1 数据合成-Selective Tampering Synthesis
共包含copy-move、generation、erase三种篡改方式
- 提取bounding box内的text mask:
-
- 将box扩大到原本的1.5倍,确保box能完全框死整个字符(后续需要进行形态学操作和根据轮廓填充mask,如果不能完全框死,会导致效果不好)
- 对box进行clip,确保box没有超出图像边缘
- 图像灰度化
- 对box内区域进行canny运算,canny算法第一个阈值为100,第二个阈值为200,得到文字的轮廓
- 对轮廓进行膨胀
- 进行形态学闭运算,尽可能闭合文字的边缘
- 寻找图片中的所有闭合轮廓,如果轮廓形成的面积小于box面积的一半,则将其填充,得到mask
- (可选)使用adaptive binarized的图片,和刚刚第七步得到的mask做或运算,作为上述算法的补充,有一些浅色字体(红色、绿色等)会被canny漏掉,增强算法鲁棒性。
- (可选)继续对图片做闭运算
- copy-move:
- 使用OCR检测图片,得到每个字符的bounding box。
- 计算text mask:
- 只用canny算子计算文字的边缘
- 对于每一个字符,二值化每个字符bounding box内的区域,得到前景和背景,分别计算前景和背景的均值和方差。
- 随机选取一个bounding box(target),寻找和其具有相近前景背景均值和方差,且字符类型(数字、汉子、英文字母等)相同的bounding box(source)
- 两种篡改方式:
- 将source框resize到target大小,整个粘贴到target区域,标注mask为矩形框
- 将source框中text mask的部分取出,将target区域内的text mask区域inpaint,最后把source框中text mask的部分粘贴到target框区域中,标注的mask为两个text mask的并集
- 对周围区域进行一些模糊,提升视觉一致性。
- generation:
- 将target区域内的text mask区域inpaint
- 随机选取一个和target区域内相同类型的字符,print到框内
- erase:
- 将target区域内的text mask区域inpaint。
2 Document Tampering Detector
双流频域-RGB模型
2.1 Frequency Perception Head
JPEG在压缩的时候是基于8✖️8的小块进行压缩的,对于每个小块进行DCT变换,并量化。因此会呈现出一块块的现象,成为块状伪影(Block Artifact Grids,BAG),因为整张图是有同样的压缩历史和量化表,所以每一块的DCT系数的分布情况应该相近,如果某个区域是从别处粘贴过来或者经过擦除/修改,新生成的像素没有经过压缩或者压缩历史和其他区域不同,那篡改区域的DCT分布情况和其他区域就不同,产生不连续性,利用这种特性,可以在频域上检测篡改区域。
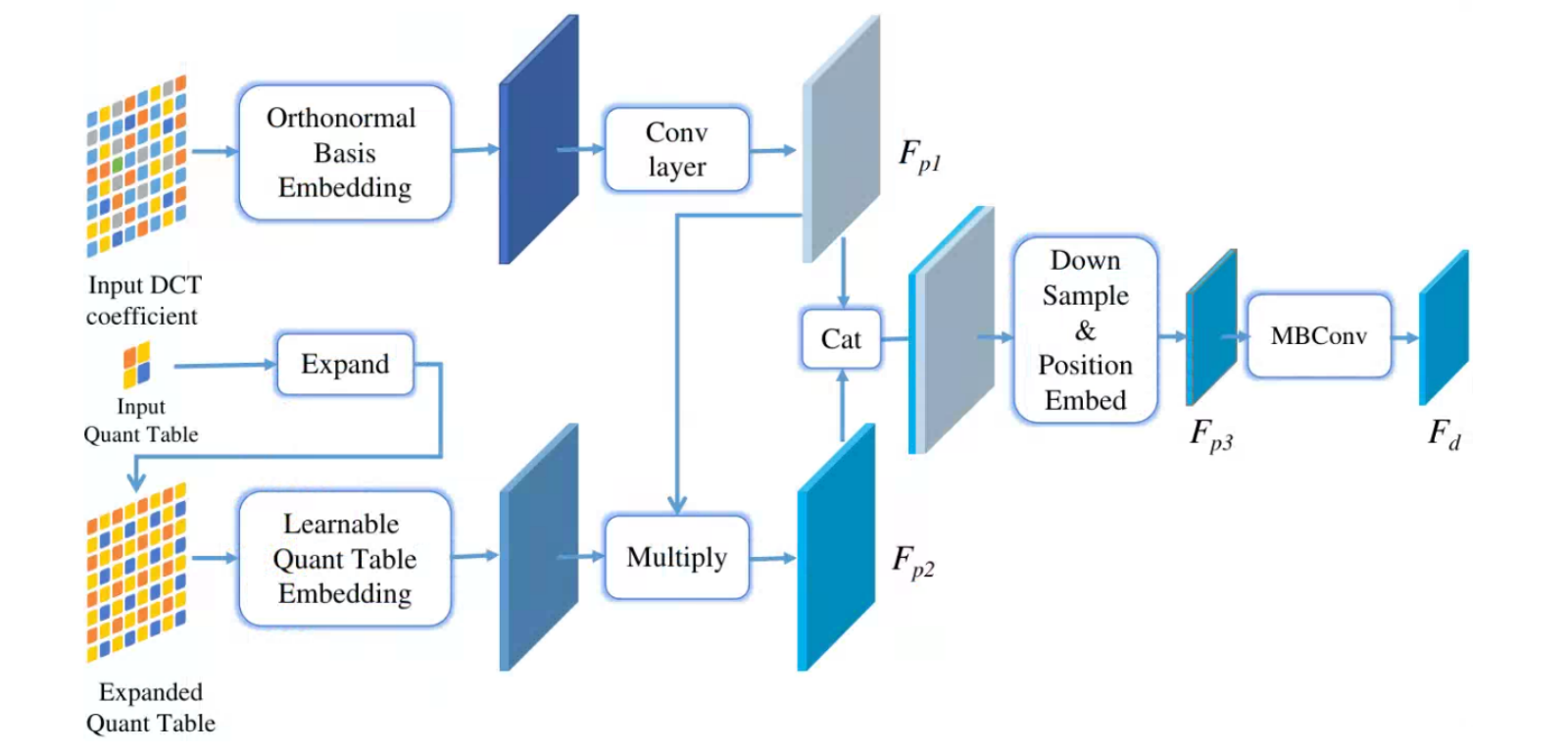
- 将RGB图片转换为YCbCr的形式,计算Y通道的DCT系数矩阵。
- 将DCT系数取绝对值,并clip到20以内,选取20个正交基表示DCT系数,然后卷积。
- 将量化表(q table)复制若干份,构成和原图大小一致的矩阵,经过learnable embedding层之后,和经过正交表时的DCT系数相乘,模拟还原原始DCT系数的过程。
- 将原始DCT系数和正交表示的DCT系数concat,然后8倍下采样,这样一个像素就可以代表DCT系数矩阵中的8✖️8的块。
作者用20个正交基表示DCT系数,我自己分析的原因是:
- DCT系数值是没有上下界的,很大的负数或者很大的正数都能取到,这样会让神经网络很难学习,一个非常简单的想法就是normalize到(-1,1),我们本质上是想通过DCT系数去找有没有区域和其他区域有明显的DCT系数分布情况不同,但是把dct系数压缩到(-1,1),表示能力欠佳,会压缩掉数值的区分能力,特别是中等值和极大值之间的差异可能被“抹平。比如:1,10,1000,归一化之后变为0.01,0.1,1.0,差异明显缩小。
- 并且使用归一化,相当于一个连续空间映射,模型容易把数值差异当成线性关系去学习,但篡改检测更关心分布形态 而不是具体数值,比如: 0 和 1 的差异,在篡改检测中可能比 19 和 20 更重要,归一化之后,网络可能会认为0,1与19,20的差异同样重要甚至不如;而用 one-hot 可以更公平地对待每个可能的系数。用正交基表示,由于正交的关系,1的基其实和20的基的距离与1与2的距离是一样的,不会存在压缩的状态,在初始的时候公平对待他们;然后在训练时,如果训练数据里表现出“低频小系数差异更敏感”,网络就能学到在 0/1 附近给出更大的权重;如果“高频大系数差异不那么重要”,它也能学到在 19/20 附近弱化差异。
- 因此把DCT系数用离散的21个正交基表示,这样会让不同8乘8块的DCT分布的区分能力变强。用 21 个正交基,本质上是把系数“离散化成 21 个状态”,转化为一个小规模分类问题。分类空间比回归空间更容易被卷积或注意力捕捉规律,也更适合“找分布差异”。当然,用更多的正交基会带来更强的表征能力。
2.2 课程学习-Curriculum Learning
在训练模型时,先学习简单数据再学习困难数据,会提升训练效果。
在实际操作中,每一步随机从\((B_1,100)\)选取压缩质量,\(B_1\)是从\(100-S/T, 100\)动态选取,S是目前training steps,T是预先设定好的常数。通过这种方式,模型在训练初期更容易接触到没经过压缩的简单图片。
3 text center border probability (TCBP)
由于篡改区域都往往很小,篡改区域平均占整张图片1%,会导致模型更偏向于认为图片没经过篡改,表现为模型在预测时过于谨慎导致漏召,为了解决这个问题,采用TCBP这种区域概率建模的方法,去建立软标签。
method:
- 篡改区域标注不变,仍为1。
- 从篡改区域往外扩散,用距离变换得到每个像素到最近正样本(篡改中心)的距离,然后按距离区间映射到不同概率值(0.7、0.5、0.2、0)。
优势:
-
让模型学习到“篡改区域有一个中心—边界的不确定性过渡”,避免过拟合在边缘噪声,因为我们最终业务落地要做一个分类任务,并不要求准确分割,因此只要模型能够找到分割位置大概在哪里即可,因此将mask相较于篡改区域放大一些,是有利于业务的。
-
边界周围赋中等概率(0.7、0.5 等),表示不确定性,鼓励模型在边界“宽容”一点,减少漏检。
4 在线困难样本挖掘-Online Hard Example Mining
正负样本极度不平衡:背景像素/区域 >> 前景像素/区域。绝大多数样本都非常容易分类(easy examples),对 loss 的贡献很小。因此要不要均等地训练所有样本,而是挑选出“最难”的部分样本来反向传播。
具体来说,对于正样本(篡改),计算其所有像素的损失,对于负样本,排序他们所有BCE loss的值,并选取topk = 3 ✖️ 正样本数量。因此,经过OHEM的BCE loss为:
\[L_{BCE}=\frac{\sum_{i=1}^{N_{pos}}l_{i^{pos}}^{CE}+\sum_{i=1}^{k}l_{i^{neg}}^{CE}}{N_{pos}+k}\]
\(N_{pos}\)为正样本数量。
BCE loss也是可以用于TCBP构成的soft target的。
5 Loss计算
dice loss
dice系数:
\[\mathrm{Dice}(p,g)=\frac{2\sum_i(p_ig_i)}{\sum_ip_i+\sum_ig_i}\]
p,g 分别为prediction和gt
dice loss:
\[\mathrm{Loss}=1-\mathrm{Dice}(p,g)\]
从公式可以看出,Dice Loss 专注于重叠部分,大面积背景对于Dice loss没有贡献,类别严重不均匀时很有用。但是对背景判别的约束不足,所以实际训练时经常会 Dice Loss + BCE Loss 一起用。因此最终的loss为BCE+Dice:
\[L_{DiceBCE}=\alpha L_{Dice}+(1-\alpha)L_{BCE}\]