从每一种任务中选取G对image-mask pairs,组成group prompts,这种随机选取的方式可以保证concept filter的稳定性,以面对在实际应用中面临不同group prompts的情况。此外,在训练时,作者设计了一种Balance FP – Unify BP的策略,前向传播:为每个task随机选取N个samples,其中B个samples送进分割流,N-B个samples会被用作group prompts,所有task的分割流的samples会被concat,组成\([8B,C,H,W]\)(因为共有8个tasks),同样,所有task的group prompts会被concat,组成\([8(N-B),C,H,W]\)。在最后的预测头,会根据每个task的group prompts产生8个对应于每个task的concept filter,这样就避免了重复的前向传播。使用PPA loss,去同时计算所有samples的loss;反向传播:借助于PPA统计计算所有samples的loss,作者使用这个loss统一地,不针对于某个任务地反向传播更新参数。
在推理时,为了保证稳定性和预测地可复制性(就是针对于每个特定的输入图片,无论通过网络预测多少次,预测结果图都是不变的)。作者为每个任务选取64个具有代表性的examples,作为固定的 group prompts。具体做法是:把每个task数据集所有的图片送进prompt stream的encoder,提取到high-level features,然后分别进行GAP去压缩高级语义特征,然后随机产生64个初始的聚类中心,使用k-means算法进行迭代、更新聚类中心,迭代完成后,选取最终与聚类中心最近的64张图片作为固定的(fixed)image-group prompts