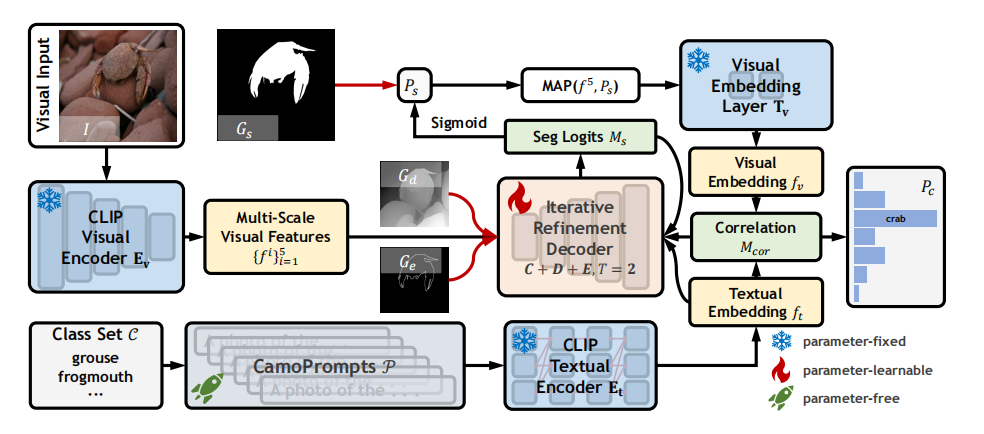
论文链接:Open-Vocabulary Camouflaged Object Segmentation 1 introduction 现在的伪装目标检测主要集中在预定义的封闭集场景上,其中所有的语义概念都在推理和训练阶段被看到,但是这过度简化了真实世界的复杂性,因此,作者提出了一个新的方向,开放词汇环境下的伪装目标检测,Open-Vocabula…
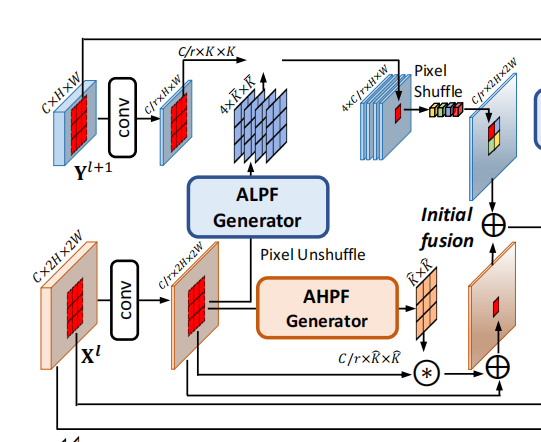
论文地址:Frequency-aware Feature Fusion for Dense Image Prediction 1 introduction 先说论文中几个名词: intra-category & inter-category similarity:会计算给定图片每个类的一个category center,就是某个类所有fea…
论文链接:Strategic Preys Make Acute Predators: Enhancing Camouflaged Object Detectors by Generating Camouflaged Objects 1 Introduction 本文以捕食者和被捕食者相互竞争的角度去提升COD任务的检测效果。首先在被捕食者方,使用了…
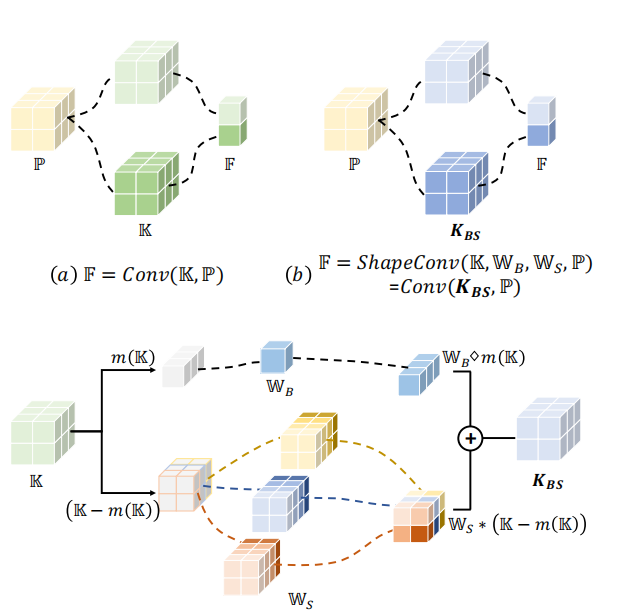
论文链接:ShapeConv: Shape-aware Convolutional Layer for Indoor RGB-D Semantic Segmentation 1 Why ShapeConv for RGB-D tasks 深度图包含物体的基础形状(局部信息,local geometry)和物体的位置(全局信息,在更大的contex…
论文地址:Spider: A Unified Framework for Context-dependent Concept Segmentation 1 Introduction 首先说一下Context Dependent(CD)和Context Independent(CI) 在自然语言处理中,上下文无关概念是指那些在不同上下文中其含义基本不…
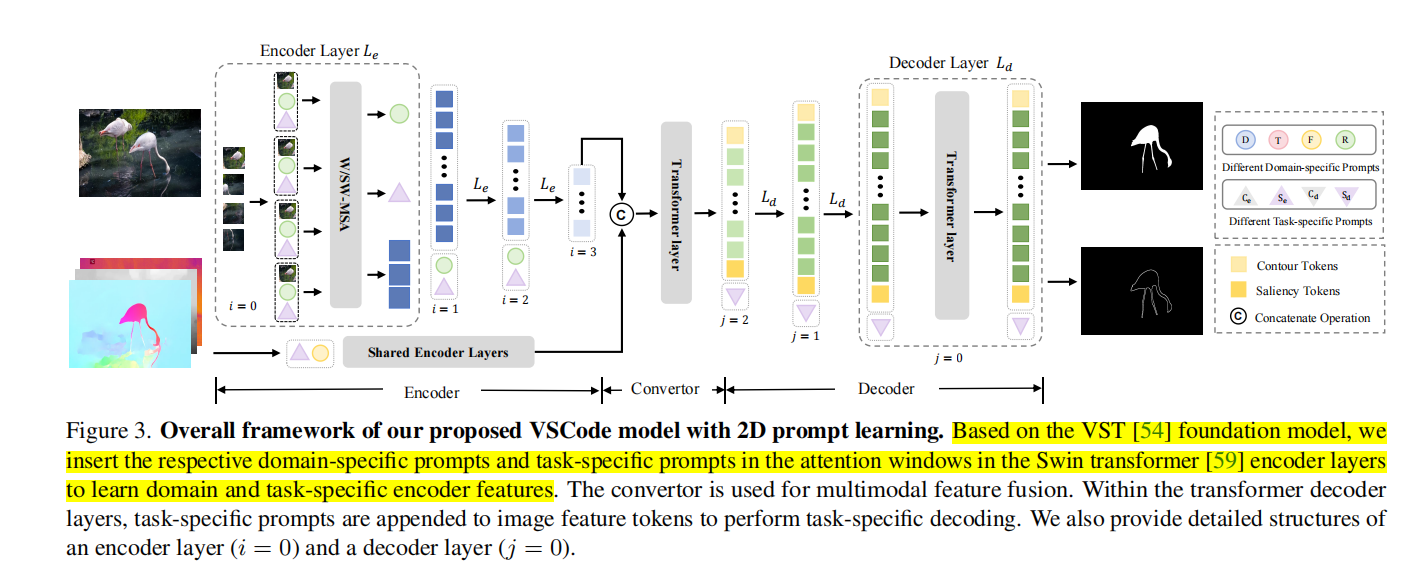
1 Introduction 现在的SOD和COD方法,都是为特定任务训练的模型,比如说深度图、热力图等,这个模型只适用于某种特定的数据集,这种方式不利与泛化,这个模型只能处理单一模式的数据,如果给别的类型的数据,则无法处理。并且,作者发现,不同的任务、不同模态的数据会共享一些相同点,并且有一些独特的线索,只要把这些共同点和独特的线索表示出来,就可…
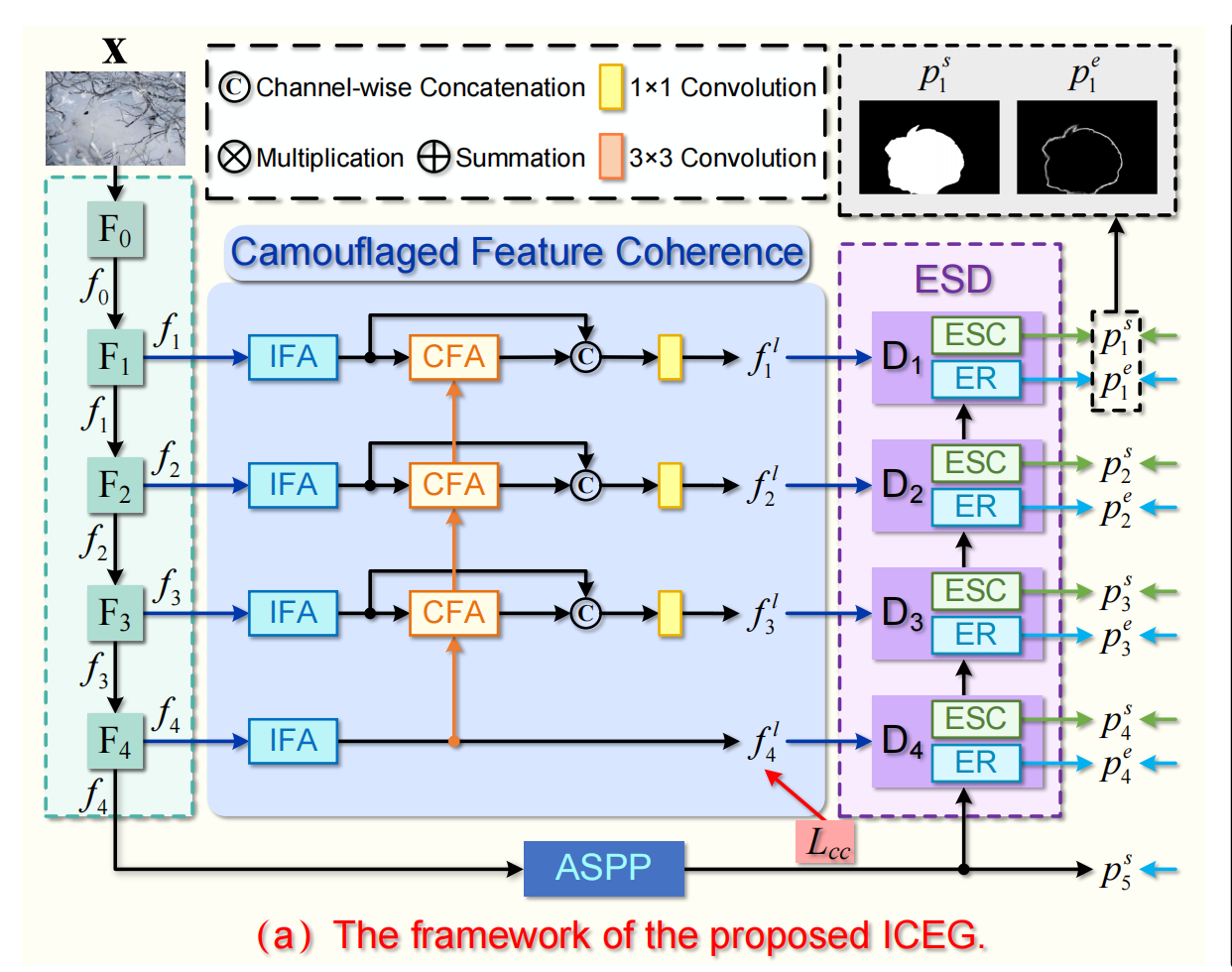
论文地址:Weakly-Supervised Camouflaged Object Detection with Scribble 1 Introduction 在这篇文章中,作者提出了第一个弱监督的COD模型,它仅使用简笔画(Scribble Annotations)作为监督。总体来说,作者设计了: LCC模块用来模拟人眼的视觉抑制,即抑制一些…
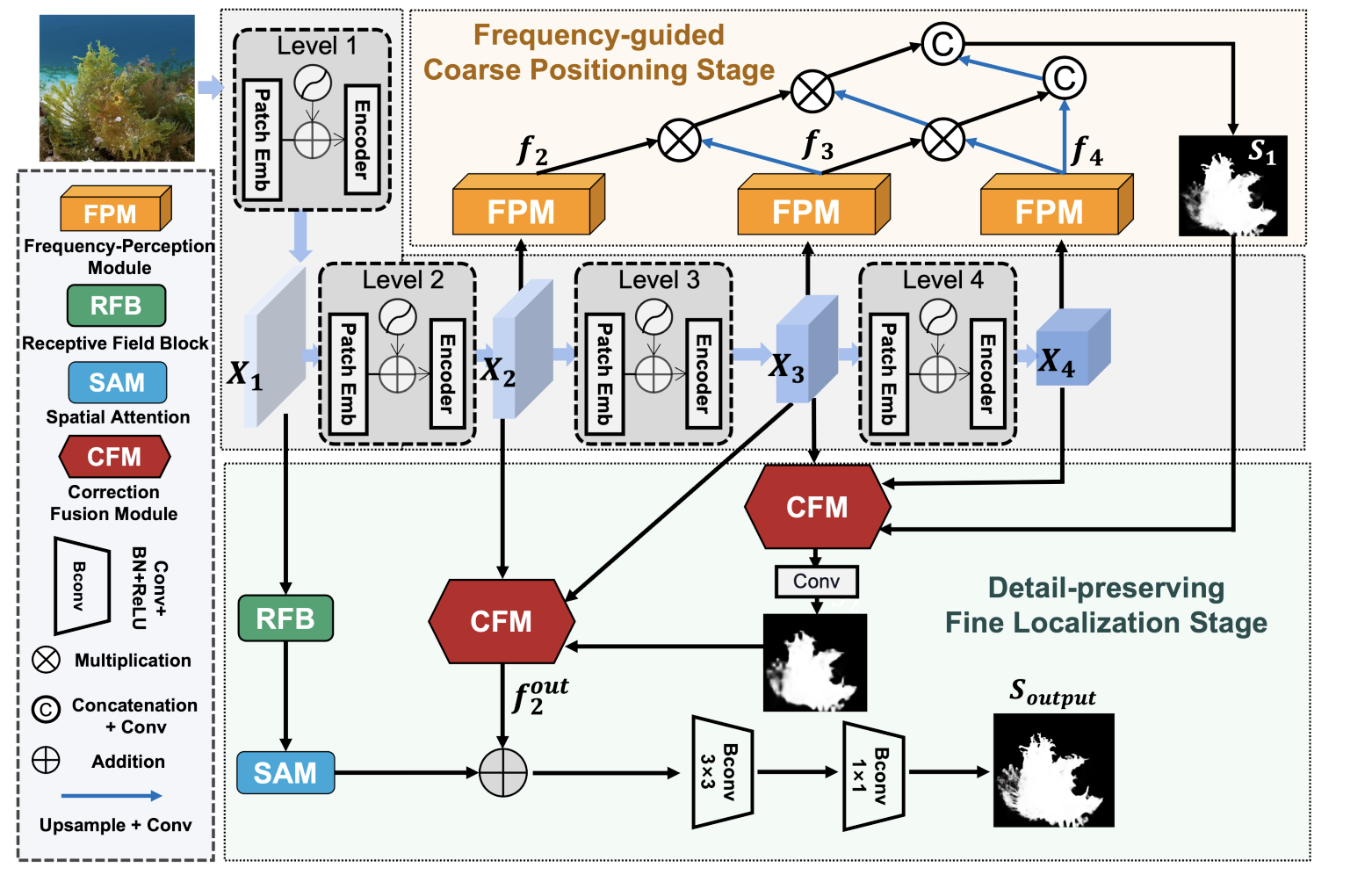
论文地址:Frequency Perception Network for Camouflaged Object Detection 1 Introduction 现在的方法大多在RGB域内进行伪装目标识别,通过纹理不一致性来初步发现伪装目标。在图像频率域里,高频通常描绘图片的细节,低频通常描绘图片的轮廓特征。作者在文章中提出了两阶段识别网络——F…
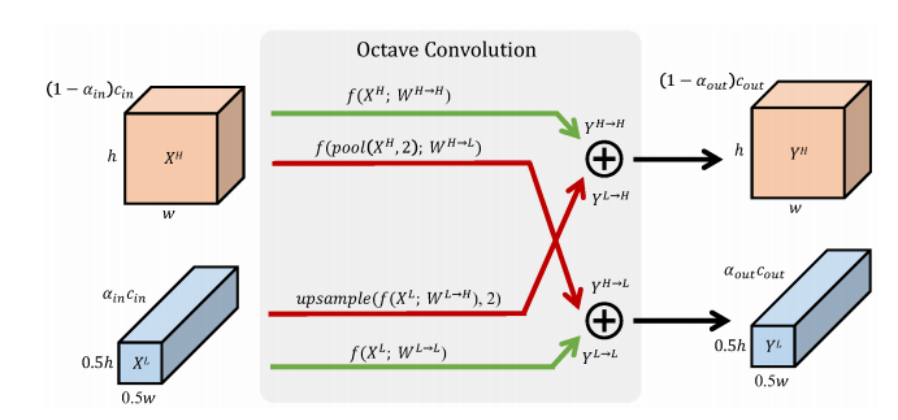
论文地址:Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution 1 Introduction 图片可以被分解为低空间频率和高空间频率的部分,它们分别描述缓慢变化的结构和剧烈变化的详细细节。作者认为卷积层…
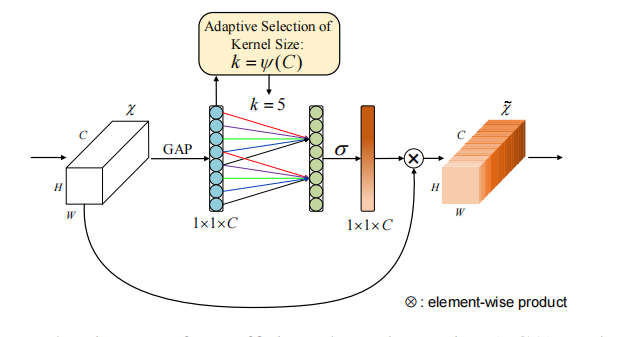
论文地址:ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks 1 Background ECA-Net是SENet的改进,SENet在计算C个通道的attention score的时候,使用的是单隐藏层的MLP: C->C/r->C,作者…