原论文地址:AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
1 背景
Transformer在NLP领域取得了很好的效果,并成为许多NLP任务中的最新方法。但是在图像识别领域,自注意力机制在图像领域上的“Naive application”要求每个像素关注每个其他像素。也有研究人员提出每个查询像素只在局部社区进行自我关注,而不是全局关注。许多这些专门的注意架构在计算机视觉任务上显示出了有希望的结果,但需要复杂的工程才能在硬件加速器上有效地实现。
2 模型结构
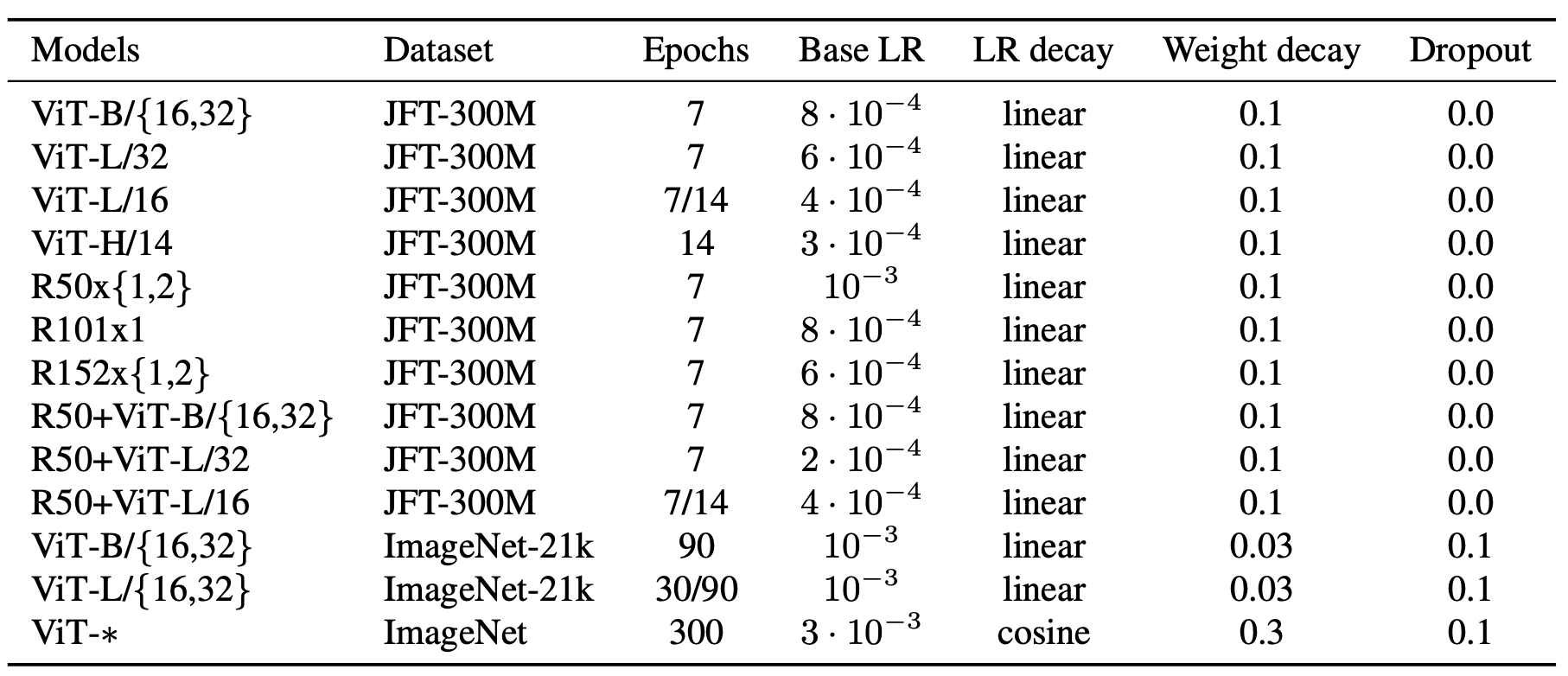
下图是原论文中给出的关于Vision Transformer(ViT)的模型框架。简单而言,模型由三个模块组成:
- Linear Projection of Flattened Patches(Embedding层)
- Transformer Encoder(图右侧有给出更加详细的结构)
- MLP Head(最终用于分类的层结构)
2.1 Embedding
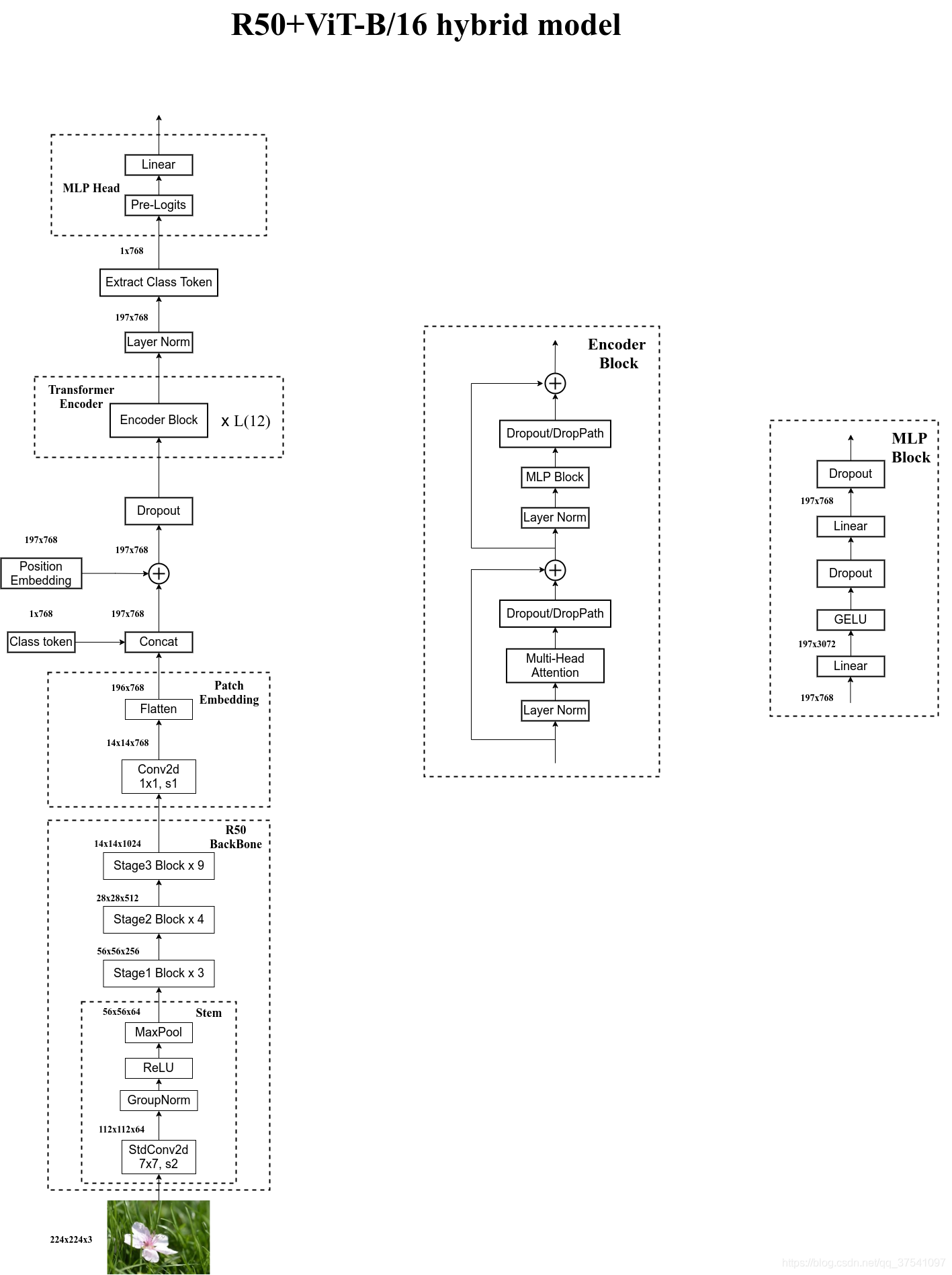
类比于NLP任务,整张图片相当于一个句子,每张图片被分割为若干个patch,每个patch相当于句子中的一个单词。现在要做的就是把三维的patch flatten为一个一维的embedding向量。假设维度是token_dim,也就是说,整张图片会被投影到[num_token, token_dim]的一个二维空间,现在需要搞清楚,num_token和token_dim的值是怎么得到的。
假设每个patch大小是16×16×3,原图大小是224×224×3,一张图就会被分成(224×224)/(16×16)=196个patches。相当于由196个单词,得到了num_token,现在来研究token_dim。我们把每一个16×16×3的patch通过线性映射映射到一维向量中,每个Patch数据shape为[16, 16, 3]通过映射得到一个长度为768的向量([16, 16, 3] -> [768]),如此我们就得到了[num_token, token_dim]=[196, 768]的Embeddings。
在代码实现中,直接通过一个卷积层来实现。 以ViT-B/16为例,直接使用一个卷积核大小为16×16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,正是Transformer想要的。
在代码实现中,直接通过一个卷积层来实现。 以ViT-B/16为例,直接使用一个卷积核大小为16×16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,正是Transformer想要的。
如何更加深入理解上述操作?我们单独把每一个patch拿出来看,每一个patch大小为16✖️16✖️3,每一个卷积核大小为16✖️16✖️3,共有768个这样的卷积核。每个卷积核在和patch(两者size是相同的)进行计算时,对应元素依次相乘然后求和(卷积核相当于一个连接权重),也就是把16✖️16✖️3这768个值聚合为一个值,由于有768个卷积核,所以这种操作重复798次,会得到一个1✖️768的一维向量。所以说,768个卷积核可以看成一个768✖️768的矩阵,把patch看成一个1✖️768的一个一维矩阵,卷积操作就相当于把768✖️768矩阵和1✖️768patch矩阵相乘,也就是上文所加粗的线性映射,最后得到一个1✖️768的矩阵,代表一个token。
我们对每一个patch都做上述操作,一共有196个patch,也就会得到[196, 768]的Embeddings。
在输入Transformer Encoder之前注意需要加上[class]token,也就是图上的”*”,以及Position Embedding。 在原论文中,作者说参考BERT,在刚刚得到的一堆tokens中插入一个专门用于分类的[class]token,这个[class]token是一个可训练的参数,数据格式和其他token一样都是一个向量,以ViT-B/16为例,就是一个长度为768的向量,与之前从图片中生成的tokens拼接在一起,Cat([1, 768], [196, 768]) -> [197, 768]。然后关于Position Embedding就是之前Transformer中讲到的Positional Encoding,这里的Position Embedding采用的是一个可训练的参数(1D Pos. Emb.),是直接叠加在tokens上的(add),所以shape要一样。以ViT-B/16为例,刚刚拼接[class]token后shape是[197, 768],那么这里的Position Embedding的shape也是[197, 768]。
这里部分引用了文章Vision Transformer详解
2.2 Transformer Encoder
Transformer Encoder其实就是重复堆叠Encoder Block L次。
其中,MLP Block,如图右侧所示,就是全连接+GELU激活函数+Dropout组成也非常简单,需要注意的是第一个全连接层会把输入节点个数翻4倍[197, 768] -> [197, 3072],第二个全连接层会还原回原节点个数[197, 3072] -> [197, 768]
Enocer Block中的Multi-head Attention这里就不再赘述,请见我之前的文章Attention Is All You Need(Transformer)
2.3 MLP Head
这一部分起到的是分类部分。我们知道,Transformer的输入和输出的shape是一样的,也就是说,输入时[197, 768],输出也是[197, 768],我们的任务是分类任务,所以我们只需要提取出来token[class]这一Query产生的结果即可,即[197, 768]中抽取出[class]token对应的[1, 768]。接着我们通过MLP Head得到我们最终的分类结果。MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者你自己的数据上时,只用一个Linear即可,然后经过softmax层得到scores
3 Experiment
作者做了三种模型的比较,分别为ResNet(Baseline CNNs)、ViT、Hybrid。
- ResNet:用Group Normalization替代Batch Normalization;使用standardized convolutions
- ViT:分为Base、Large、Huge三个size

- Hybrid:就是把ResNet的side-output输入给ViT。在原Resnet50网络中,stage1重复堆叠3次,stage2重复堆叠4次,stage3重复堆叠6次,stage4重复堆叠3次,但在这里的R50中,把stage4中的3个Block移至stage3中,所以stage3中共重复堆叠9次。通过R50 Backbone进行特征提取后,得到的特征矩阵shape是[14, 14, 1024],接着再输入Patch Embedding层,注意Patch Embedding中卷积层Conv2d的kernel_size和stride都变成了1,只是用来调整channel。后面的部分和前面ViT中讲的完全一样,就不在赘述。
实验结果
下表是论文用来对比ViT,Resnet(和刚刚讲的一样,使用的卷积层和Norm层都进行了修改)以及Hybrid模型的效果。通过对比发现,在训练epoch较少时Hybrid优于ViT,但当epoch增大后ViT优于Hybrid。