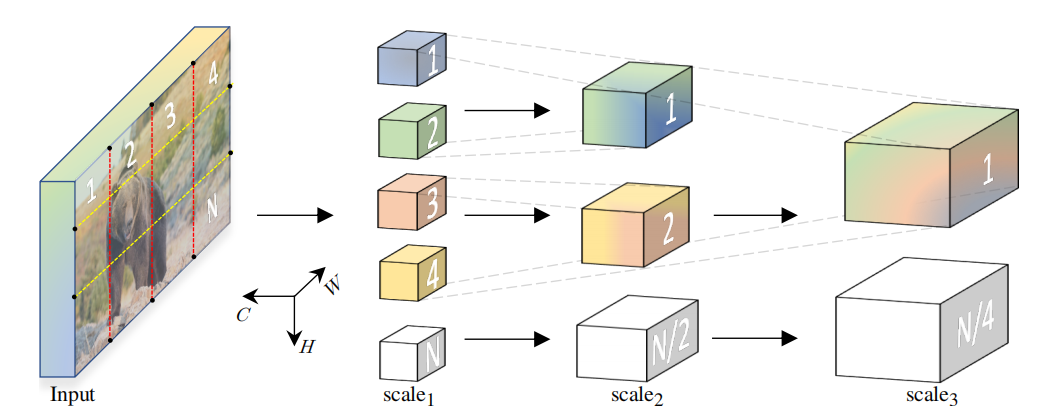
论文地址:Multiscale Vision Transformer CVPR2021 1 introduction 在视觉领域,特征金字塔结构是一种常用的结构,即随着网络的加深,特征图的分辨率越来越小,但是特征图的深度,即channel数,越来越多。高空间分辨率的特征图具有low-level的细节信息,低分辨率的深层特征图具有high-leve…
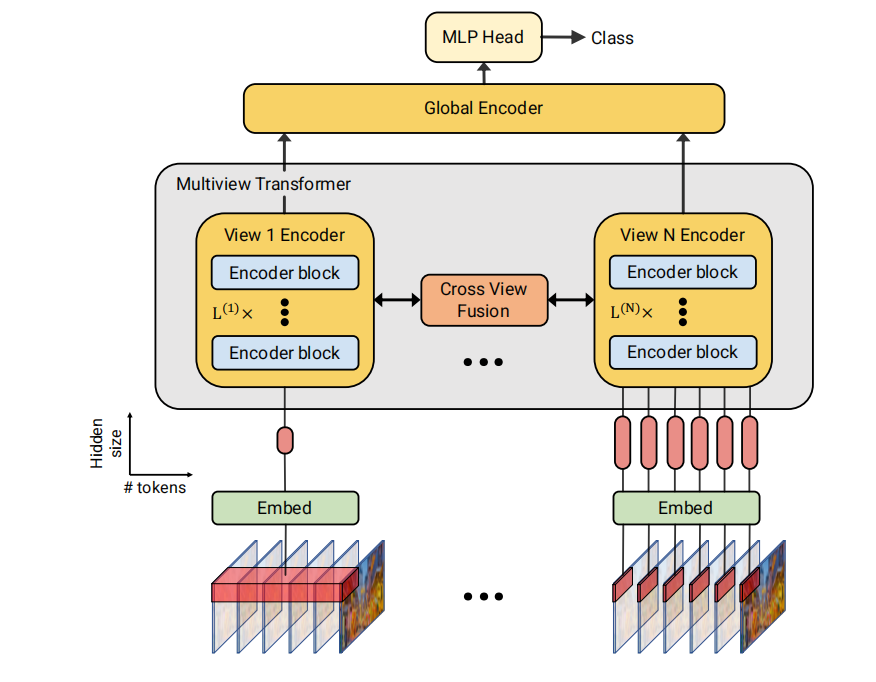
论文地址:Multiview Transformers for Video Recognition CVPR2022 文章是基于ViViT进行改造的 1 研究背景 在图像领域,多尺度处理通过金字塔结构实现。为了视频中的时间多尺度,以前SlowFast是有了2个分支。但是使用一个金字塔结构时,时间空间信息会因为下采样会有一部分信息的丢失。比如Slo…
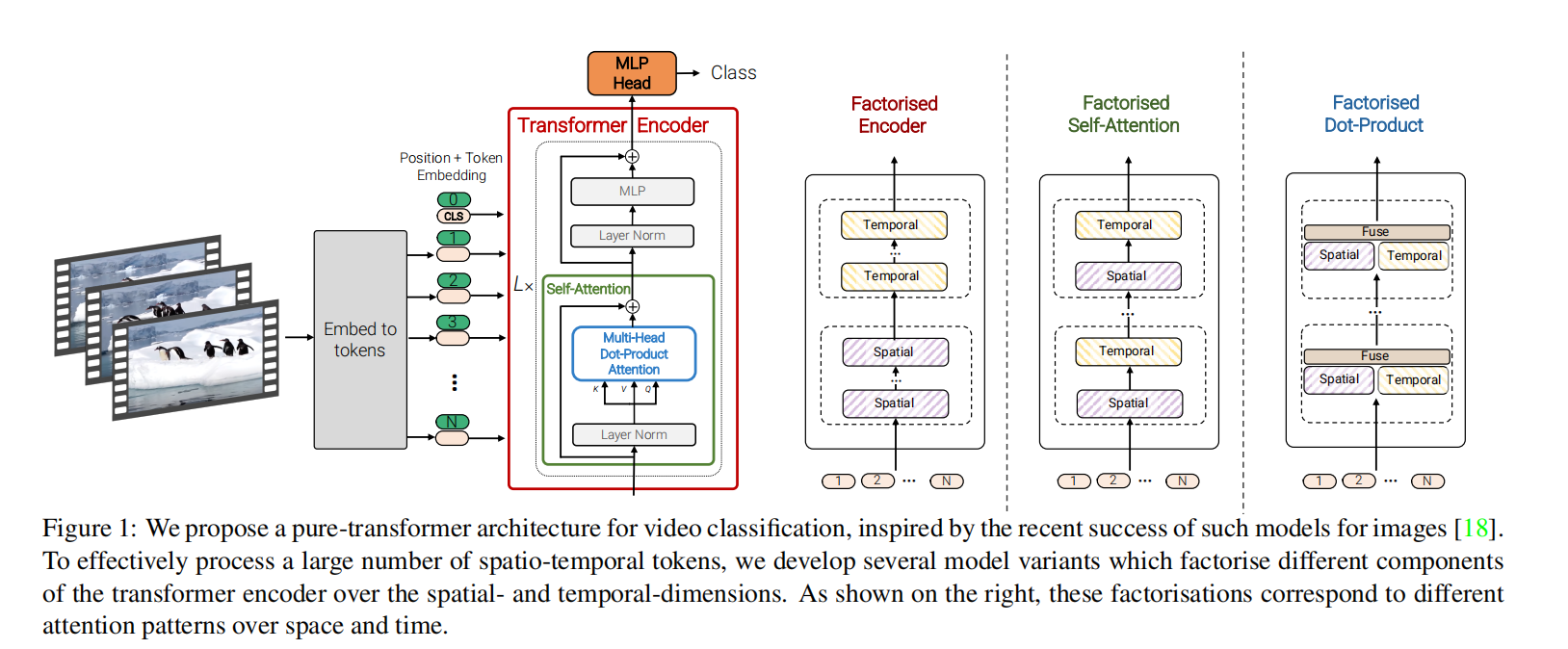
论文地址:ViViT: A Video Vision Transformer 0 divided attention divided attention是ViViT的先验知识,它在Is Space-Time Attention All You Need for Video Understanding?这篇文章中提出,我们知道,视频区别于图片,除了空…