1 数据合成-Selective Tampering Synthesis 共包含copy-move、generation、erase三种篡改方式 提取bounding box内的text mask: 将box扩大到原本的1.5倍,确保box能完全框死整个字符(后续需要进行形态学操作和根据轮廓填充mask,如果不能完全框死,会导致效果不好) 对box…
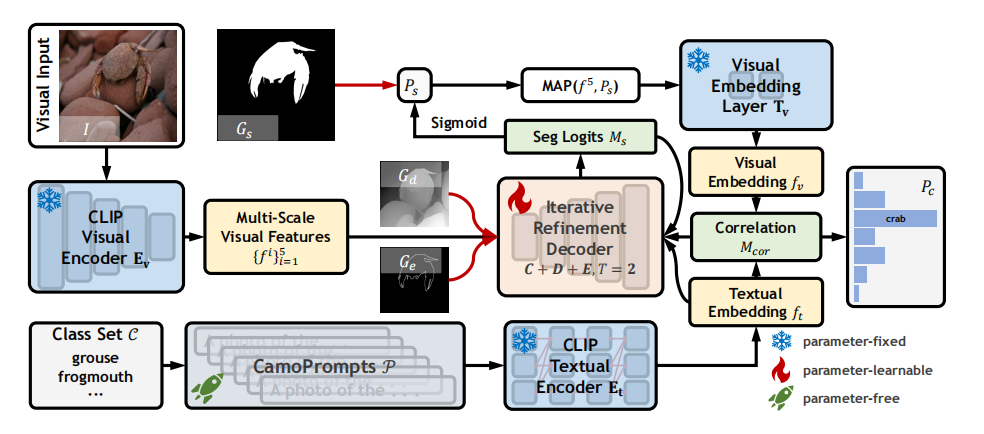
论文链接:Open-Vocabulary Camouflaged Object Segmentation 1 introduction 现在的伪装目标检测主要集中在预定义的封闭集场景上,其中所有的语义概念都在推理和训练阶段被看到,但是这过度简化了真实世界的复杂性,因此,作者提出了一个新的方向,开放词汇环境下的伪装目标检测,Open-Vocabula…

论文地址:Spider: A Unified Framework for Context-dependent Concept Segmentation 1 Introduction 首先说一下Context Dependent(CD)和Context Independent(CI) 在自然语言处理中,上下文无关概念是指那些在不同上下文中其含义基本不…
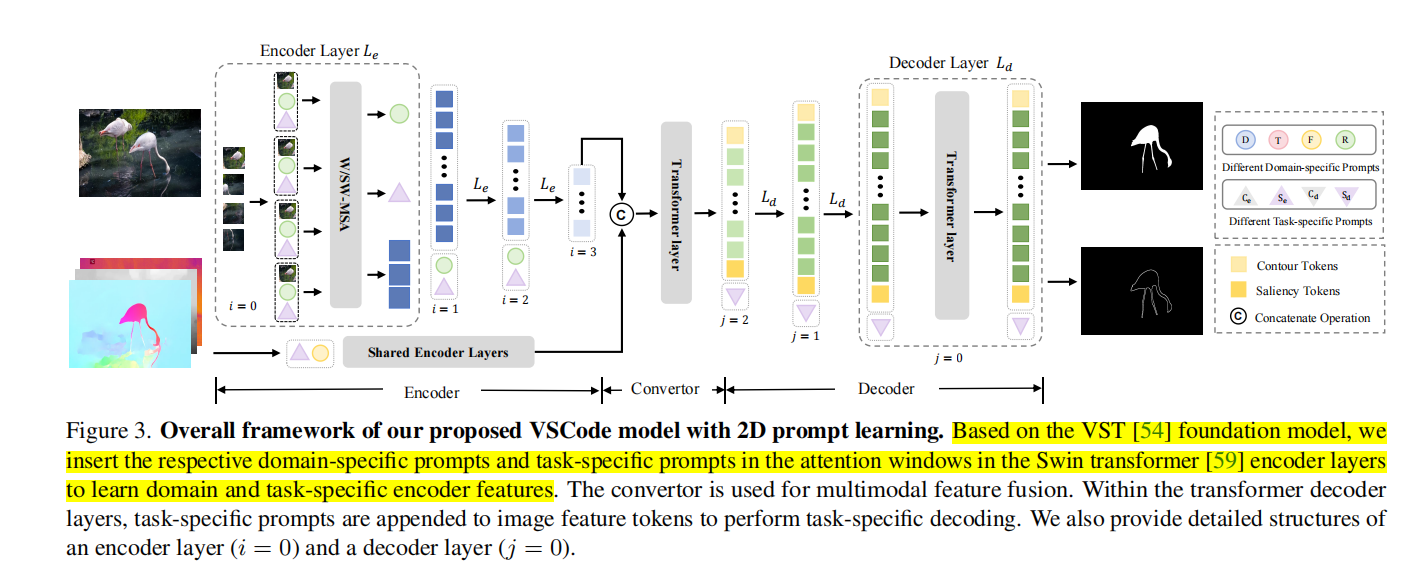
1 Introduction 现在的SOD和COD方法,都是为特定任务训练的模型,比如说深度图、热力图等,这个模型只适用于某种特定的数据集,这种方式不利与泛化,这个模型只能处理单一模式的数据,如果给别的类型的数据,则无法处理。并且,作者发现,不同的任务、不同模态的数据会共享一些相同点,并且有一些独特的线索,只要把这些共同点和独特的线索表示出来,就可…
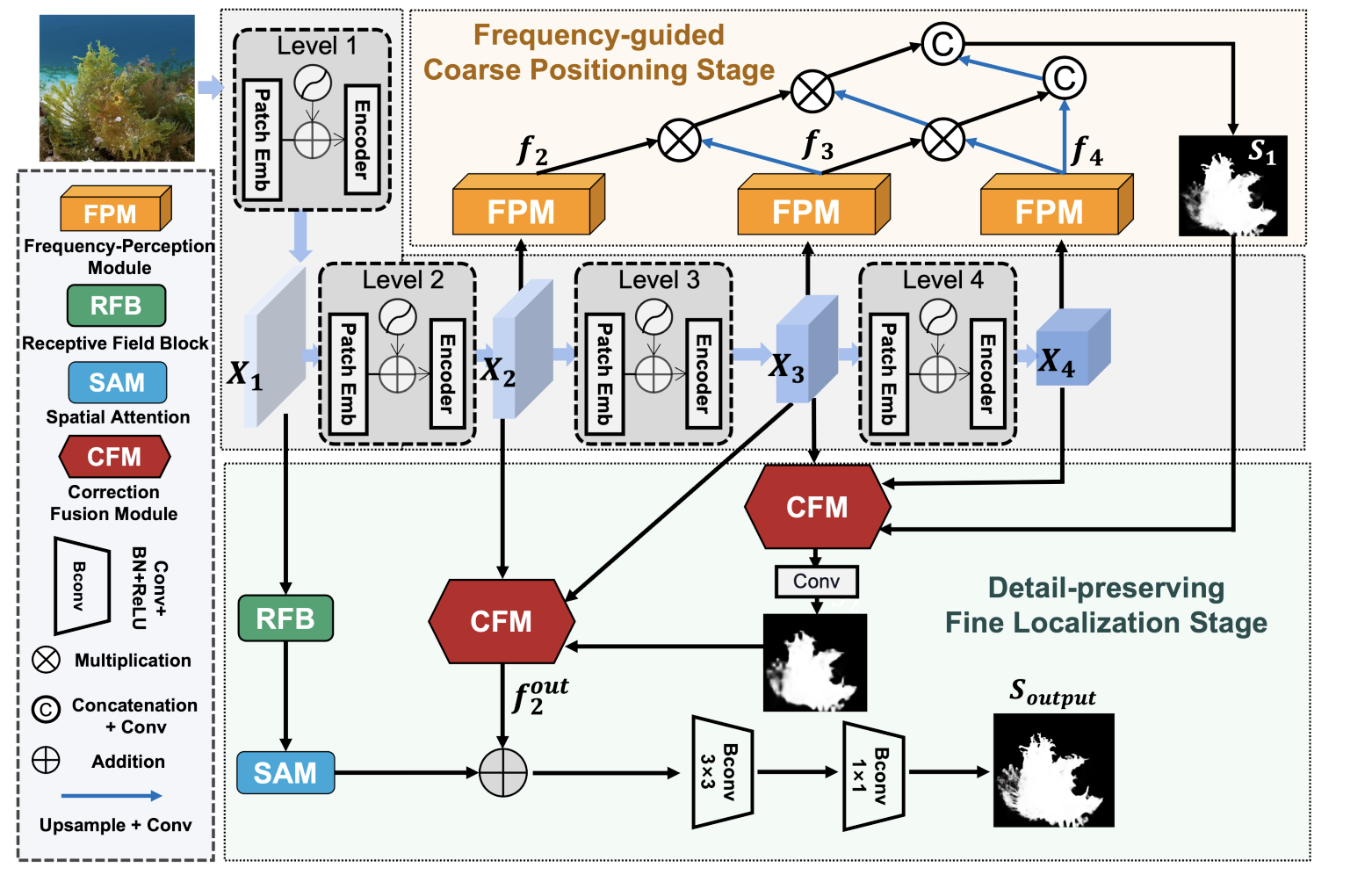
论文地址:Frequency Perception Network for Camouflaged Object Detection 1 Introduction 现在的方法大多在RGB域内进行伪装目标识别,通过纹理不一致性来初步发现伪装目标。在图像频率域里,高频通常描绘图片的细节,低频通常描绘图片的轮廓特征。作者在文章中提出了两阶段识别网络——F…
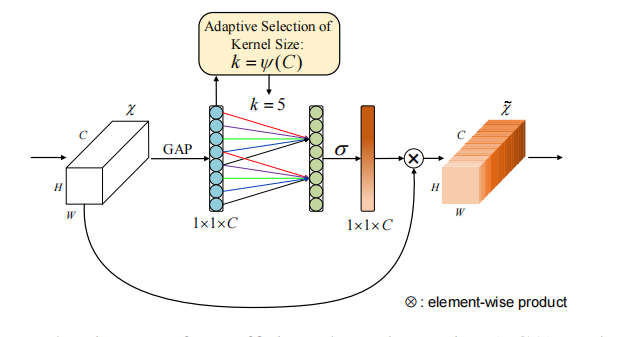
论文地址:ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks 1 Background ECA-Net是SENet的改进,SENet在计算C个通道的attention score的时候,使用的是单隐藏层的MLP: C->C/r->C,作者…
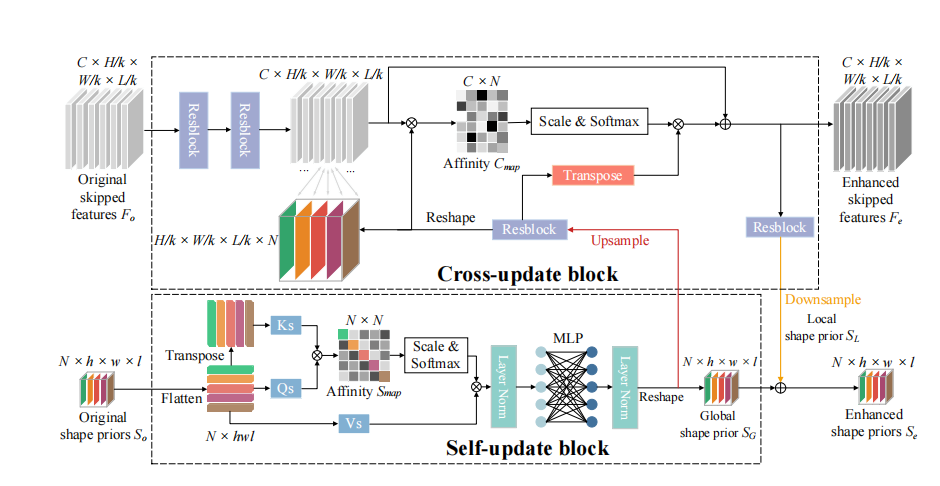
论文地址:Learning with Explicit Shape Priors for Medical Image Segmentation 1 Introduction 在医学图像中,不同的器官或病灶通常具有特定的形状和结构,这些形状和结构信息对于分割模型来说非常关键,因此先前的许多工作尝试利用形状先验来设计分割模型,以获得具有解剖形状信息的更…
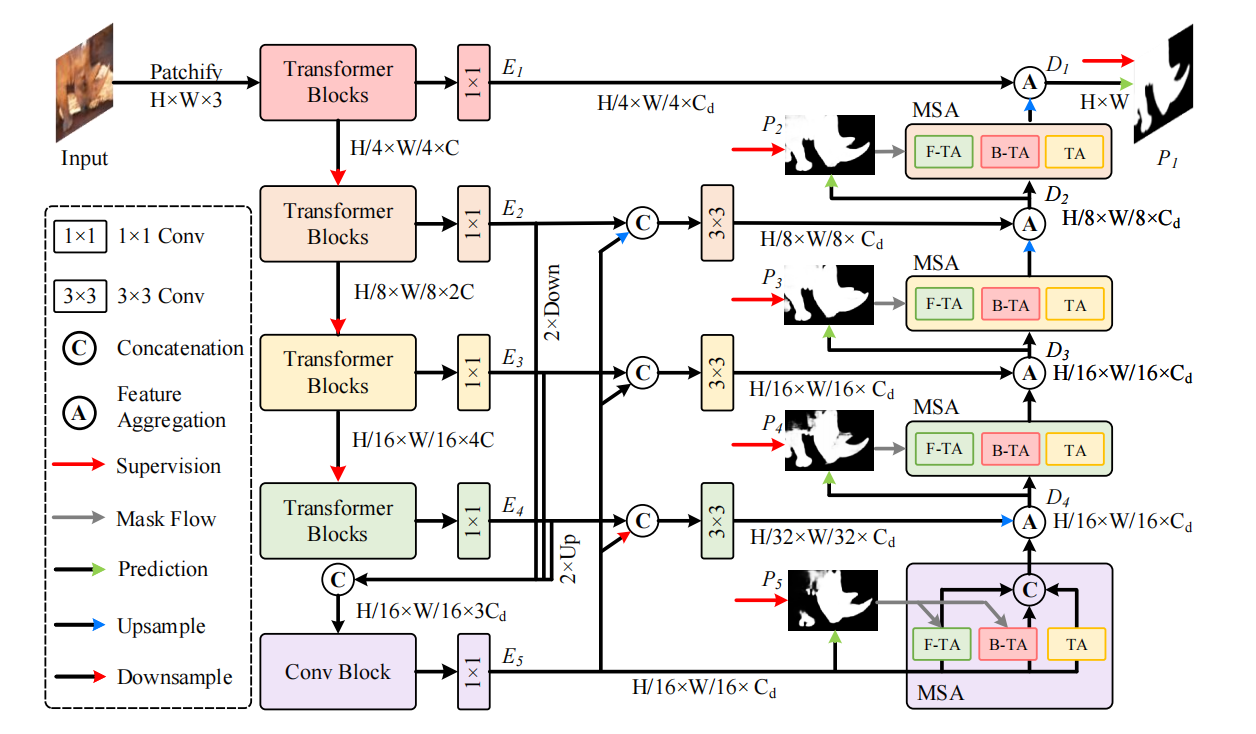
论文地址:CamoFormer: Masked Separable Attention for Camouflaged Object Detection 1 研究动机 现在的伪装目标识别的模型都没有把前景和背景分开处理,这就很难从相似的环境中识别出伪装目标,现在的目标,关键就是分别encode前景和背景。受到Masked Multi-Head At…
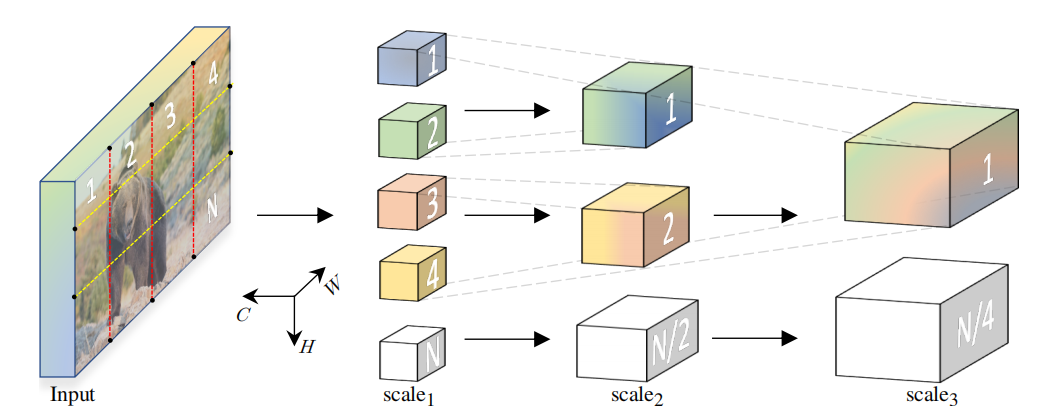
论文地址:Multiscale Vision Transformer CVPR2021 1 introduction 在视觉领域,特征金字塔结构是一种常用的结构,即随着网络的加深,特征图的分辨率越来越小,但是特征图的深度,即channel数,越来越多。高空间分辨率的特征图具有low-level的细节信息,低分辨率的深层特征图具有high-leve…
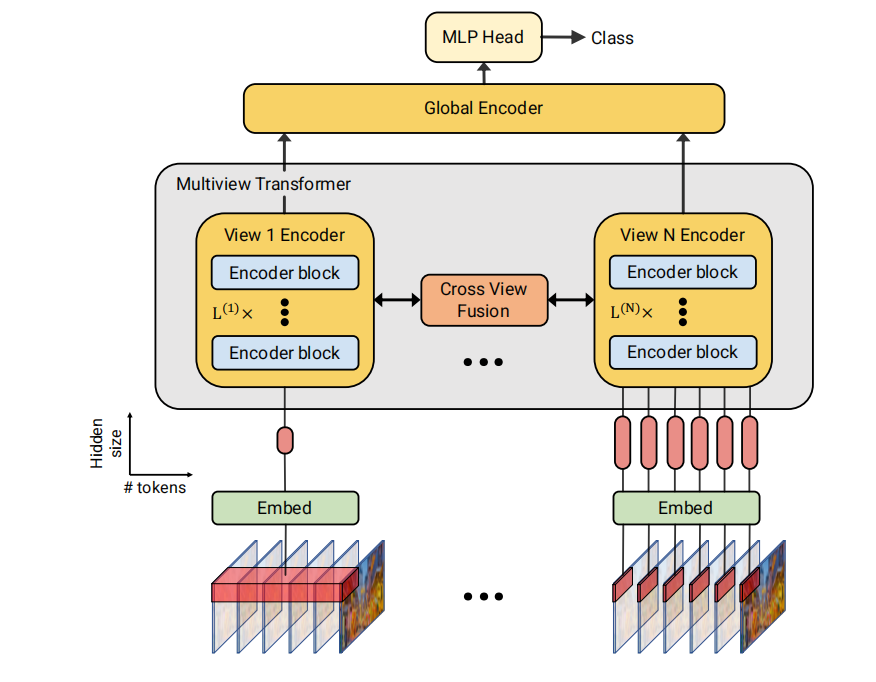
论文地址:Multiview Transformers for Video Recognition CVPR2022 文章是基于ViViT进行改造的 1 研究背景 在图像领域,多尺度处理通过金字塔结构实现。为了视频中的时间多尺度,以前SlowFast是有了2个分支。但是使用一个金字塔结构时,时间空间信息会因为下采样会有一部分信息的丢失。比如Slo…