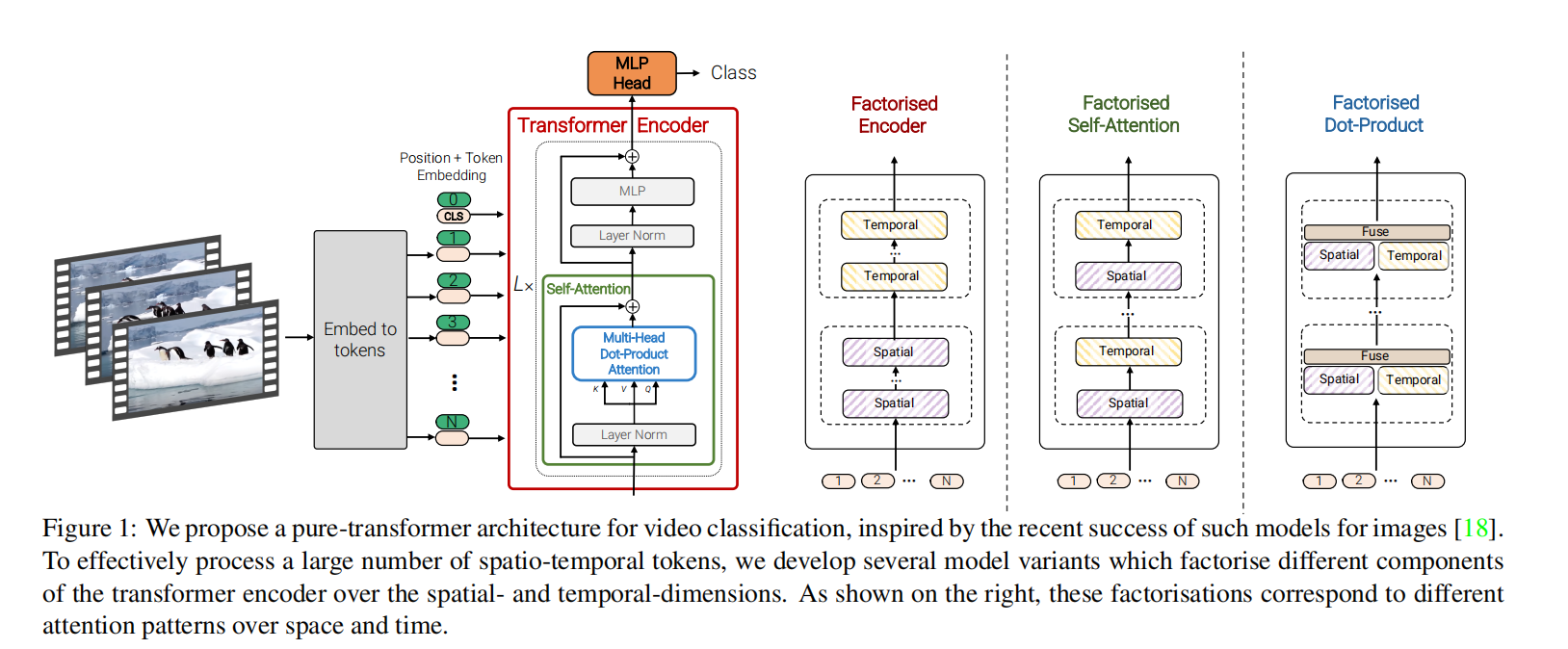
论文地址:ViViT: A Video Vision Transformer 0 divided attention divided attention是ViViT的先验知识,它在Is Space-Time Attention All You Need for Video Understanding?这篇文章中提出,我们知道,视频区别于图片,除了空…
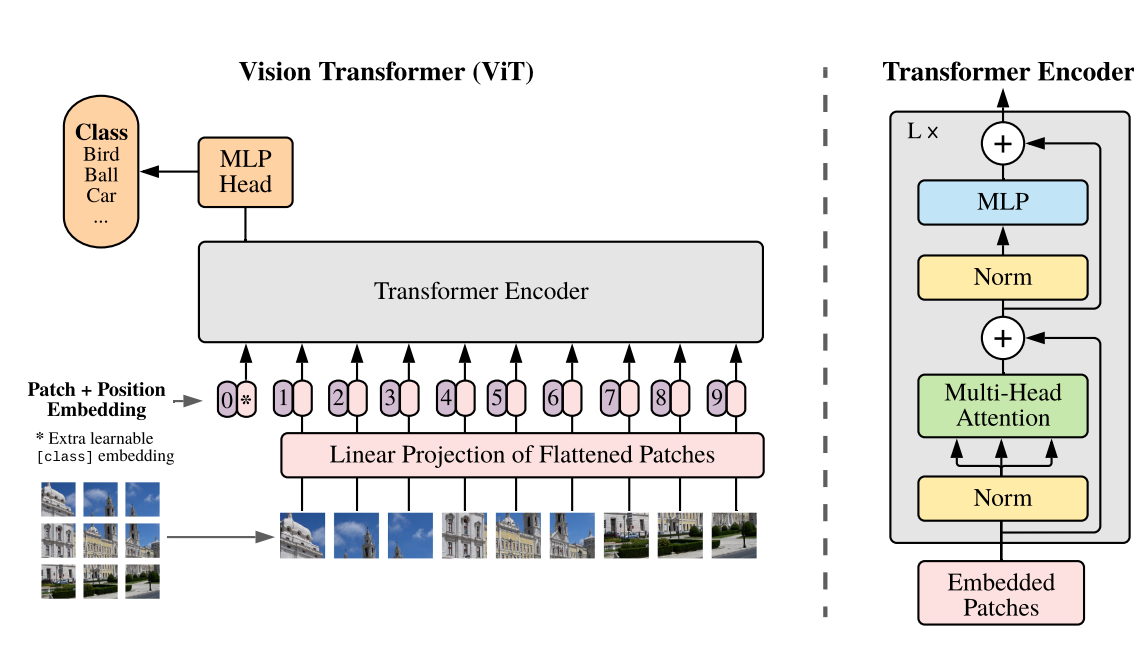
原论文地址:AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE 1 背景 Transformer在NLP领域取得了很好的效果,并成为许多NLP任务中的最新方法。但是在图像识别领域,自注意力机制在图像领域上的“Naive application”要求每个像…
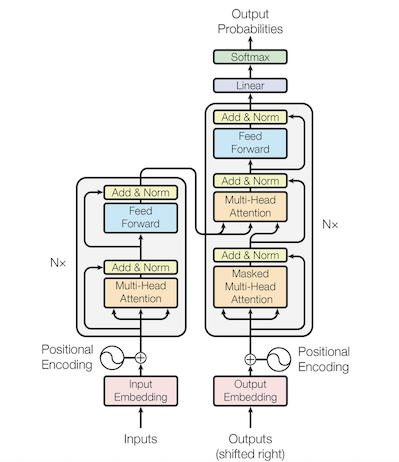
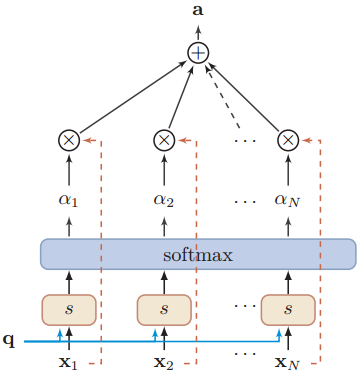
原论文链接:Attention Is All You Need 1 背景 在机器转录和语言建模上,RNN和CNN都有着广泛的应用。在RNN中,输入是按照顺序一个个输入进网络进行计算,encoder每个节点计算得到hidden state作为下一时刻的输入,decoder也是如此,一个词一个词往外蹦,但是这种模型无法进行并行化计算,并且当序列比较长的…