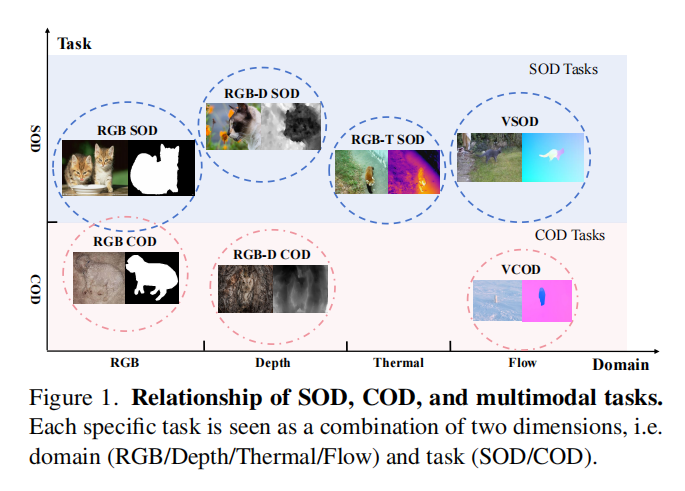
1 Introduction
现在的SOD和COD方法,都是为特定任务训练的模型,比如说深度图、热力图等,这个模型只适用于某种特定的数据集,这种方式不利与泛化,这个模型只能处理单一模式的数据,如果给别的类型的数据,则无法处理。并且,作者发现,不同的任务、不同模态的数据会共享一些相同点,并且有一些独特的线索,只要把这些共同点和独特的线索表示出来,就可以用一个模型实现多种任务、多种模态的识别任务。
2 Methodology
2.1 Foundation Model
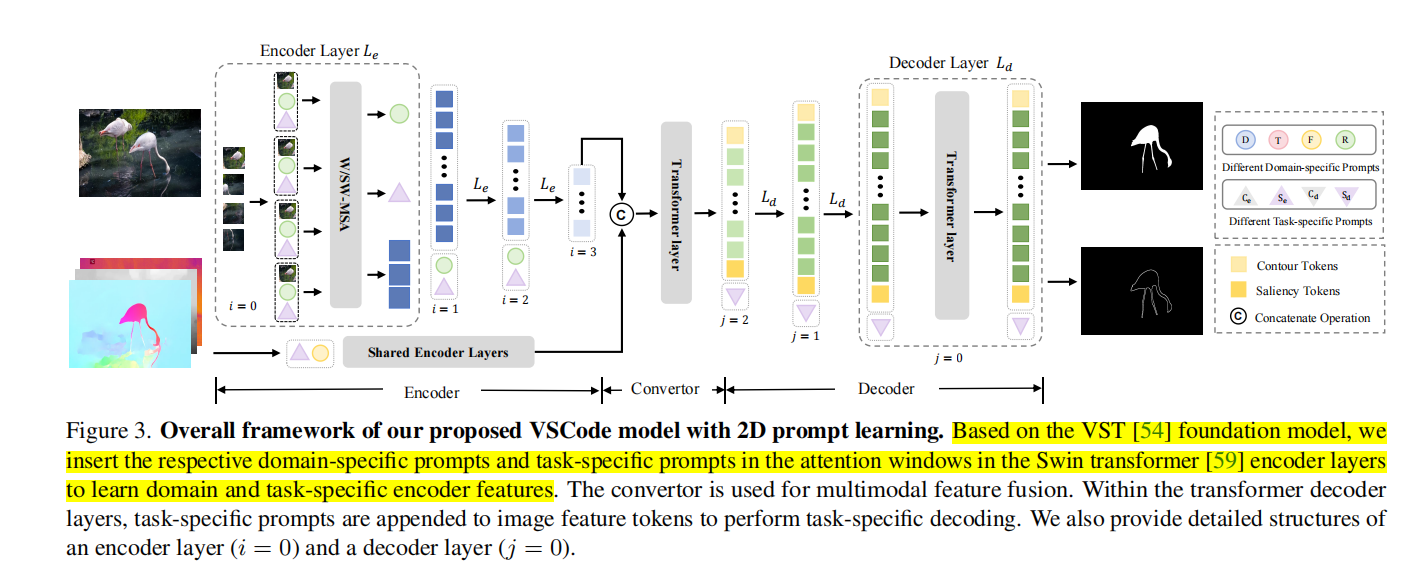
作者使用VST为基本网络的大框架,它由Encoder、Convertor(用于融合RGB特征和其他模态的特征)、Decoder组成。在这里,Encoder(backbone)使用swin-transformer,Convertor使用VST的RGB Convertor。对于多模态的任务,仅仅把RGB特征和深度特征做concat送进Convertor中。对于仅有RGB的任务,没有Convertor的转换。
2.2 Domain-specific Prompt
作者认为,在Encoder里,low-levelfeatures通常包含边缘、颜色和纹理等低级特征,这些特征可能在不同domain中表现出不同的特征,但是high-level features通常是高级语义信息,这些语义信息对所有任务都很关键。因此,作者引入domain-specific prompt,为每个domain:RGB、Depth、thermal、optical flow都设置它们专属的prompt向量。
对于某个swin-transformer encoder block的特征\(f_i^E\),用window-attention把特征分成\(f_{i\text{_}w}^E\in\mathbb{R}^{l_i/M^2\times M^2\times c_i} \),M是window大小,\(l_i/M^2\)是window的数量。然后为每个window复制\(\boldsymbol{p}_i^d\in\mathbb{R}^{N_i\times c_i}\),得到\(p_i^{d^{\prime}}\in\mathbb{R}^{l_i/M^2\times N_i\times c_i} \), 其中,\(N_{i}\)代表可学习的prompt的数量,然后,把他们每个append到每个window里,计算self-attention。
\[\begin{bmatrix}p_{i+1}^{{d^{\prime}}}\\f_{i_w}^{E}\end{bmatrix}\leftarrow\mathrm{MLP}(\text{SW/W-MSA}(\begin{bmatrix}\boldsymbol{p}_{i}^{{d^{\prime}}}\\\boldsymbol{f}_{i_w}^{E}\end{bmatrix})),\]
2.3 Task-specific Prompt
作者认为,SOD和COD任务会在特征图上有一些重要的共同点,比如说low-level cues,high-level objectness,spatial structuredness。作者引入task-specific prompt去学习特性,这样能学习特性的同时,还保留了主干网络参数能捕捉共同点的能力。作者在encoder和decoder中都加入了task-specific prompt

Encoder 来自encoder的高级语义特征通常会关注和任务有关的区域,从而分配更多的注意力,在SOD里,通常会强调前景,在COD里,通常会强调背景,因此需要prompts告诉encoder应该根据任务捕获任务所需要的特征。在endoer里引入prompts的方式类似于domain-specific prompt。
Decoder COD的识别可能会更棘手,因为它会隐匿于背景之中,因此只在encoder中引入prompt是不够的,因为伪装目标的识别需要一个refined process。在decoder中加入prompts比较简单,直接把\(\boldsymbol{p}_{j+1}^{td}\in\mathbb{R}^{N\times d}\) append到\(f_{j+1}^D\)
\[\begin{bmatrix}\boldsymbol{p}_j^{td}\\\boldsymbol{f}_j^D\end{bmatrix}\leftarrow\mathrm{MLP}(\mathrm{MSA}(\begin{bmatrix}\boldsymbol{p}_{j+1}^{td}\\\boldsymbol{f}_{j+1}^D\end{bmatrix})),\]
2.4 Loss Function: Prompt Discrimination Loss
模型的设计原则是,在整合共性的同时,使用二维提示来包含特性,但是学习到的提示是纠缠的,危及模型区分不同领域和任务的能力,并导致次优优化。于是用Prompt Discrimination Loss去最小化相同type(task/domain)的prompts的相关性,让每一类的prompts只学习到它所属的task或者domain的知识。
计算方式:首先对于每一个block里,将同一类的prompt进行average,然后linear;然后将四个block的prompt进行concat然后MLP,公式如下;
\[p_{l}^{d_{all}}=\mathrm{MLP}[\mathrm{LA}(\boldsymbol{p}_{0}^{d});\mathrm{LA}(\boldsymbol{p}_{1}^{d});\mathrm{LA}(\boldsymbol{p}_{2}^{d});\mathrm{LA}(\boldsymbol{p}_{3}^{d})],\\p_{k}^{te_{all}}=\mathrm{MLP}[\mathrm{LA}(\boldsymbol{p}_{0}^{te});\mathrm{LA}(\boldsymbol{p}_{1}^{te});\mathrm{LA}(\boldsymbol{p}_{2}^{te});\mathrm{LA}(\boldsymbol{p}_{3}^{te})],\]
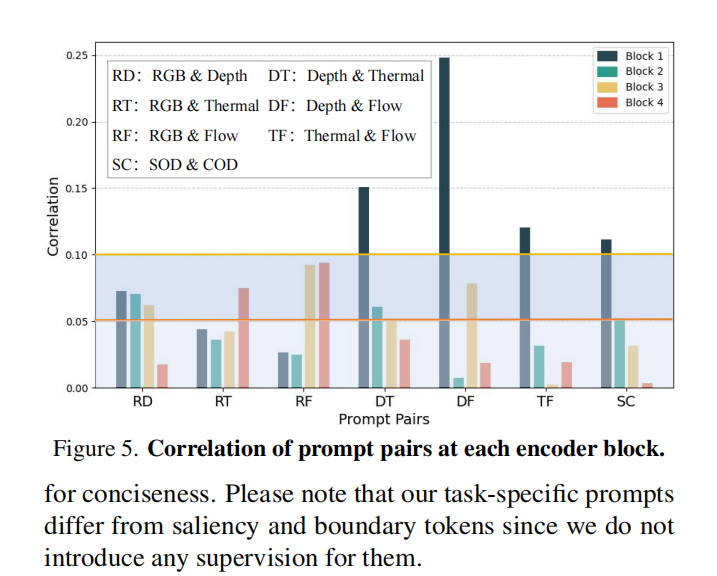
L和A分别是linear和Average,\(l \in \{depth,thermal,flow,rgb\}\),\(k\in\{SOD,COD\}\)。然后计算prompt pairs之间的余弦相似度\(\mathcal{CS}_{m}\),\(m\)代表\(\{RD,RT,RF,DF,DT,TF\}\),字母对的含义见图,Prompt Discrimination Loss计算公式如下:
\[\mathcal{L}_{dis}=\sum_m\ln(1+|\mathcal{CS}_m|),\]
2.5 模型运算方式详解
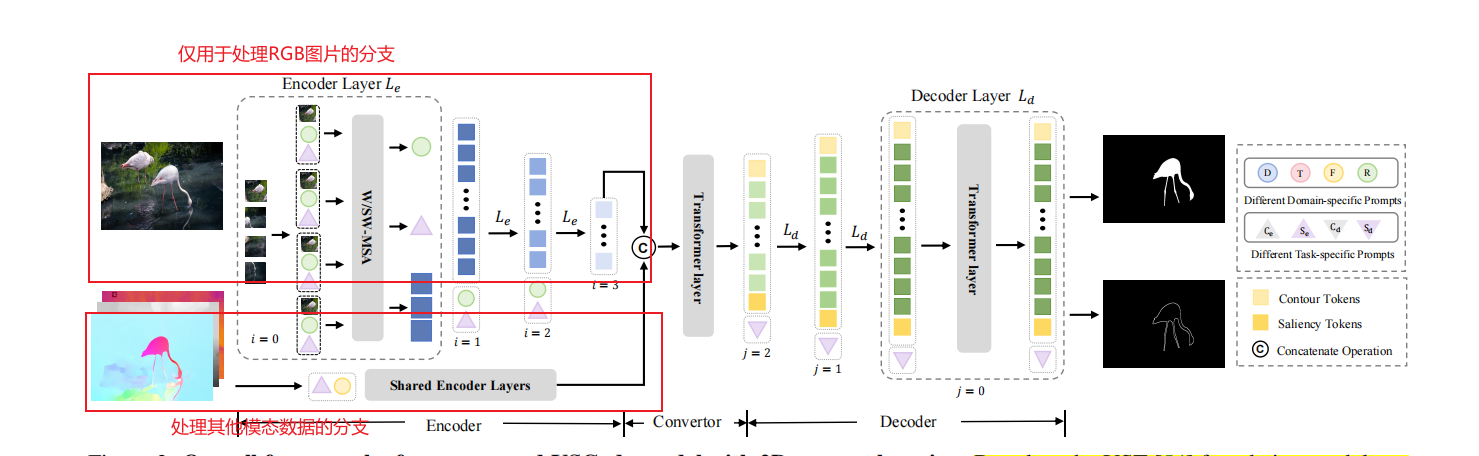
encoder有两个分支,是共享的,只是使用的prompts会根据domain和task而改变,上面的分支是RGB图像的分支,所有的任务都会用这个分支,并且这个分支的domain-specific prompts始终固定是RGB的prompts,task-specific prompts会根据COD和SOD而改变。如果有其他模态的数据,就会经过这个分支,domain-specific prompts是由模态类型所决定的,如果没有其他模态的数据,仅仅只有RGB图像,就不会有这个分支。这两个分支的结果经过concat送进Convertor。